AWS Big Data Blog
Load CDC data by table and shape using Amazon Kinesis Data Firehose Dynamic Partitioning
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
Amazon Kinesis Data Firehose is the easiest way to reliably load streaming data into data lakes, data stores, and analytics services. Customers already use Amazon Kinesis Data Firehose to ingest raw data from various data sources using direct API call or by integrating Kinesis Data Firehose with Amazon Kinesis Data Streams including “change data capture” (CDC) use case.
Customers typically use single Kinesis Data Stream per business domain to ingest CDC data. For example, related fact and dimension tables change data is sent to the same stream. Once the data is loaded to Amazon S3, customers use ETL tools to split the data by tables, shape, and desired partitions as the first step in the data enrichment process.
This post demonstrates how customers can use Amazon Kinesis Firehose Dynamic Partitioning to split the data by table, shape (by message schema/version), and by desired partitions on the fly to do this first step of data enrichment while ingesting data.
Solution Overview
In this post, we provide a working example of a CDC pipeline where fake customer, order, and transaction table data is pushed from the source and registered as tables to the AWS Glue Data Catalog. The following architecture diagram illustrates this overall flow. We are using AWS Lambda to generate test CDC data for this post. However, in the real world you would use AWS Data Migration Service (DMS) or a similar tool to push change data to the Amazon Kinesis Data Stream.

The workflow includes the following steps:
- An Amazon EventBridge event triggers an AWS Lambda function every minute.
- The Lambda function generates test transactions, customers and order CDC data, as well as sends the data to Amazon Kinesis Data Stream.
- Amazon Kinesis Data Firehose reads data from Amazon Kinesis Data Stream.
- Amazon Kinesis Data Firehose
- Applies Dynamic Partitioning configuration defined in the Firehose configuration
- Invokes AWS Lambda transform to derive custom Dynamic Partitioning.
- Amazon Kinesis Data Firehose saves data to Amazon Simple Storage Service (S3) bucket.
- The user runs queries on Amazon S3 bucket data using Amazon Athena, which internally uses the AWS Glue Data Catalog to supply meta data.
Deploying using AWS CloudFormation
You use CloudFormation templates to create all of the necessary resources for the data pipeline. This removes opportunities for manual error, increases efficiency, and ensures consistent configurations over time.
Steps to follow:
- Click here to Launch Stack:

- Acknowledge that the template may create AWS Identity and Access Management (IAM) resources.
- Choose Create stack.
This CloudFormation template takes about five minutes to complete and creates the following resources in your AWS account:
- An S3 bucket to store ingested data
- Lambda function to publish test data
- Kinesis Data Stream connected to Kinesis Data Firehose
- A Lambda function to compute custom dynamic partition for Kinesis Data Firehose transform
- AWS Glue Data Catalog tables and Athena named queries for you to query data processed by this example
Once the AWS CloudFormation stack creation is successful, you should be able to see data automatically arriving to Amazon S3 in about five more minutes.
Data sources input
The Lambda function automatically publishes four types of messages to the Kinesis Data Stream at regular intervals with random data when invoked in the following format. In this example, we use three tables:
- Customers: Has basic customer details.
- Orders: Mimics orders placed by customers on the shopping website or mobile app.
- Transactions: Mimics payment transaction done for the order. The transaction table showcases possible message schema evolution that can happen over time from message schema v1 to v2. It also shows how you can split messages by schema version if you don’t want to merge them into a universal schema.
Customer table sample message
Orders table sample message
Transactions in old message format (v1)
Transactions in new message format (v2 – latest)
This message example demonstrates message evolution over time. txid from old message format is now renamed to transactionId, and new information like source is added to the original old transaction message in the new message version v2.
Dynamic Partitioning Logic
Amazon Kinesis Data Firehose dynamic partitioning configuration is defined using jq style syntax. We will use the table field for the first partition and the version field for the second level partition. We can derive the table partition using dynamic partitioning jq syntax “.version”. As you can see, the version field is available in all of the messages. Therefore, we can use it directly in partitioning. However, the table field is not available for old and new transaction messages. Therefore, we derive the table field using custom transform Lambda function.
We check the existence of the table field from the incoming message and populate it with the static value “Transaction” if table field is not present. Lambda function also returns PartitionKeys for Kinesis Data Firehose to use as dynamic partition. The Lambda function also derives the year, month, and day from the current time.
The Kinesis Data Firehose S3 destination Prefix is set to table=!{partitionKeyFromLambda:table}/version=!{partitionKeyFromQuery:version}/year=!{partitionKeyFromLambda:year}/month=!{partitionKeyFromLambda:month}/day=!{partitionKeyFromLambda:day}/
- table partition key is coming from the Lambda function based on custom logic.
- version partition key is extracted using jq expression using Kinesis Data Firehose dynamic partition configuration. Here, the version refers to the shape of the message and not the version of the data. For example, Updates to Customer record with same ID is not merged into one.
- year, month, and day partition keys are coming from the Lambda function based on current time
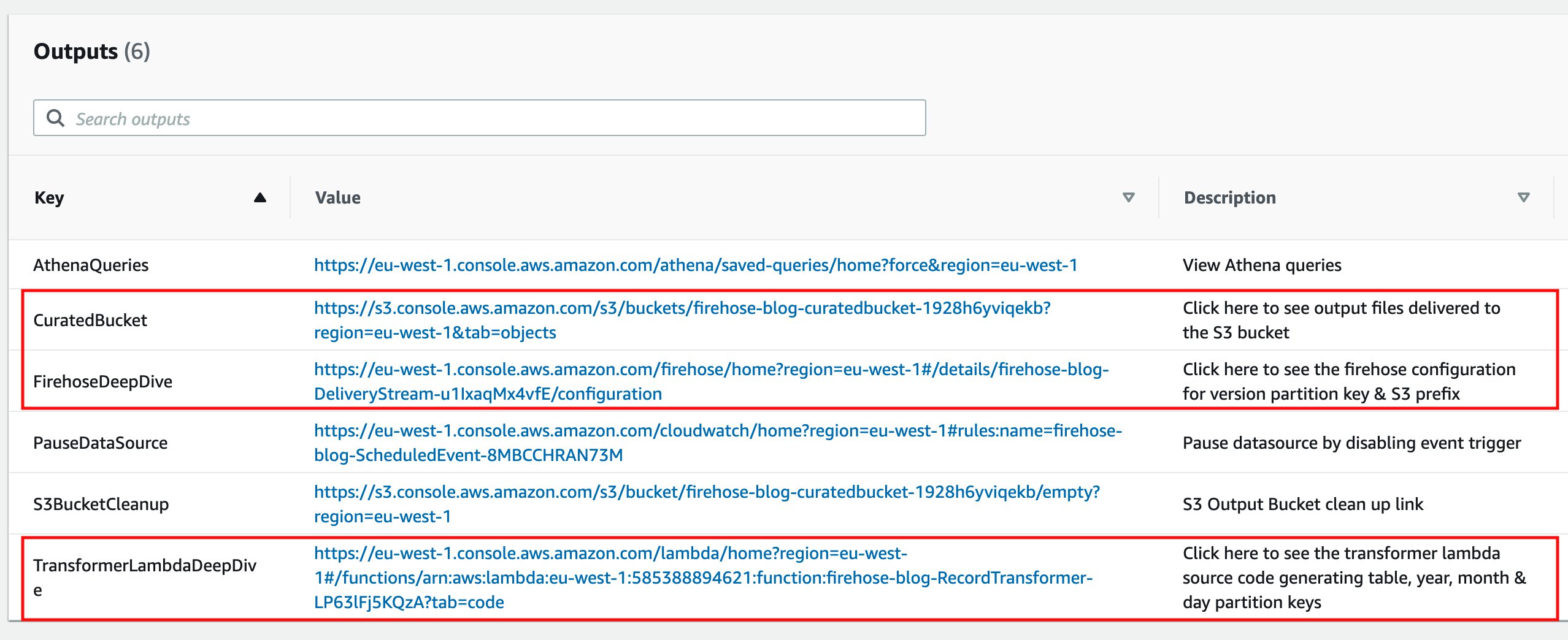
You can follow the respective links from the CloudFormation stack Output tab to deep dive into the Kinesis Data Firehose configuration, record transformer Lambda function source code, and see output files in the Amazon S3 curated bucket. The entire code is also available in the GitHub repository.
Ingested data output
Kinesis Data Firehose processes all the messages and outputs result in the following S3 hive style partitioned paths:


Query output data stored in Amazon S3
Kinesis Data Firehose loads new data every minute to the Amazon S3 bucket, and the associated tables are already created by CloudFormation for you in the AWS Glue Data Catalog. You can directly query Amazon S3 bucket data using the following steps:
- Go to Amazon Athena service and select the database with the same name as the CloudFormation stack name without dashes.
- Select the three dots next to each table name to open the table menu and select Load Partitions. This will add a new partition to the AWS Glue Data Catalog.

- Go to the CloudFormation stack Output tab.

- Select the link mentioned next to the key AthenaQueries.
- This will take you to the Amazon Athena saved query console. Type the word Blog to search named queries created by this blog.

- Select the query called “Blog – Query Customer Orders”. This will open the query in the Athena query console. Select Run query to see the results.

- Select the Saved queries menu from the top bar to go back to the Amazon Athena saved query console. Repeat the steps for other Blog queries to see results from the “new and old transactions” queries.
Clean up
Complete the following steps to delete your resources and stop incurring costs:
- Go to the CloudFormation stack Output tab.

- Select the link mentioned next to the key PauseDataSource. This will take you to the Amazon EventBridge event rules console.
- Select the Actions button from the top right menu bar and select Disable.
- Confirm the choice by clicking the Disable button again on the prompt. This will disable Amazon EventBridge event trigger that invokes the data generator Lambda function. This lets us make sure that no new data is sent to the Kinesis data stream by Lambda from now onward.
- Wait for at least two minutes for all of the buffered events to reach to the S3 from the Kinesis Data Firehose.
- Go back to the CloudFormation stack Output tab.
- Select the link mentioned next to the key S3BucketCleanup.
You’re redirected to the Amazon S3 console.
- Enter
permanently deleteto delete all of the objects in your S3 bucket. - Choose Empty.
- On the AWS CloudFormation console, select the stack you created and choose Delete.
Summary
This post demonstrates how to use the Kinesis Data Firehose Dynamic Partitioning feature to load CDC data on the fly in near real-time. It also shows how we can split CDC data by table and message schema version for backward compatibility and quick query capability. To learn more about dynamic partitioning, you can refer to this blog and this documentation. Provide us with any feedback you have about the new feature.
About the Author
 Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS Analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using the art of the possible technology. He enjoys beaches in his leisure time.
Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS Analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using the art of the possible technology. He enjoys beaches in his leisure time.