AWS Big Data Blog

Encrypt Data At-Rest and In-Flight on Amazon EMR with Security Configurations
ustomers running analytics, stream processing, machine learning, and ETL workloads on personally identifiable information, health information, and financial data have strict requirements for encryption of data at-rest and in-transit. The Apache Spark and Hadoop ecosystems lend themselves to these big data use cases, and customers have asked us to provide a quick and easy way to encrypt data at-rest and data in-transit between nodes in each execution framework.

Real-time Clickstream Anomaly Detection with Amazon Kinesis Analytics
In this post, I show an analytics pipeline which detects anomalies in real time for a web traffic stream, using the RANDOM_CUT_FOREST function available in Amazon Kinesis Analytics.

Writing SQL on Streaming Data with Amazon Kinesis Analytics – Part 2
This post introduces you to the different types of windows supported by Amazon Kinesis Analytics, the importance of time as it relates to stream data processing, and best practices for sending your SQL results to a configured destination.

Month in Review: August 2016
Another month of big data solutions on the Big Data Blog. Take a look at our summaries below and learn, comment, and share. Thanks for reading! Readmission Prediction Through Patient Risk Stratification Using Amazon Machine Learning With this post, learn how to apply advanced analytics concepts like pattern analysis and machine learning to do risk […]
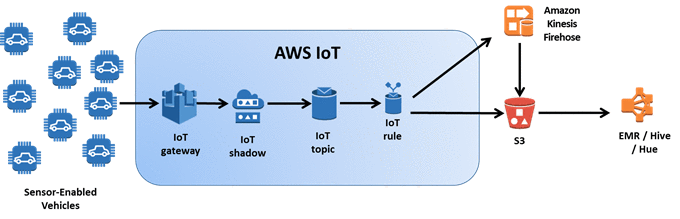
Integrating IoT Events into Your Analytic Platform
AWS IoT makes it easy to integrate and control your devices from other AWS services for even more powerful IoT applications. In particular, IoT provides tight integration with AWS Lambda, Amazon Kinesis, Amazon S3, Amazon Machine Learning, Amazon DynamoDB, Amazon CloudWatch, and Amazon OpenSearch Service.

Processing VPC Flow Logs with Amazon EMR
In this post, I show you how to gain valuable insight into your network by using Amazon EMR and Amazon VPC Flow Logs. The walkthrough implements a pattern often found in network equipment called ‘Top Talkers’, an ordered list of the heaviest network users, but the model can also be used for many other types of network analysis.
Seattle AWS Big Data Meetup: Building Smart Healthcare Applications on AWS
Please join us at the upcoming Seattle AWS Big Data Meetup on Wednesday, August 31. The topic is “Building Smart Healthcare Apps on AWS,” with a spotlight on machine learning. Join now and get details on the Meetup page Lisa McFerrin, PhD, Bioinformatics is a Project Manager for Seattle Translational Tumor Research at Fred Hutchinson […]

Monitor Your Application for Processing DynamoDB Streams
In this post, I suggest ways you can monitor the Amazon Kinesis Client Library (KCL) application you use to process DynamoDB Streams to quickly track and resolve issues or failures so you can avoid losing data. Dashboards, metrics, and application logs all play a part. This post may be most relevant to Java applications running on Amazon EC2 instances.
Writing SQL on Streaming Data with Amazon Kinesis Analytics – Part 1
This post introduces you to Amazon Kinesis Analytics, the fundamentals of writing ANSI-Standard SQL over streaming data, and works through a simple example application that continuously generates metrics over time windows.

Building and Deploying Custom Applications with Apache Bigtop and Amazon EMR
This post shows you how to build a custom application for EMR for Apache Bigtop-based releases 4.x and greater. EMR nodes are based on the Amazon Linux AMI, so I will deploy on RPM packages and use Elasticsearch as the example application.