AWS Big Data Blog
Performance matters: Amazon Redshift is now up to 3.5x faster for real-world workloads
Since we launched Amazon Redshift, thousands of customers have trusted us to get uncompromising speed for their most complex analytical workloads. Over the course of 2017, our customers benefited from a 3x to 5x performance gain, resulting from short query acceleration, result caching, late materialization, and many other under-the-hood improvements. In this post, we highlight recent improvements to Amazon Redshift and how our continued focus on performance enhancements is benefiting customers. We also discuss performance testing derived from industry-standard benchmarks that help us measure the impact of these ongoing improvements.
Recent performance improvements
With the largest number of data warehousing deployments in the cloud, we have the ability to analyze usage patterns across a variety of analytical workloads and uncover opportunities to improve performance. We leverage these insights to deliver improvements that seamlessly benefit thousands of customers. Major improvements in performance over the past six months include the following:
- Improved resource management for memory-intensive queries: Amazon Redshift improved how joins and aggregations consume and reserve memory. This improved cache efficiency for the majority of the hash tables and reduced spilling for memory-intensive joins and aggregations by up to 1.6x.
- Improved performance for commits: As a central component of write transactions, commit has a direct impact on the performance of data update and data ingestion workloads, such as ETL (extract, transform, and load) jobs. Since November 2017, we’ve delivered a series of commit performance optimizations such as batching multiple commits in a single operation, improved usage of commit locks, and a locality-aware metadata defragmenter. These and other related optimizations have resulted in a 4x commit time reduction on average for HDD-based clusters. For heavy transactions (the top 5 percent of commit operations in Amazon Redshift), the delivered optimizations resulted in a 7.5x improvement.
- Improved performance for repeated queries: With Amazon Redshift’s result caching, dashboards, visualization, and business intelligence (BI) tools that execute queries repeatedly now see a significant boost in performance. In addition, result caching frees up resources that can improve the performance of all other queries.
- Query processing improvements: Amazon Redshift now performs 2x–6x faster for scenarios such as repeated subqueries, advanced analytics functions with predicates, and complex query plans by eliminating duplicate work and streamlining steps.
- Faster string manipulation: Amazon Redshift yields 5x better performance for frequently used string functions because of more efficient code generation techniques.
We’ve also complemented these out-of-the-box improvements with tailored recommendations to help you get better performance at a lower cost with Amazon Redshift Advisor. Advisor has already provided close to 50,000 recommendations since it launched in July 2018.
All of these optimizations have transparently boosted customers’ ability to get faster insights from their AWS analytics platform and saved thousands of hours of execution time on a daily basis. This applies to even the largest deployments, where customers have multiple petabytes of data in Redshift clusters, and seamless access to even larger data volumes in their Amazon S3 data lakes with Amazon Redshift Spectrum. “Redshift’s query performance and scalability has been increasing, even though our data has grown.” said Minero Aoki, Senior Data Engineer, Cookpad Inc. “In the last 10 months, we have seen commit performance increase by 500% without any increase in cost.”
Using benchmarks to measure success
To measure the impact of these ongoing improvements, we measure performance on a nightly basis and run queries derived from industry-standard benchmarks such as TPC-DS. We also occasionally benchmark Amazon Redshift against other data warehouse services. We set up these measurements to reflect our customers’ real-world usage, as highlighted earlier. This enables us to accurately gauge whether Amazon Redshift is getting better with each release, which happens every two weeks.
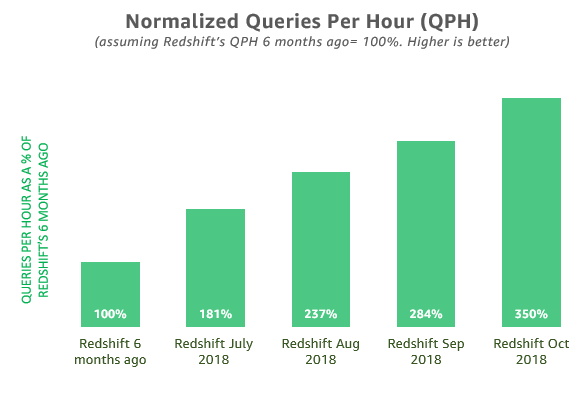
Comparing Amazon Redshift releases over the past few months, we observed that Amazon Redshift is now 3.5x faster versus six months ago, running all 99 queries derived from the TPC-DS benchmark. This is shown in the following chart.
Note: We used a Cloud DW benchmark derived from TPC-DS for this study. As such, the Cloud DW benchmark is not comparable to published TPC-DS results. TPC Benchmark and TPC-DS are trademarks of the Transaction Processing Performance Council.
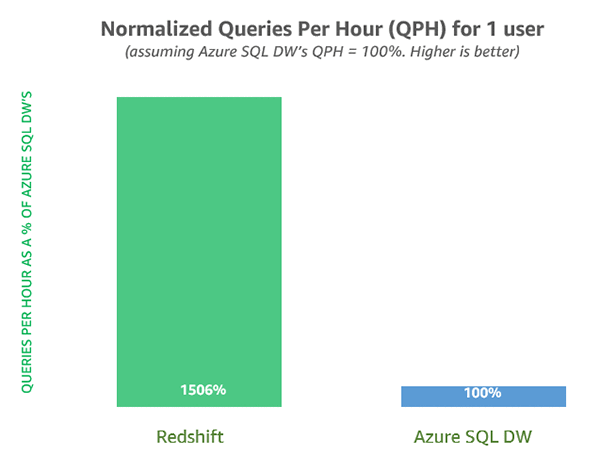
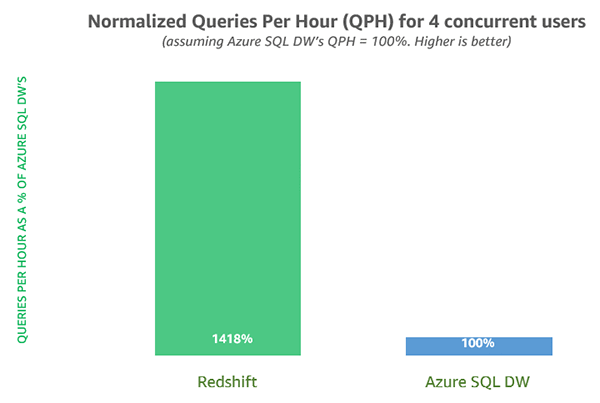
For this post, we also compared the latest Amazon Redshift release with Microsoft Azure SQL Data Warehouse using the Cloud DW benchmark derived from TPC-DS. Queries ran against a 3 TB dataset on a 4-node cluster on both services, using dc2.8xlarge for Amazon Redshift and DW2000c Gen2 for Azure SQL Data Warehouse. We could not run a larger dataset because Azure could not allocate the DW15000c cluster required for a 30 TB dataset owing to capacity constraints at the time of publishing.
We observed that Amazon Redshift is 15x faster than Azure SQL Data Warehouse running all 99 queries with one user, and 14x faster with four concurrent users. There were a couple of outlier queries that took Azure SQL Data Warehouse several hours to complete. Excluding the two long running queries, Amazon Redshift is 2x faster than Azure SQL Data Warehouse with 1 user and 1.6x faster with four concurrent users. The following charts compare the two services.
Note: We used queries derived from TPC-DS v2.9 for this study. Amazon Redshift and Azure SQL DW do not support rollup queries, so we used TPC-DS provided variants for queries 5, 14, 18, 27, 36, 67, 70, 77, 80, and 86. We used out-of-the-box Workload Management configuration for Amazon Redshift, which allows for 5 concurrent queries, and ‘largerc’ resource class for Azure SQL DW, which has a lower limit of 4 concurrent queries. Amazon Redshift took 25 minutes to run all 99 queries, whereas Azure SQL Data Warehouse took 6.4 hours. Ignoring two queries that each took Azure SQL Data Warehouse more than 1 hour to execute (Q38 and Q67), Amazon Redshift took 22 minutes, while Azure SQL Data Warehouse took 42 minutes.
Evaluating Amazon Redshift
Although benchmarks against other data warehouse services are interesting, they are of limited value. First, there’s no one-size-fits-all benchmark. Each service has its unique real-world usage patterns and ways to configure and tune for them. We make a best effort to configure the services based on publicly available guidance, but we can’t guarantee optimal performance for any given service. We see this commonly with third-party benchmarks, for instance, where Amazon Redshift’s powerful distribution and sort keys are not used—even though the large majority of our customers use them.
Similarly, each benchmark query can only be run once, in contrast to real-world scenarios where 99.5 percent of queries we observe have components that can be found in the compilation cache (Amazon Redshift generates and compiles code for each query execution plan. The compiled code segments are stored in a least recently used cache and shared across sessions in a cluster). In other words, they are similar to queries that were run previously. So, the query run times measured by benchmarking studies can end up over-indexing on compilation times, which might not indicate the actual performance you can expect to get.
Secondly, these studies are, by necessity, a point-in-time assessment. As cloud vendors update and evolve their service, benchmark numbers might already be obsolete by the time they’re published.
Therefore, we don’t recommend that you make product selection decisions based on these benchmarks because your data and your query workloads have their own unique characteristics. If you’re evaluating Amazon Redshift for your analytics platform, we have created a Proof of Concept guide to help. You can also request assistance from us, or work with one of our System Integration and Consulting Partners and make a data-driven decision.
Finally, we invite you to watch the recent Fireside chat webinar and join us at re:Invent 2018 in Las Vegas, where we have a ton of exciting news to share with you. Happy querying!
If you would like instruction to reproduce the benchmark, please contact us at redshift-pm@amazon.com. If you have questions or suggestions, please comment below.
About the Authors
 Ayush Jain is a Product Marketer at Amazon Web Services. He loves growing cloud services and helping customers get more value from the cloud deployments. He has several years of experience in Software Development, Product Management and Product Marketing in developer and data services.
Ayush Jain is a Product Marketer at Amazon Web Services. He loves growing cloud services and helping customers get more value from the cloud deployments. He has several years of experience in Software Development, Product Management and Product Marketing in developer and data services.
 Mostafa Mokhtar is an engineer working on Redshift performance. Previously, he held similar roles at Cloudera, Hortonworks and on the SQL Server team at Microsoft.
Mostafa Mokhtar is an engineer working on Redshift performance. Previously, he held similar roles at Cloudera, Hortonworks and on the SQL Server team at Microsoft.