AWS Big Data Blog
Stream mainframe data to AWS in near real time with Precisely and Amazon MSK
This is a guest post by Supreet Padhi, Technology Architect, and Manasa Ramesh, Technology Architect at Precisely in partnership with AWS.
Enterprises rely on mainframes to run mission-critical applications and store essential data, enabling real-time operations that help achieve business objectives. These organizations face a common challenge: how to unlock the value of their mainframe data in today’s cloud-first world while maintaining system stability and data quality. Modernizing these systems is critical for competitiveness and innovation.
The digital transformation imperative has made mainframe data integration with cloud services a strategic priority for enterprises worldwide. Organizations that can seamlessly bridge their mainframe environments with modern cloud platforms gain significant competitive advantages through improved agility, reduced operational costs, and enhanced analytics capabilities. However, implementing such integrations presents unique technical challenges that require specialized solutions. Some of the challenges include converting EBCDIC data to ASCII, where the handling of data types is unique to the mainframe, such as binary data and COMP data. Data stored in Virtual Storage Access Method (VSAM) files can be quite complex due to practices to store multiple different record types in a single file. To address these challenges, Precisely—a global leader in data integrity, serving over 12,000 customers—has partnered with Amazon Web Services (AWS) to enable real-time synchronization between mainframe systems and Amazon Relational Database Service (Amazon RDS). For more on this collaboration, check out our previous blog post: Unlock Mainframe Data with Precisely Connect and Amazon Aurora.
In this post, we introduce an alternative architecture to synchronize mainframe data to the cloud using Amazon Managed Streaming for Apache Kafka (Amazon MSK) for greater flexibility and scalability. This event-driven approach provides additional possibilities for mainframe data integration and modernization strategies.
A key enhancement in this solution is the use of the AWS Mainframe Modernization – Data Replication for IBM z/OS Amazon Machine Image (AMI) available in AWS Marketplace, which simplifies deployment and reduces implementation time.
Real-time processing and event-driven architecture benefits
Real-time processing makes data actionable within seconds rather than waiting for batch processing cycles. For example, financial institutions such as Global Payments have leveraged this solution to modernize mission-critical banking operations, including payments processing. By migrating these operations to the AWS Cloud, they enhanced user experience, improved scalability and maintainability, while enabling advanced fraud detection – all without impacting the performance of existing mainframe systems. Change data capture (CDC) enables this by identifying database changes and delivering them in real time to cloud environments.
CDC offers two key advantages for mainframe modernization:
- Incremental data movement – Eliminates disruptive bulk extracts by streaming only changed data to cloud targets, minimizing system impact and ensuring data currency
- Real-time synchronization – Keeps cloud applications in sync with mainframe systems, enabling immediate insights and responsive operations
Solution overview
In this post, we provide a detailed implementation guide for streaming mainframe data changes from DB2z through AWS Mainframe Modernization – Data Replication for IBM z/OS AMI to Amazon MSK and then applying those changes to Amazon Relational Database Service (Amazon RDS) for PostgreSQL using MSK Connect with the Confluent JDBC Sink Connector.
By introducing Amazon MSK into architecture and streamlining deployment through the AWS Marketplace AMI, we create new possibilities for data distribution, transformation, and consumption that expand upon our previously demonstrated direct replication approach. This streaming-based architecture offers several additional benefits:
- Simplified deployment – Accelerate implementation using the preconfigured AWS Marketplace AMI
- Decoupled systems – Separate the concern of data extraction from data consumption, allowing both sides to scale independently
- Multi-consumer support – Enable multiple downstream applications and services to consume the same data stream according to their own requirements
- Extensibility – Create a foundation that can be extended to support additional mainframe data sources such as IMS and VSAM, as well as additional AWS targets using MSK Connect sink connectors
The following diagram illustrates the solution architecture.
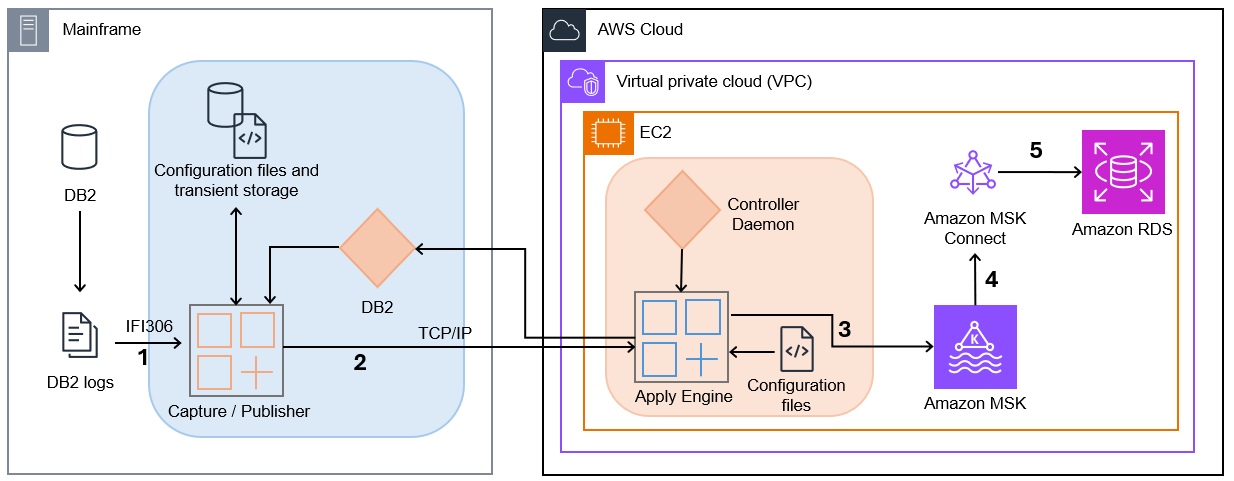
- Capture/Publisher – Connect CDC Capture/Publisher captures Db2 changes from Db2 logs using IFI 306 Read and communicates captured data changes to a target engine through TCP/IP.
- Controller Daemon – The Controller Daemon authenticates all connection requests, managing secure communication between the source and target environments.
- Apply Engine – The Apply Engine is a multifaceted and multifunctional component in the target environment. It receives the changes from the Publisher agent and applies the changed data to the target Amazon MSK.
- Connect CDC Single Message Transform (SMT) – Performs all necessary data filtering, transformation, and augmentation required by the sink connector.
- JDBC Sink Connector – As data arrives, an instance of the JDBC Sink Connector along with Apache Kafka writes the data to target tables in Amazon RDS.
This architecture provides a clean separation between the data capture process and the data consumption process, allowing each to scale independently. The use of MSK as an intermediary enables multiple systems to consume the same data stream, opening possibilities for complex event processing, real-time analytics, and integration with other AWS services.
Prerequisites
To complete the solution, you need the following prerequisites:
- Install AWS Mainframe Modernization – Data Replication for IBM z/OS
- Have access to Db2z on mainframe from AWS using your approved connectivity between AWS and your mainframe
Solution walkthrough
The following code content shouldn’t be deployed to production environments without additional security testing.
Configure the AWS Mainframe Modernization Data Replication with Precisely AMI on Amazon EC2
Follow the steps defined at Precisely AWS Mainframe Modernization Data Replication. Upon the initial launch of the AMI, use the following command to connect to the Amazon Elastic Compute Cloud (Amazon EC2) instance:
Configure the serverless cluster
To create an Amazon Aurora PostgreSQL-Compatible Edition Serverless v2 cluster, complete the following steps:
- Create a DB cluster by using the following AWS Command Line Interface (AWS CLI) command. Replace the placeholder strings with values that correspond to your cluster’s subnet and subnet group IDs.
- Verify the status of the cluster by using the following command:
- Add a writer DB instance to the Aurora cluster:
- Verify the status of the writer instance:
Create a database in the PostgreSQL cluster
After your Aurora Serverless v2 cluster is running, you need to create a database for your replicated mainframe data. Follow these steps:
- Install the psql client:
- Retrieve the password from secret manager:
- Create a new database in PostgreSQL:
Configure the serverless MSK cluster
To create a serverless MSK cluster, complete the following steps:
- Copy the following JSON and paste it into a new file
create-msk-serverless-cluster.json. Replace the placeholder strings with values that correspond to your cluster’s subnet and security group IDs. - Invoke the following AWS CLI command in the folder where you saved the JSON file in the previous step:
- Verify cluster status by invoking the following AWS CLI command:
- Get the bootstrap broker address by invoking the following AWS CLI command:
- Define the environment variable to store the bootstrap servers of the MSK cluster and locally install Kafka in the path environment variable:
Create a topic on the MSK cluster
To create a Kafka topic, you need to install the Kafka CLI first. Follow these steps:
- Download the binary distribution of Apache Kafka and extract the archive in folder
kafka: - To use IAM to authenticate with the MSK cluster, download the Amazon MSK Library for IAM and copy to the local Kafka library directory as shown in the following code. For complete instructions, refer to Configure clients for IAM access control.
- In the directory, create a file to configure a Kafka client to use IAM authentication for the Kafka console producer and consumers:
- Create the Kafka topic, which you defined in the connector config:
Configure the MSK Connect plugin
Next, create a custom plugin available in the AMI at /opt/precisely/di/packages/sqdata-msk_connect_1.0.1.zip which contains the following:
- JDBC Sink Connector from Confluent
- MSK Config provider
- AWS Mainframe Modernization – Data Repication for IBM z/OS Custom SMT
Follow these steps:
- Invoke the following to upload the .zip file to an S3 bucket to which you have access:
- Copy the following JSON and paste it into a new file
create-custom-plugin.json. Replace the placeholder strings with values that correspond to your bucket. - Invoke the following AWS CLI command in the folder where you saved the JSON file in the previous step:
- Verify plugin status by invoking the following AWS CLI command:
Configure the JDBC Sink Connector
To configure the JDBC Sink Connector, follow these steps:
- Copy the following JSON and paste it into a new file
create-connector.json. Replace the placeholder strings with appropriate values: - Invoke the following AWS CLI command in the folder where you saved the JSON file in the previous step:
- Verify connector status by invoking the following AWS CLI command:
Set up Db2 Capture/Publisher on Mainframe
To establish the Db2 Capture/Publisher on the mainframe for capturing changes to the DEPT table, follow these structured steps that build upon our previous blog post, Unlock Mainframe Data with Precisely Connect and Amazon Aurora:
- Prepare the source table. Before configuring the Capture/Publisher, ensure the DEPT source table exists on your mainframe Db2 system. The table definition should match the structure defined at
\$SQDATA_VAR_DIR/templates/dept.ddl. If you need to create this table on your mainframe, use the DDL from this file as a reference to ensure compatibility with the replication process. - Access the Interactive System Productivity Facility (ISPF) interface. Sign in to your mainframe system and access the AWS Mainframe Modernization – Data Repication for IBM z/OS ISPF panels through the supplied ISPF application menu. Select option 3 (CDC) to access the CDC configuration panels, as demonstrated in our previous blog post.
- Add source tables for capture:
- From the CDC Primary Option Menu, choose option 2 (Define Subscriptions).
- Choose option 1 (Define Db2 Tables) to add source tables.
- On the (Add DB2 Source Table to CAB File panel), enter a wildcard value (%) or the specific table name
DEPTin the (Table Name) field. - Press Enter to display the list of available tables.
- Type
Snext to theDEPTtable to select it for replication, then press Enter to confirm.
This process is like the table selection process shown in figure 3 and figure 4 of our previous post but now focuses specifically on the DEPT table structure.
With the completion of both the Db2 Capture/Publisher setup on the mainframe and the AWS environment configuration (Amazon MSK, Apply Engine, and MSK Connect JDBC Sink Connector), you now have a fully functional pipeline ready to capture data changes from the mainframe and stream them to the MSK topic. Inserts, updates, or deletions to the DEPT table on the mainframe will be automatically captured and pushed to the MSK topic in near real time. From there, the MSK Connect JDBC Sink Connector and the custom SMT will process these messages and apply the changes to the PostgreSQL database on Amazon RDS, completing the end-to-end replication flow.
Configure Apply Engine for Amazon MSK integration
Configure the AWS side components to receive data from the mainframe and forward it to Amazon MSK. Follow these steps to define and manage a new CDC pipeline from DB2 z/OS to Amazon MSK:
- Use the following command to switch to the
connectuser: - Create the apply engine directories:
- Copy the sample script from
dept.ddl: - Copy the following content and paste it in a new file
$SQDATA_VAR_DIR/apply/DB2ZTOMSK/scripts/DB2ZTOMSK.sqd. Replace the placeholder strings with values that correspond to the DB2z endpoint: - Create the working directory:
- Add the following to
$SQDATA_DAEMON_DIR/cfg/sqdagents.cfg: - After the preceding code is added to the
sqdagents.cfgsection, reload for the changes to take effect: - Validate the apply engine job script by using the SQData parse command to create the compiled file expected by the SQData engine:
The following is an example of the output that you get when you invoke the command successfully:
- Copy the following content and paste it in a new file
/var/precisely/di/sqdata_logs/apply/DB2ZTOMSK/sqdata_kafka_producer.conf. Replace the placeholder strings with values that correspond to your bootstrap server and AWS Region. - Start the apply engine using the controller daemon by using the following command:
- Monitor the apply engine through the controller daemon by using the following command:
The following is an example of the output that you get when you invoke the command successfully:
Logs can also be found at
/var/precisely/di/sqdata_logs/apply/DB2ZTOMSK.
Verify data in the MSK topic
Invoke the Kafka CLI command to verify the JSON data in the MSK topic:
Verify data in the PostgreSQL database
Invoke the following command to verify the data in the PostgreSQL database:
With these steps completed, you’ve successfully set up end-to-end data replication from DB2z to RDS for PostgreSQL, using AWS Mainframe Modernization – Data Replication for IBM z/OS AMI, Amazon MSK, MSK Connect, and the Confluent JDBC Sink Connector.
Cleanup
When you’re finished testing this solution, you can clean up the resources to avoid incurring additional charges. Follow these steps in sequence to ensure proper cleanup.
Step 1: Delete the MSK Connect components
Follow these steps:
- List existing connectors:
- Delete the sink connector:
- List custom plugins:
- Delete the custom plugin:
Step 2: Delete the MSK cluster
Follow these steps:
- List MSK clusters:
- Delete the MSK serverless cluster:
Step 3: Delete the Aurora resources
Follow these steps:
- Delete the Aurora DB instance:
- Delete the Aurora DB cluster:
Conclusion
By capturing changed data from DB2z and streaming it to AWS targets, organizations can modernize their legacy mainframe data stores, enabling operational insights and AI initiatives. Businesses can use this solution to take advantage of cloud-based applications with mainframe data to provide scalability, cost-efficiency, and enhanced performance.
The integration of AWS Mainframe Modernization – Data Replication for IBM z/OS AMI with Amazon MSK and RDS for PostgreSQL provides an enhanced framework for real-time data synchronization that maintains data integrity. This architecture can be extended to support additional mainframe data sources such as VSAM and IMS, as well as other AWS targets. Organizations can then tailor their data integration strategy to specific business needs. Data consistency and latency challenges can be effectively managed through AWS and Precisely’s monitoring capabilities. By adopting this architecture, organizations keep their mainframe data continually available for analytics, machine learning (ML), and other advanced applications.Streaming mainframe data to AWS in near real time represents a strategic step toward modernizing legacy systems while unlocking new opportunities for innovation, with data transfers occurring in subseconds. With Precisely and AWS, organizations can effectively navigate their modernization journey and maintain their competitive advantage.
Learn more about AWS Mainframe Modernization – Data Replication for IBM z/OS AMI in the Precisely documentation. AWS Mainframe Modernization Data Replication is available for purchase in AWS Marketplace. For more information about the solution or to see a demonstration, contact Precisely.