AWS Compute Blog
Application integration patterns for microservices: Orchestration and coordination
This post is courtesy of Stephen Liedig, Sr. Serverless Specialist SA.
This is the final blog post in the “Application Integration Patterns for Microservices” series. Previous posts cover asynchronous messaging for microservices, fan-out strategies, and scatter-gather design patterns.
In this post, I look at how to implement messaging patterns to help orchestrate and coordinate business workflows in our applications. Specifically, I cover two patterns:
- Pipes and Filters, as presented in the book “Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions” (Hohpe and Woolf, 2004)
- Saga Pattern, which is a design pattern for dealing with “long-lived transactions” (LLT), published by Garcia-Molina and Salem in 1987.
I discuss these patterns using the Wild Rydes example from this series.
Wild Rydes
Wild Rydes is a fictional technology start-up created to disrupt the transportation industry by replacing traditional taxis with unicorns. Several hands-on AWS workshops use the Wild Rydes scenario. It illustrates concepts such as serverless development, event-driven design, API management, and messaging in microservices.

This blog post explores the build process of the Wild Rydes workshop, to help you apply these concepts to your applications.
After completing a unicorn ride, the Wild Rydes customer application charges the customer. Once the driver submits a ride completion, an event triggers the following steps:
- Registers the fare: registers the fare ride completion event.
- Initiates the payment (via a payment service): calls a payment gateway for credit card pre-authorization. Using the pre-authorization code, it completes the payment transaction.
- Updates customer accounting system: once the payment is processed, updates the Wild Rydes customer accounting system with the transaction detail.
- Publishes “Fare Processed” event: sends a notification to interested components that the process is completed.
Each of the steps interfaces with separate systems – the Wild Rydes system, a third-party payment provider, and the customer accounting system. You could implement these steps inside a single component, but that would make it difficult to change and adapt. It’d also reduce the potential for components reuse within our application. Breaking down the steps into individual components allows you to build components with a single responsibility making it easier to manage each components dependencies and application lifecycle. You can be selective about how you implement the respective components, for example, different teams responsible for the development of the respective components may choose to use different languages. This is where the Pipes and Filters architectural pattern can help.
Pipes and filters
Hohpe and Woolf define Pipes and Filters as an “architectural style to divide a larger processing task into a sequence of smaller, independent processing steps (filters) that are connected by channels (pipes).”

Pipes provide a communications channel that abstracts the consumer of messages sent through that channel. It decouples your filter from one another, so components only need to know the messaging channel, or endpoint, where they are sending messages. They do not know who, or what, is processing that message, or where the receiver is located on the network.
Amazon SQS provides a lightweight solution with the power and scale of messaging middleware. It is a simple, flexible, fully managed message queuing service for reliably and continuously exchanging large volume of messages. It has virtually limitless scalability and the ability to increase message throughput without pre-provisioning capacity.
You can create an SQS queue with this AWS CLI command:
aws sqs create-queue --queue-name MyQueue
For the fare processing scenario, you could implement a Pipes and Filters architectural pattern using AWS services. This uses two Amazon SQS queues and an Amazon SNS topic:

Amazon SQS provides a mechanism for decoupling the components. The filters only need to know to which queue to send the message, without knowing which component processes that message nor when it is processed. SQS does this in a secure, durable, and scalable way.
Despite the fact that none of the filters have a direct dependency on one another, there is still a degree of coupling at the pipe level. Changing execution order therefore forces you to update and redeploy your existing filters to point to a new pipe. In the Wild Rydes example, you can reduce the impact of this by defining an environment variable for the destination endpoint in AWS Lambda function configuration, rather than hardcoding this inside your implementations.
Dealing with failures and retries requires some consideration too. In Amazon SQS terms, this requires you to define configurations, such a message VisibilityTimeOut. The VisibilityTimeOut setting provides you with some transactional support. It ensures that the message is not removed from the queue until after you have finished processing the message and you explicitly delete it from the queue. Using Amazon SQS as an Event Source for AWS Lambda further simplifies that for you because the message polling implementation is managed by the service, so you don’t need to create an explicit implementation in your filter.
Amazon SQS helps deal with failures gracefully as it maintains a count of how many times a message is processed via ReceiveCount. By specifying a maxReceiveCount, you can limit the number of times a poisoned message gets processed. Combine this with a dead letter queue (DLQ), you can then move messages that have exceeded the maxReceiveCount number to the DLQ. Adding Amazon CloudWatch alarms on metrics such as ApproximateNumberOfMessagesVisible on the DLQ, you can proactively alert on system failures if the number of messages on the dead letter queue exceed and acceptable threshold.
Alternatively, you can model the fare payment scenario with AWS Step Functions. Step Functions externalizes the Pipes and Filters pattern. It extracts the coordination from the filter implementations into a state machine that orchestrates the sequence of events. Visual workflows allow you to change the sequence of execution without modifying code, reducing the amount of coupling between collaborating components.
Here is how you could model the fare processing scenario using Step Functions:
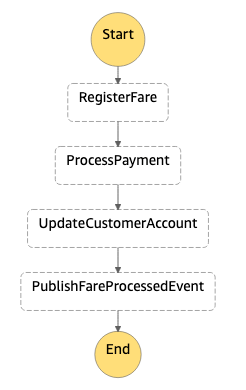
{
"Comment": "StateMachine for Processing Fare Payments",
"StartAt": "RegisterFare",
"States": {
"RegisterFare": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:RegisterFareFunction",
"Next": "ProcessPayment"
},
"ProcessPayment": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:ChargeFareFunction",
"Next": "UpdateCustomerAccount"
},
"UpdateCustomerAccount": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:UpdateCustomerAccountFunction",
"Next": "PublishFareProcessedEvent"
},
"PublishFareProcessedEvent": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:REGION:ACCOUNT_ID:myTopic",
"Message": {
"Input": "Hello from Step Functions!"
}
},
"End": true
}
}
}
AWS Step Functions allows you to easily build more sophisticated workflows. These could include decision points, parallel processing, wait states to pause the state machine execution, error handling, and retry logic. Error and Retry states help you simplify your component implementation by providing a framework for error handling and implementation exponential backoff on retries. You can define alternate execution paths if failures cannot be handled.
In this implementation, each of these states is a discrete transaction. Some implement database transactions when registering the fare, others are calling the third-party payment provider APIs, and internal APIs or programming interfaces when updating the customer accounting system.
Dealing with each of these transactions independently is relatively straightforward. But what happens if you require consistency across all steps so that either all or none of the transactions complete? How can you deal with consistency across multiple, distributed transactions? How do we deal with the temporal aspects of coordinating these potentially long running heterogeneous integrations?
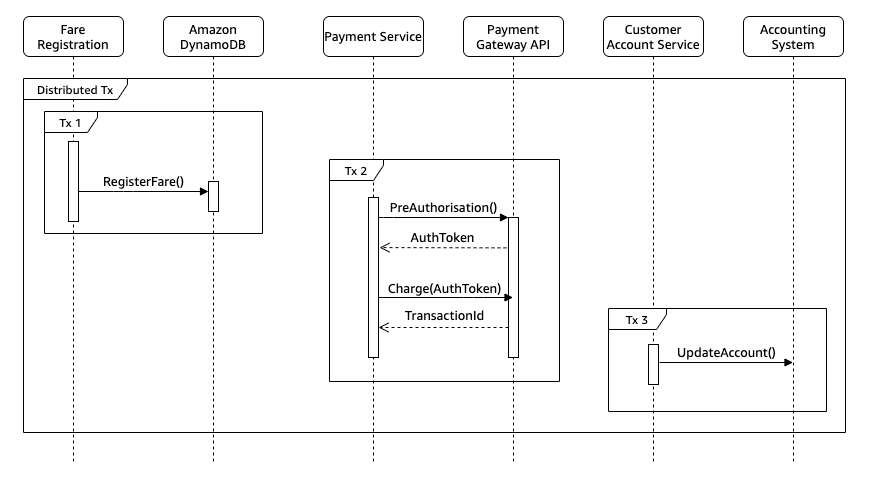
Cloud providers do not support Distributed Transaction Coordinators (DTC) or two-phase commit protocols responsible for coordinating transactions across multiple cloud resources. Therefore, you need a mechanism to explicitly coordinate multiple local transactions. This is where the saga pattern and AWS Step Functions can help.
A saga is a design pattern for dealing with “long-lived transactions” (LLT), published by Garcia-Molina and Salem in 1987, they define the concept of a saga as:
“LLT is a saga if it can be written as a sequence of transactions that can be interleaved with other transactions.” (Garcia-Molina, Salem 1987)
Fundamentally, saga can provide a failure management pattern to establish consistency across all of your distributed applications, by implementing a compensating transaction for each step in a series of functions. Compensating transactions allow you to back out of the changes that were previously committed in your series of functions, so that if one of your steps fails you can “undo” what you did before, and leave your system in stable state, devoid of side-effects.
AWS Step Functions provides a mechanism for implementing a saga pattern with the ability to build fully managed state machines that allow you to catch custom business exceptions and manage and share data across state transitions.
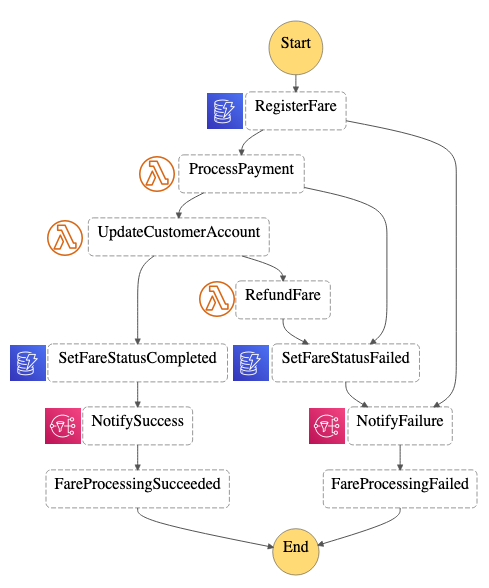
Figure 1: Using Step Functions’ Service Integrations for Amazon DynamoDB and Amazon SNS, you can further reduce the need for a custom AWS Lambda implementation to persist data to the database, or send a notification.
By using these capabilities, you can expand on the previous Fare Processing state machine and implementing compensating transaction states. If Register Fare fails, you may want to emit an event that invokes an external support function or generates a notification informing operators of the system the error.
If payment processing failed, you would want to ensure that the status is updated to reflect state change and then notify operators of the failed event. You might decide to refund customers, update the fare status and notify support, until you have been able to resolve issues with the customer accounting system. Regardless of the approach, Step Functions allows you to model a failure scenario that aligns with a more business-centric view of consistency.
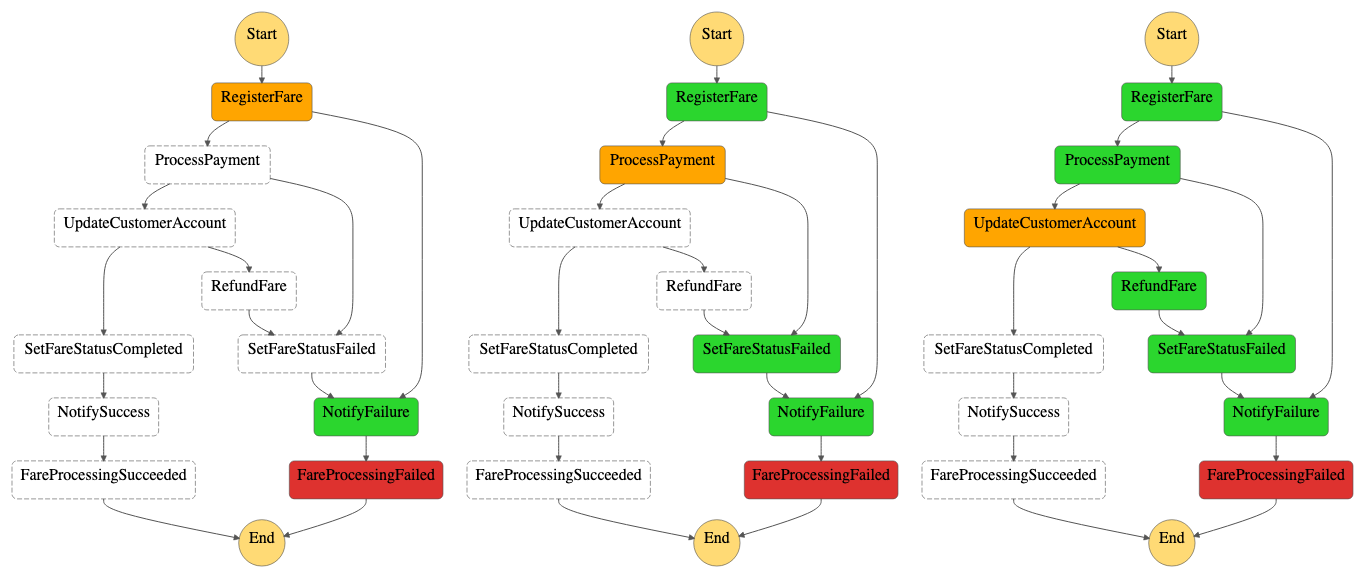
If you want to see the full state machine implementation in Lab4 of Wild Rydes Asynchronous Messaging Workshop. The workshop guides you through building your own state machine so you can see how to apply the pattern to your own scenarios. There are also three other workshops you can walk through that cover the other patterns in the series.
Conclusion
Using Wild Rydes, I show how to use Amazon SQS and AWS Step Functions to decouple your application components and services. I show you how these services help to coordinate and orchestrate distributed components to build resilient and fault tolerant microservices architectures.
Take part in the Wild Rydes Asynchronous Messaging Workshop and learn about the other messaging patterns you can apply to microservices architectures, including fan-out and message filtering, topic-queue-chaining and load balancing (blog post), and scatter-gather.
The Wild Rydes Asynchronous Messaging Workshop resources are hosted on our AWS Samples GitHub repository, including the sample code for this blog post under Lab-4: Choreography and orchestration.
For a deeper dive into queues and topics and how to use these in microservices architectures, read:
- The AWS whitepaper, Implementing Microservices on AWS.
- Implementing enterprise integration patterns with AWS messaging services: point-to-point channels.
- Implementing enterprise integration patterns with AWS messaging services: publish-subscribe channels.
- Building Scalable Applications and Microservices: Adding Messaging to Your Toolbox.
For more information on enterprise integration patterns, see: