AWS Compute Blog
Building a scalable log solution aggregator with AWS Fargate, Fluentd, and Amazon Kinesis Data Firehose
February 12, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
This post is contributed by Wesley Pettit, Software Dev Engineer, and a maintainer of the Amazon ECS CLI.
Modern distributed applications can produce gigabytes of log data every day. Analysis and storage is the easy part. From Amazon S3 to Elasticsearch, many solutions are available. The hard piece is reliably aggregating and shipping logs to their final destinations.
In this post, I show you how to build a log aggregator using AWS Fargate, Amazon Kinesis Data Firehose, and Fluentd. This post is unrelated to the AWS effort to support Fluentd to stream container logs from Fargate tasks. Follow the progress of that effort on the AWS container product roadmap.
Solution overview
Fluentd forms the core of my log aggregation solution. It is an open source project that aims to provide a unified logging layer by handling log collection, filtering, buffering, and routing. Fluentd is widely used across cloud platforms and was adopted by the Cloud Native Computing Foundation (CNCF) in 2016.
AWS Fargate provides a straightforward compute environment for the Fluentd aggregator. Kinesis Data Firehose streams the logs to their destinations. It batches, compresses, transforms, and encrypts the data before loading it. Kinesis minimizes the amount of storage used at the destination and increases security.
The log aggregator that I detail in this post is generic and can be used with any type of application. However, for simplicity, I focus on how to use the aggregator with Amazon Elastic Container Service (ECS) tasks and services.
Building a Fluentd log aggregator on Fargate that streams to Kinesis Data Firehose
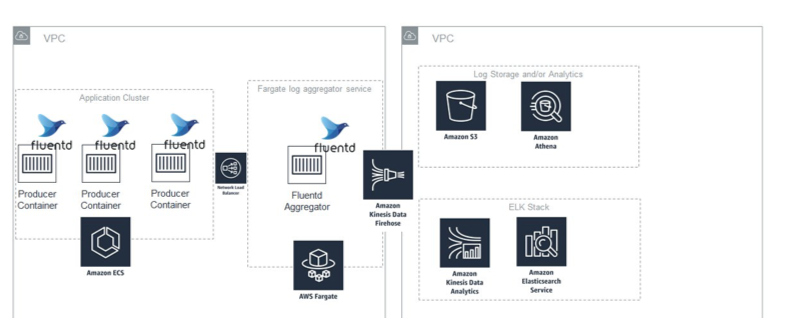
The diagram describes the architecture that you are going to implement. A Fluentd aggregator runs as a service on Fargate behind a Network Load Balancer. The service uses Application Auto Scaling to dynamically adjust to changes in load.
Because the load balancer DNS can only be resolved in the VPC, the aggregator is a private log collector that can accept logs from any application in the VPC. Fluentd streams the logs to Kinesis Data Firehose, which dumps them in S3 and Amazon ElasticSearch Service (Amazon ES).
Not all logs are of equal importance. Some require real time analytics, others simply need long-term storage so that they can be analyzed if needed. In this post, applications that log to Fluentd are split up into frontend and backend.
Frontend applications are user-facing and need rich functionality to query and analyze the data present in their logs to obtain insights about users. Therefore, frontend application logs are sent to Amazon ES.
In contrast, backend services do not need the same level of analytics, so their logs are sent to S3. These logs can be queried using Amazon Athena, or they can be downloaded and ingested into other analytics tools as needed.
Each application tags its logs, and Fluentd sends the logs to different destinations based on the tag. Thus, the aggregator can determine whether a log message is from a backend or frontend application. Each log message gets sent to one of two Kinesis Data Firehose streams:
- One streams to S3
- One streams to an Amazon ES cluster
Running the aggregator on Fargate makes maintaining this service easy, and you don’t have to worry about provisioning or managing instances. This makes scaling the aggregator simple. You do not have to manage an additional Auto Scaling group for instances.
Aggregator performance and throughput
Before I walk you through how to deploy the Fluentd aggregator in your own VPC, you should know more about its performance.
I performed extensive real world testing with this aggregator set up, to test its limits. Each task in the aggregator service can handle at least at least 9 MB/s of log traffic, and at least 10,000 log messages/second. These are comfortable lower bounds for the aggregator’s performance. I recommend using these numbers to provision your aggregator service based upon your expected throughput for log traffic.
While this aggregator set up includes dynamic scaling, you must carefully choose the minimum size of the service. This is because dynamic scaling with Fluentd is complicated.
The Fluentd aggregator accepts logs via TCP connections, which are balanced across the instances of the service by the Network Load Balancer. However, these TCP connections are long-lived, and the load balancer only distributes new TCP connections. Thus, when the aggregator scales up in response to increased load, the new Fargate tasks can not help with any of the existing load. The new tasks can only take new TCP connections. This also means that older tasks in the aggregator tend to accumulate connections with time. This is an important limitation to keep in mind.
For the Docker logging driver for Fluentd (which can be used by ECS tasks to send logs to the aggregator), a single TCP connection is made when each container starts. This connection is held open as long as possible. A TCP connection can remain open as long as data is still being sent over it, and there are no network connectivity issues. The only way to guarantee that there are new TCP connections is to launch new containers.
Dynamic scaling can only help in cases where there are spikes in log traffic and new TCP connections. If you are using the aggregator with ECS tasks, dynamic scaling is only useful if spikes in log traffic come from launching new containers. On the other hand, if spikes in log traffic come from existing containers that periodically increase their log output, then dynamic scaling can’t help.
Therefore, configure the minimum number of tasks for the aggregator based upon the maximum throughput that you expect from a stable population of containers. For example, if you expect 45 MB/s of log traffic, then I recommend setting the minimum size of the aggregator service to five tasks, so that each one gets 9 MB/s of traffic.
For reference, here is the resource utilization that I saw for a single aggregator task under a variety of loads. The aggregator is configured with four vCPU and 8 GB of memory as its task size. As you can see, CPU usage scales linearly with load, so dynamic scaling is configured based on CPU usage.
Performance of a single aggregator task
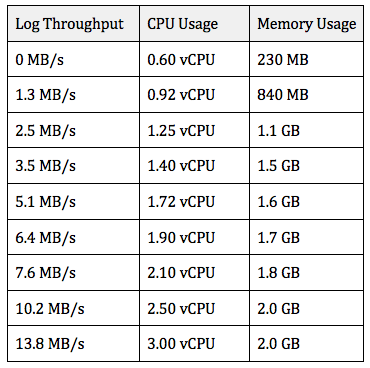
Keep in mind that this data does not represent a guarantee, as your performance may differ. I recommend performing real-world testing using logs from your applications so that you can tune Fluentd to your specific needs.
As a warning, one thing to watch out for is messages in the Fluentd logs that mention retry counts:
2018-10-24 19:26:54 +0000 [warn]: #0 [output_kinesis_frontend] Retrying to request batch. Retry count: 1, Retry records: 250, Wait seconds 0.35
2018-10-24 19:26:54 +0000 [warn]: #0 [output_kinesis_frontend] Retrying to request batch. Retry count: 2, Retry records: 125, Wait seconds 0.27
2018-10-24 19:26:57 +0000 [warn]: #0 [output_kinesis_frontend] Retrying to request batch. Retry count: 1, Retry records: 250, Wait seconds 0.30
In my experience, these warnings always came up whenever I was hitting Kinesis Data Firehose API limits. Fluentd can accept high volumes of log traffic, but if it runs into Kinesis Data Firehose limits, then the data is buffered in memory.
If this state persists for a long time, data is eventually lost when the buffer reaches its max size. To prevent this problem, either increase the number of Kinesis Data Firehose delivery streams in use or request a Kinesis Data Firehose limit increase.
Aggregator reliability
In normal use, I didn’t see any dropped or duplicated log messages. A small amount of log data loss occurred when tasks in the service were stopped. This happened when the service was scaling down, and during deployments to update the Fluentd configuration.
When a task is stopped, it is sent SIGTERM, and then after a 30-second timeout, SIGKILL. When Fluentd receives the SIGTERM, it makes a single attempt to send all logs held in its in-memory buffer to their destinations. If this single attempt fails, the logs are lost. Therefore, log loss can be minimized by over-provisioning the aggregator, which reduces the amount of data buffered by each aggregator task.
Also, it is important to stay well within your Kinesis Data Firehose API limits. That way, Fluentd has the best chance of sending all the data to Kinesis Data Firehose during that single attempt.
To test the reliability of the aggregator, I used applications hosted on ECS that created several megabytes per second of log traffic. These applications inserted special ‘tracer’ messages into their normal log output. By querying for these tracer messages at the log storage destination, I was able determine how many messages were lost or duplicated.
These tracer logs were produced at a rate of 18 messages per second. During a deployment to the aggregator service (which stops all the existing tasks after starting new ones), 2.67 tracer messages were lost on average, and 11.7 messages were duplicated.
There are multiple ways to think about this data. If I ran one deployment during an hour, then 0.004% of my log data would be lost during that period, making the aggregator 99.996% reliable. In my experience, stopping a task only causes log loss during a short time slice of about 10 seconds.
Here’s another way to look at this. Every time that a task in my service was stopped (either due to a deployment or the service scaling in), only 1.5% of the logs received by that task in the 10-second period were lost on average.
As you can see, the aggregator is not perfect, but it is fairly reliable. Remember that logs were only dropped when aggregator tasks were stopped. In all other cases, I never saw any log loss. Thus, the aggregator provides a sufficient reliability guarantee that it can be trusted to handle the logs of many production workloads.
Deploying the aggregator
Here’s how to deploy the log aggregator in your own VPC.
1. Create the Kinesis Data Firehose delivery streams.
2. Create a VPC and network resources.
3. Configure Fluentd.
4. Build the Fluentd Docker image.
5. Deploy the Fluentd aggregator on Fargate.
6. Configure ECS tasks to send logs to the aggregator.
Create the Kinesis Data Firehose delivery streams
For the purposes of this post, assume that you have already created an Elasticsearch domain and S3 bucket that can be used as destinations.
Create a delivery stream that sends to Amazon ES, with the following options:
- For Delivery stream name, type “elasticsearch-delivery-stream.”
- For Source, choose Direct Put or other sources.
- For Record transformation and Record format conversion, enable them to change the format of your log data before it is sent to Amazon ES.
- For Destination, choose Amazon Elasticsearch Service.
- If needed, enable S3 backup of records.
- For IAM Role, choose Create new or navigate to the Kinesis Data Firehose IAM role creation wizard.
- For the IAM policy, remove any statements that do not apply to your delivery stream.
All records sent through this stream are indexed under the same Elasticsearch type, so it’s important that all of the log records be in the same format. Fortunately, Fluentd makes this easy. For more information, see the Configure Fluentd section in this post.
Follow the same steps to create the delivery stream that sends to S3. Call this stream “s3-delivery-stream,” and select your S3 bucket as the destination.
Create a VPC and network resources
Download the ecs-refarch-cloudformation/infrastructure/vpc.yaml AWS CloudFormation template from GitHub. This template specifies a VPC with two public and two private subnets spread across two Availability Zones. The Fluentd aggregator run in the private subnets, along with any other services that should not be accessible outside the VPC. Your backend services would likely run here as well.
The template configures a NAT gateway that allows services in the private subnets to make calls to endpoints on the internet. It allows one-way communication out of the VPC, but blocks incoming traffic. This is important. While the aggregator service should only be accessible in your VPC, it does need to make calls to the Kinesis Data Firehose API endpoint, which lives outside of your VPC.
Deploy the template with the following command:
Configure Fluentd
The Fluentd aggregator collects logs from other services in your VPC. Assuming that all these services are running in Docker containers that use the Fluentd docker log driver, each log event collected by the aggregator is in the format of the following example:
This log event is from an Apache server running in a container on ECS. The line that the server logged is captured in the log field, while source, container_id, and container_name are metadata added by the Fluentd Docker logging driver.
As I mentioned earlier, all log events sent to Amazon ES from the delivery stream must be in the same format. Furthermore, the log events must be JSON-formatted so that they can be converted into a Elasticsearch type. The Fluentd Docker logging driver satisfies both of these requirements.
If you have applications that emit Fluentd logs in different formats, then you could use a Lambda function in the delivery stream to transform all of the log records into a common format.
Alternatively, you could have a different delivery stream for each application type and log format and each log format could correspond to a different type in the Amazon ES domain. For simplicity, this post assumes that all of the frontend and backend services run on ECS and use the Fluentd Docker logging driver.
Now create the Fluentd configuration file, fluent.conf:
This file can also be found here, along with all of the code for this post. The first three lines tell Fluentd to use four workers, which means it can use up to 4 CPU cores. You later configure each Fargate task to have four vCPU. The rest of the configuration defines sources and destinations for logs processed by the aggregator.
The first source listed is the main source. All the applications in the VPC forward logs to Fluentd using this source definition. The source tells Fluentd to listen for logs on port 24224. Logs are streamed over tcp connections at this port.
The second source is the http Fluentd plugin, listening on port 8888. This plugin accepts logs over http; however, this is only used for container health checks. Because Fluentd lacks a built-in health check, I’ve created a container health check that sends log messages via curl to the http plugin. The rationale is that if Fluentd can accept log messages, it must be healthy. Here is the command used for the container health check:
The query parameter in the URL defines a URL-encoded JSON object that looks like this:
The container health check inputs a log message of “health check”. While the query parameter in the URL defines the log message, the path, which is /healthcheck, sets the tag for the log message. In Fluentd, log messages are tagged, which allows them to be routed to different destinations.
In this case, the tag is healthcheck. As you can see in the configuration file, the first <match> definition handles logs that have a tag that matches the pattern health*. Each <match> element defines a tag pattern and defines a destination for logs with tags that match that pattern. For the health check logs, the destination is null, because you do not want to store these dummy logs anywhere.
The Configure ECS tasks to send logs to the aggregator section of this post explains how log tags are defined with the Fluentd docker logging driver. The other <match> elements process logs for the applications in the VPC and send them to Kinesis Data Firehose.
One of them matches any log tag that begins with “frontend”, the other matches any tag that starts with “backend”. Each sends to a different delivery stream. Your frontend and and backend services can tag their logs and have them be sent to different destinations.
Fluentd lacks built in support for Kinesis Data Firehose, so use an open source plugin maintained by AWS: awslabs/aws-fluent-plugin-kinesis.
Finally, each of the Kinesis Data Firehose <match> tags define buffer settings with the <buffer> element. The Kinesis output plugin buffers data in memory if needed. These settings have been tuned to increase throughput and minimize the chance of data loss, though you should modify them as needed based upon your own testing. For a discussion on the throughput and performance of this setup, see the Aggregator performance and throughput section in this post.
Build the Fluentd Docker image
Download the Dockerfile, and place it in the same directory as the fluentd.conf file discussed earlier. The Dockerfile starts with the latest Fluentd image based on Alpine, and installs awslabs/aws-fluent-plugin-kinesis and curl (for the container health check discussed earlier).
In the same directory, create an empty directory named /plugins. This directory is left empty but is needed when building the Fluentd Docker image. For more information about building custom Fluentd Docker images, see the Fluentd page on DockerHub.
Build and tag the image:
Push the image to an ECR repository so that it can be used in the Fargate service.
Deploy the Fluentd aggregator on Fargate
Download the CloudFormation template, which defines all the resources needed for the aggregator service. This includes the Network Load Balancer, target group, security group, and task definition.
First, create a cluster:
Second, create an Amazon ECS task execution IAM role. This allows the Fargate task to pull the Fluentd container image from ECR. It also allows the Fluentd Aggregator Tasks to log to Amazon CloudWatch. This is important: Fluentd can’t manage its own logs because that would be a circular dependency.
The template can then be launched into the VPC and private subnets created earlier. Add the required information as parameters:
MinTasks is set to 2, and MaxTasks is set to 4, which means that the aggregator always has at least two tasks.
When load increases, it can dynamically scale up to four tasks. Recall the discussion in Aggregator performance and throughput and set these values based upon your own expected log throughput.
Configure ECS tasks to send logs to the aggregator
First, get the DNS name of the load balancer created by the CloudFormation template. In the EC2 console, choose Load Balancers. The load balancer has the same value as the EnvironmentName parameter. In this case, it is fluentd-aggregator-service.
Create a container definition for a container that logs to the Fluentd aggregator by adding the appropriate values for logConfiguration. In the following example, replace the fluentd-address value with the DNS name for your own load balancer. Ensure that you add :24224 after the DNS name; the aggregator listens on TCP port 24224.
Notice the tag value, frontend-apache. This is how the tag discussed earlier is set. This tag matches the pattern frontend*, so the Fluentd aggregator sends it to the delivery stream for “frontend” logs.
Finally, your container instances need the following user data to enable the Fluentd log driver in the ECS agent:
Conclusion
In this post, I showed you how to build a log aggregator using AWS Fargate, Amazon Kinesis Data Firehose, and Fluentd.
To learn how to use the aggregator with applications that do not run on ECS, I recommend reading All Data Are Belong to AWS: Streaming upload via Fluentd from Kiyoto Tamura, a maintainer of Fluentd.