AWS News Blog
All Data Are Belong to AWS: Streaming upload via Fluentd

|
I’ve got a special treat for you today! Kiyoto Tamura of Treasure Data wrote a really interesting guest post to introduce you to Fluentd and to show you how you can use it with a wide variety of AWS services to collect, store, and process data.
— Jeff;
Data storage is Cheap. Data collection is Not!
Data storage has become incredibly cheap. When I say cheap, I do not mean in terms of hardware but operational, labor cost. Thanks to the advent of IaaS like AWS, many of us no longer spend days and weeks on capacity planning (or better yet, can provision resources in an auto-scalable manner) or worry about our server racks catching fire.

Cheaper storage means that our ideas are no longer bound by how much data we can store. A handful of engineers can run a dozen or so Redshift instances or manage hundreds of billions of log data backed up in Amazon Simple Storage Service (Amazon S3) to power their daily EMR batch jobs. Analyzing massive datasets is no longer a privilege exclusive to big, tech-savvy companies.
However, data collection is still a major challenge: data does not magically originate inside storage systems or organize themselves; hence, many (ad hoc) scripts are written to parse and load data. These scripts are brittle, error-prone and near-impossible to extend.
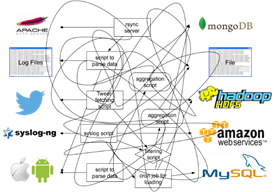
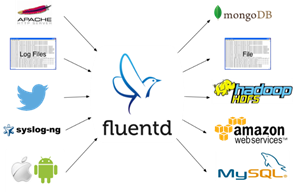
This is the problem Fluentd tries to solve: scalable, flexible data collection in real-time. In the rest of this blog post, I will walk through the basic architecture of Fluentd and share some use cases on AWS.
Fluentd: Open Source Data Collector for High-volume Data Streams
Fluentd is an open source data collector originally written at Treasure Data. Open-sourced in October 2011, it has gained traction steadily over the last 2.5 years: today, we have a thriving community of ~50 contributors and 2,100+ Stargazers on GitHub with companies like Slideshare and Nintendo deploying it in production.
Inputs and Outputs
At the highest level, Fluentd consists of inputs and outputs. Inputs specify how and where Fluentd ingests data.
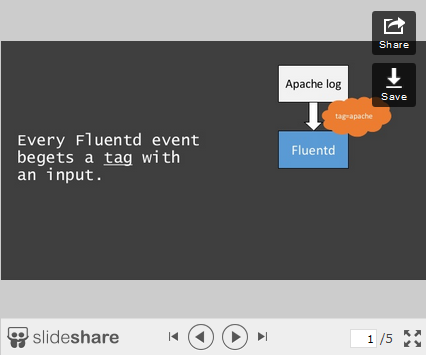
Common inputs are:
- Tailing log files and parsing each line (or multiple lines at a time).
- Listening to syslog messages.
- Accepting HTTP requests and parsing the message body.
There are two key features about inputs: JSON and tagging.
- Fluentd embraces JSON as its core data format, and each input is responsible for turning incoming data into a series of JSON “events.”
- Each input gives a tag to the data it ingests. Based on the tag, Fluentd decides what to do with data coming from different inputs (see below).
Once data flow into Fluentd via inputs, Fluentd looks at each event’s tag (as explained in 2 above) and routes it to output targets such as a local filesystem, RDBMSs, NoSQL databases and AWS services.
Open and Pluggable Architecture
How does Fluentd have so many inputs and outputs already? The secret is its open, pluggable architecture. With a minimal knowledge of Ruby, one can build a new plugin in a matter of few hours. Unsurprisingly, many Fluentd users are also AWS enthusiasts, so we already have plugins for the following AWS services:
- Amazon Simple Storage Service (Amazon S3) (output)
- Amazon Redshift (output)
- Amazon Simple Queue Service (Amazon SQS) (input and output)
- Amazon Kinesis (output)
- Amazon DynamoDB (output)
- Amazon CloudWatch (input)
Performance and Reliability
Whenever I “confess” that Fluentd is mostly written in Ruby, people express concerns about performance. Fear not. Fluentd is plenty fast. On a modern server, it can process ~15,000 events/sec on a single core, and you can get better throughput by running Fluentd on multiple cores.
Fluentd gets its speed from using lower-level libraries written in C for performance-critical parts of the software: For example, Fluentd uses Cool.io (maintained by Masahiro Nakagawa, the main maintainer of Fluentd) for event loop and MessagePack for Ruby (maintained by Sadayuki Furuhashi, the original author of Fluentd) for internal data format.
Speed is nice, but reliability is a must for log collection: data loss leads to bad data and worse decisions. Fluentd ensures reliability through buffering. Output plugins can be configured to buffer its data either in-memory or on-disk so that if data transfer fails, it can be retried without data loss. The buffering logic is highly tunable and can be customized for various throughput/latency requirements.
Example: Archiving Apache Logs into S3
Now that I’ve given an overview of Fluentd’s features, let’s dive into an example. We will show you how to set up Fluentd to archive Apache web server logs into S3.
Step 1: Getting Fluentd
Fluentd is available as a Ruby gem (gem install fluentd). Also, Treasure Data packages it with all the dependencies as td-agent. Here, we proceed with td-agent. I assume that you are on Ubuntu Precise (12.04), but td-agent is also available for Ubuntu Lucid and CentOS 5/6 with the support for Ubuntu Trusty forthcoming.
Run the following command:
curl -L http://toolbelt.treasuredata.com/sh/install-ubuntu-precise.sh | shYou can check that td-agent is successfully installed by running the following command:
$ which td-agent
/usr/sbin/td-agent
Step 2: Configuring Input and Output
For td-agent, the configuration file is located at /etc/td-agent/td-agent.conf. Let’s reconfigure it so that it tails the Apache log file.
type tail
format apache2
path /var/log/apache2/access_log
pos_file /var/log/td-agent/apache2.access_log.pos
tag s3.apache.access
This snippet configures the Apache log file input. It tells Fluentd to tail the log file located at /var/log/apache2/access_log, parse it according to the Apache combined log format and tag it as s3.apache.access.
Next, we configure the S3 output as follows:
type s3
s3_bucket YOUR_BUCKET_NAME
path logs/
buffer_path /var/log/td-agent/s3
time_slice_format %Y%m%d%H
time_slice_wait 10m
utc
format_json true
include_time_key true
include_tag_key true
buffer_chunk_limit 256m
The <match s3.*.*> tells Fluentd to match any event whose tag has 1) three parts and 2) starts with s3. Since all the events coming from the Apache access log have the tag s3.apache.access, it gets matched here and sent to S3.
Finally, let’s start td-agent with the updated configuration:
$ sudo service td-agent start
* Starting td-agent td-agent [OK]
It might take about 10 minutes for your data to appear in S3 due to buffering (see “time_slice_wait”), but eventually logs should appear in YOUR_BUCKET_NAME/logs/yyyyMMddHH. Also, make sure that Fluentd has write access to your S3 bucket. The following setting should be used for IAM roles:
{
"Effect": "Allow",
"Action": [
"s3:Get*", "s3:List*","s3:Put*", "s3:Post*"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME/logs/*", "arn:aws:s3::: YOUR_BUCKET_NAME"
]
}
What’s Next?
The above overview and example give you only a glimpse of what can be done with Fluentd. You can learn more about Fluentd on its website and documentation and contribute to the project on its GitHub repository. If you have any questions, tweet to us on Twitter or ask us questions on the mailing list!
— Kiyoto