AWS Compute Blog
Optimizing your AWS Lambda costs – Part 1
This post is written by Chris Williams, Solutions Architect and Thomas Moore, Solutions Architect, Serverless.
When you develop and architect solutions, cost-optimization should always be part of the process. This is no different for serverless applications that have been developed using AWS Lambda.
Your workloads may vary in terms of complexity, usage patterns, and technology. However, the following advice is applicable to all customers when deciding how to prioritize cost optimization with the tradeoffs of developing the application:
- Efficient code makes better use of resources.
- Consider the downstream services in architectural decisions.
- Optimization should be a continuous cycle of improvement.
- Prioritize changes that make the greatest improvements first.
The Optimizing your AWS Lambda costs blog series reviews operational and architectural guidance. It can be applied to existing Lambda functions and those that you develop in the future.
Introduction to Lambda pricing
Lambda pricing is calculated as a combination of:
- Total number of requests
- Total duration of invocations
- Configured memory allocated
When you optimize Lambda functions, each of these components impacts the total monthly cost. This pricing applies after you exceed the AWS Free Tier that is offered for Lambda.
Right-Sizing
Right-sizing is a good starting point in the process of cost optimization. This exercise helps to identify the lowest cost for applications without affecting performance or requiring code changes.
For Lambda, this is accomplished by configuring the memory for a function, ranging anywhere from 128 MB up to 10,240 MB (10 GB). By adjusting the memory configuration, you also adjust the amount of vCPU that is available to the function during invocation. Tuning these settings provides memory- or CPU-bound applications with access to additional resources during the execution, which may lead to an overall reduced duration of invocation.
Identifying the optimal configuration for your Lambda functions may be manually intensive, especially if changes are made frequently. The AWS Lambda Power Tuning tool provides a solution powered by AWS Step Functions that can help identify the appropriate configuration. It analyzes a set of memory configurations against an example payload.
In the following example, as the memory increases for this Lambda function, the total invocation time improves. This leads to a reduction in the cost for the total execution without affecting the original performance of the function. For this function, the optimal memory configuration for the function is 512 MB, as this is where the resource utilization is most efficient for the total cost of each invocation. This varies per function, and using the tool on your Lambda functions can identify if they benefit from right-sizing.

This exercise should be completed regularly, especially if code is released frequently. Once you have identified the appropriate memory setting for your Lambda functions, you should add right-sizing to your processes. The AWS Lambda Power Tuning tool generates programmatic output that can be used by your CI/CD workflows during the release of new code, allowing the automation of memory configuration.
Performance efficiency
A key component to Lambda pricing is the total duration of the invocation. The longer the function takes to run, the more it costs and the higher the latency in your application. For this reason, it is important to ensure the code you write is as efficient as possible and follows the Lambda best practices.
At a high level, to optimize code :
- Minimize deployment package size to its runtime necessities. This reduces the amount of time it takes for the package to be downloaded and unpacked.
- Minimize the complexity of dependencies. Simpler frameworks often load faster.
- Take advantage of execution reuse. Initialize SDK clients and database connections outside the function handler, and cache static assets locally in the /tmp directory. Subsequent invocations can reuse open connections and resources in memory and in /tmp.
- Follow general coding performance best practices for your chosen language and runtime.
To help visualize the components of your application and identify performance bottlenecks, use AWS X-Ray with Lambda. You can enable X-Ray active tracing on new and existing functions by editing the function configuration. For example, with the AWS CLI:
aws lambda update-function-configuration --function-name my-function \
--tracing-config Mode=ActiveThe AWS X-Ray SDK can be used to trace all AWS SDK calls inside Lambda functions. This helps to identify any bottlenecks in the application performance. The X-Ray SDK for Python can be used to capture data for other libraries such as requests, sqlite3, and httplib, as shown in the following example:
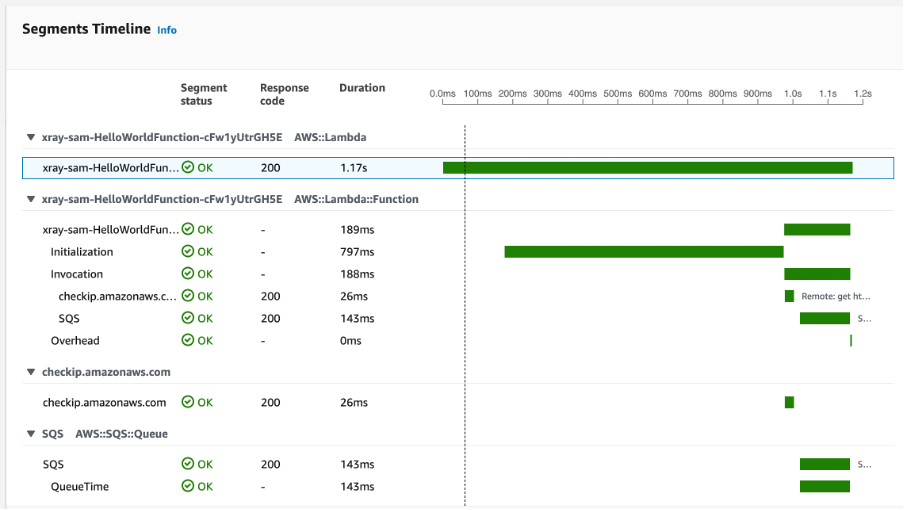
Amazon CodeGuru Profiler is another tool that can help with code optimization. It uses machines learning algorithms to help find the most expensive lines of code and suggests ways to improve efficiency. It can be enabled on existing Lambda functions by enabling code profiling in the function configuration.
The CodeGuru console shows the results as a series of visualizations and recommendations.

Use these tools together with the documented best practices to evaluate your code’s performance when developing your serverless applications. Efficient code often means faster applications and reduced costs.
AWS Graviton2
In September 2021, Lambda functions powered by Arm-based AWS Graviton2 processors became generally available. Graviton2 functions are designed to deliver up to 19% better performance at 20% lower cost than x86. In addition to the lower billing cost when using Arm, you could also see a reduction in the function duration due to the CPU performance improvement, reducing costs even further.
You can configure both new and existing functions to target the AWS Graviton2 processor. Functions are invoked in the same way and integrations with services, applications and tools are not affected by the architecture change. Many functions only need the configuration change to take advantage of the price/performance of Graviton2. Others may require repackaging to use Arm-specific dependencies.
It’s always recommended to test your workloads before making the change. To see how much your code benefits from using Graviton2, use the Lambda Power Tuning tool to compare against x86. The tool allows you to compare two results on the same chart:

Provisioned concurrency
Where customers are looking to reduce their Lambda function cold starts or avoid burst throttling, provisioned concurrency provides execution environments that are ready to be invoked. It can also reduce total Lambda cost when there is a consistent volume of traffic. This is because the provisioned concurrency pricing model offers a lower total price when it is fully used.
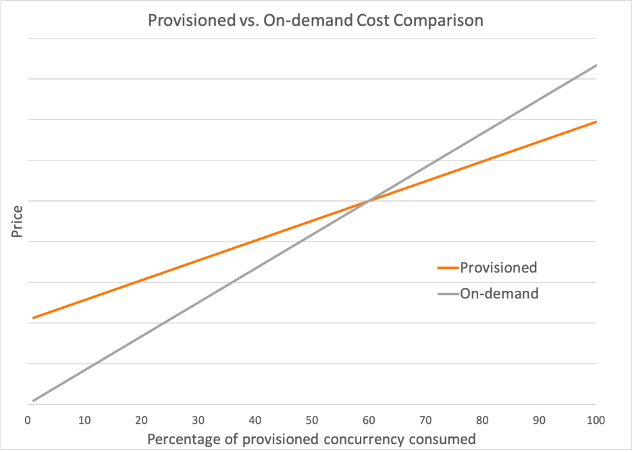
Similar to the standard Lambda function pricing, there are price components for total requests, total duration, and memory configuration. In addition, there is the cost of each provisioned concurrency environment (based on its memory configuration). When this execution environment is fully utilized, the combined cost of the invocation and the execution environment can offer up to 16% savings on duration cost when compared to the regular on-demand pricing.
If you cannot maximize usage in an execution environment, provisioned concurrency can still offer a lower total price per invocation. In the following example, once it’s consumed for more than 60% of the available time, it becomes cheaper than using the on-demand pricing model. The savings increase in line with capacity usage.
To identify the invocation baseline of a Lambda function, look at the average concurrent execution metrics per hour over the previous 24 hours. This helps you to find a consistent baseline throughout the day where you are consistently using multiple execution environments.
For Lambda functions where peak invocation levels are only expected during particular windows of time, take advantage of a scheduled scaling action. Where traffic patterns are not easy to determine, you can implement Application Auto Scaling to adjust based on the current level of utilization.
Compute savings plans
AWS Savings Plans is a flexible pricing model offering lower prices compared to on-demand pricing, in exchange for a specific usage commitment (measured in $/hour) for a one- or three-year period.
Compute Savings Plans include Amazon EC2, AWS Fargate and Lambda. Lambda usage for duration and provisioned concurrency are charged at a discounted Savings Plans rate of up to 17% for a 1- or 3-year term.
You can implement Savings Plans without any function code or configuration changes. They can be a simpler way to save money for Lambda-based workloads. Before deciding to use a savings plan, analyze previous patterns to understand any variations in your month to month usage.
Conclusion
This blog post explains how Lambda pricing works and how right-sizing applications and tuning them for performance efficiency offers a more cost-efficient utilization model. The results can also reduce latency, creating a better experience for your end users.
The post explores how architectural changes such as moving to Graviton2 and configuring provisioned concurrency can provide cost reductions for the same operations. Finally, you can use Compute Savings Plans to add an additional cost reduction once you establish a baseline of usage per month.
Part 2 introduces further optimization opportunities for reducing Lambda invocations, moving to an asynchronous model, and reducing logging costs.
For more serverless learning resources, visit Serverless Land.