AWS Compute Blog
Serverless generative AI architectural patterns – Part 2
In Part 1 of this series, we discussed three patterns and general best practices for building real-time, interactive, generative AI applications. However, not all generative AI workflows require immediate responses. This post explores two complementary approaches for non-real-time scenarios: buffered asynchronous processing for time-intensive individual requests, and batch processing for scheduled or event-driven workflows.
Buffered asynchronous processing is useful for use cases demanding time-consuming processing to yield the most precise outcomes. Consequently, these benefit from an interactive delayed request response cycle that can be achieved through a buffered asynchronous integration. Examples include generating video or music from text, conducting medical or scientific analysis and visualization, creating complete virtual worlds for gaming or the metaverse, fashion and lifestyle graphics generation, and more.
The second approach addresses a different challenge: processing extensive datasets on a schedule or when specific events occur. Examples include bulk image enhancement and optimization, weekly or monthly report generation, weekly customer review analysis, and social media content creation. These non-interactive, batch-oriented generative AI workflows necessitate repeatability, scalability, parallelism, and dependency management to manage large data volumes. The non-interactive batch implements this processing pattern.
Pattern 4: Buffered asynchronous request response
This asynchronous pattern uses event-driven architectures to enhance application scalability and reliability. This approach offers several advantages, including improved performance through concurrent processing, enhanced scalability through group processing, and better reliability through decoupled components. This pattern is particularly effective for handling high-volume requests or long-running processes.
The implementation typically involves message queuing services like Amazon Simple Queue Service (Amazon SQS) to buffer requests and manage processing loads. This pattern can be particularly effective when combined with WebSocket APIs for interactive updates, alleviating the need for client-side polling. For complex scenarios involving multiple LLM models, the multimodal fan-out pattern (refer pattern 5 below) using Amazon EventBridge or Amazon Simple Notification Service (Amazon SNS) enables parallel processing across different endpoints. This pattern can be implemented through several architectural approaches.
REST APIs with message queuing
To limit scaling challenges with your LLM endpoint, use an Amazon SQS queue to buffer messages. The frontend sends messages to Amazon API Gateway REST endpoints, which pushes them to the queue. API Gateway returns an acknowledgement and a unique identifier (the message ID) to the frontend. The middleware running on compute services like AWS Lambda, Amazon EC2 or AWS Fargate processes messages in batches, creating entries in Amazon DynamoDB for each record. It then calls LLM endpoints to generate responses, storing the results back in the DynamoDB table with the corresponding message ID. The frontend polls the API Gateway endpoint to check if the response message is generated, querying the DynamoDB table using the message ID. This pattern helps overcome the API Gateway limit of 29 seconds for the request response cycle. For an example implementation, see API Gateway REST API to SQS to Lambda to Bedrock. A similar solution can be implemented using AWS AppSync GraphQL APIs instead of Amazon API Gateway. The following diagram illustrates an example architecture.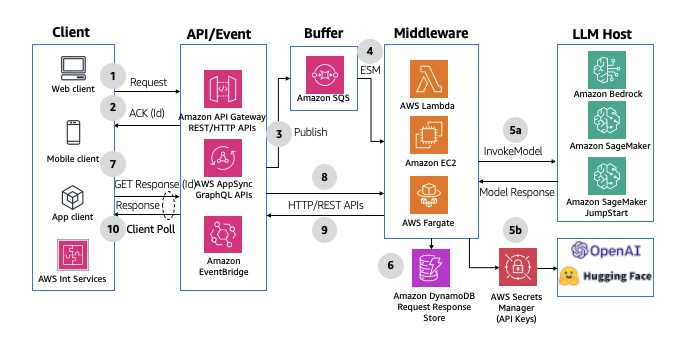
Fig 11: Buffered asynchronous request response using Amazon API integrations services and Amazon SQS queues
WebSocket APIs with message queuing
This is a variation of the previous pattern but uses API Gateway WebSocket APIs instead of REST endpoints. In this pattern, instead of the frontend client having to continuously poll for the response, the middleware sends back the result back to the client after it is generated. This uses WebSocket omni-channel communication to accept and respond to messages, all maintained by API Gateway. For an example implementation, refer to the aws-apigatewayv2websocket-sqs AWS Solutions Construct. The following diagram illustrates this architecture.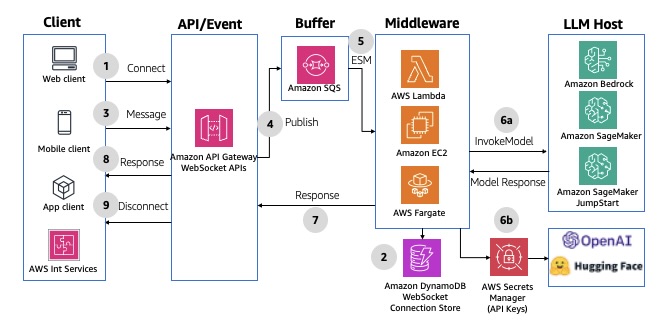
Fig 12: Buffered asynchronous request response using Amazon API Gateway WebSocket APIs and Amazon SQS queues
Pattern 5: Multimodal parallel fan-out
For use cases that require interacting with multiple LLM models, data sources, or agents, you can use the messaging fan-out pattern, which distributes messages to multiple destinations in parallel. You can use Amazon EventBridge or Amazon SNS to send specific messages to target LLM endpoints or agents using rules-based message fan-out. This pattern decomposes complex tasks into sub-tasks and executes them in parallel, minimizing overall generation time. For an example implementation, see SNS to SQS fanout pattern. The following diagram illustrates the architecture.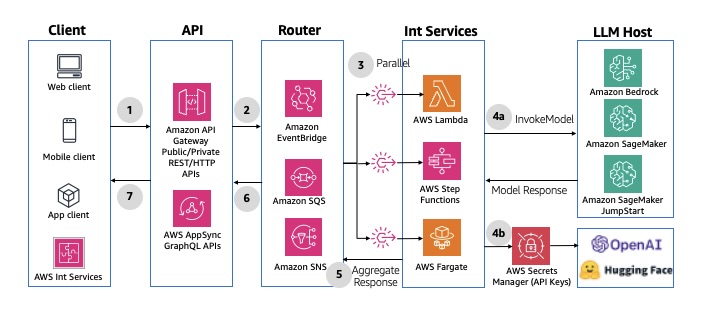
Fig 13: Multimodal parallel fan-out using Amazon API integration and messaging services
Pattern 6: Non-interactive batch processing
Non-interactive batch processing pipelines are ideal when you need to process large volumes of data efficiently without real-time user interaction, typically running on a scheduled basis to maximize resource usage and throughput. This pattern uses AWS Step Functions, AWS Glue, or other compute services to create a serverless data processing and inferencing pipeline. The data integration, transformation, and inference jobs can be triggered based on a schedule or occurrence of events. This pattern offers higher throughput, optimizes on resource usage, and enhances automation through volume processing. For an example implementation, refer to the aws-sqs-pipes-stepfunctions AWS Solutions Construct. The following diagram illustrates an example architecture.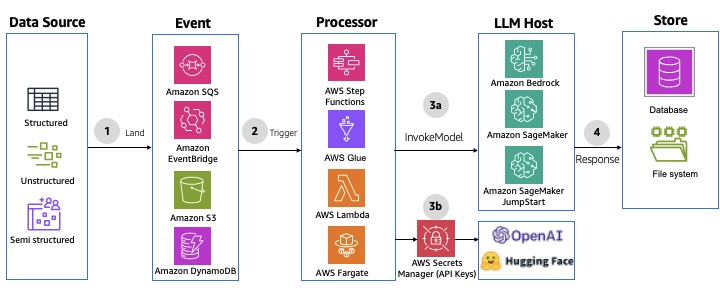
Fig 14: Non-interactive batch processing using Amazon data integration services
Conclusion
In this post (series), you learned six architectural patterns on building generative AI applications using AWS serverless services. These patterns implement interactive real-time, asynchronous or batch-oriented workloads without a lot of operational overhead. You can combine these patterns to deliver modern cloud native applications. Given the current trajectory of innovation in this domain, it is anticipated that further blueprints will emerge to augment or evolve these in the future.The successful deployment of production-ready generative AI applications requires careful consideration of architectural patterns and implementation approaches. You must evaluate various factors such as response time, scalability, integration needs, reliability, and user experience when selecting appropriate patterns or a combination of them.
To learn more about Serverless architectures see Serverless Land.