Containers
Implementing usage and security reporting for Amazon ECR
When managing container workloads, maintaining centralized observability of your container registry is essential for security and efficient resource utilization. Amazon Elastic Container Registry (ECR) provides metrics at both image and repository levels, which are key to building consolidated observability. This post guides you through the process of centralizing these metrics into basic but comprehensive reports that include cost breakdowns, usage metrics, security scan results, and compliance status across all repositories. With consolidated observability, you can better understand usage patterns, identify security risks, and prioritize resources that need to align with security requirements and optimization best practices.
In this post, we will use this sample code to generate two reports: 1) a Repository Summary report that contains all Amazon ECR repositories in a registry with attributes that can be used to track and optimize cost, usage, and OS vulnerabilities from Amazon ECR image scanning. 2) an Image-Level report that contains all images in a specific repository with attributes that can be used to dive deep on the findings from the first report.
These reports help identify unused repositories and images for cost reduction, and highlight repositories with the most or heaviest images and those lacking lifecycle policies. They provide insights into storage usage, security scan statuses, and critical security findings across repositories, thus enabling better cost management, policy implementation, and prioritized security remediation.
Solution overview
In this section, we provide a hands-on example that demonstrates how to run this sample code, which generates detailed reports about your Amazon ECR repositories. The two types of reports are described as follows.
Repository Summary: A summary of the repositories in a registry that contains the following attributes:
| Name | Description |
| repositoryName | The name of the repository |
| createdAt | The date when the repository was created |
| scanOnPush | Whether images are scanned after being pushed to a repository |
| totalImages | The total number of images/artifacts in the repository |
| totalSize(MB) | The total size of the images/artifacts in the repository in MB |
| hasBeenPulled | When any image in the repository has been pulled at least once |
| lastRecordedPullTime | The date when an image in the repository was last pulled |
| daysSinceLastPull | The number of days since the repository recorded its last image pull |
| lifecyclePolicyText | The lifecycle policy text of the repository |
This information helps identify which repositories have the most images, which are the heaviest (with respect to the total size of images/artifacts), and which lack lifecycle policies. These factors significantly impact the cost of maintaining the repository. Finally, this report allows you to see whether images are scanned after being pushed to a repository. Enabling container scanning allows organizations to significantly reduce their security risks and maintain a strong security posture in their containerized environments.
The totalSize (MB) field should not be used to estimate total storage cost on Amazon ECR, because this does not include the optimization benefit from Amazon ECR sharing the common image layers within a repository. This field may provide insights into repositories that are consuming more storage and thus may be candidates for optimization.
Image-Level: Contains key attributes of all images/artifacts within a repository:
| Name | Description |
| repositoryName | The name of the repository |
| imageTags | The tags of the image |
| imagePushedAt | The date when the image was pushed |
| imageSize(MB) | The size of the image in MB |
| imageScanStatus | The security scan status of the image |
| imageScanCompletedAt | The date when the image was last scanned |
| findingSeverityCounts | The severity counts of the security findings in the image |
| lastRecordedPullTime | The date when the image was last pulled |
| daysSinceLastPull | The number of days since the image was last pulled |
This information helps analyze the images and their storage usage in detail, which aids in identifying unused images that can be deleted to reduce costs. The contents can also provide insights to implement more effective lifecycle policies. For example: 1/clean untagged images, 2/keep a certain number of images per repo, or 3/remove older images.
Furthermore, this report provides consolidated security findings data for Amazon ECR basic scanning users, helping them prioritize remediation efforts. For Amazon ECR enhanced scanning users, we recommend using the security features and findings available through Amazon Inspector.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- Finch (or any other container build tool) installed in your environment
- AWS Command Line Interface (AWS CLI) installed in your environment
- An AWS Identity and Access Management (IAM) principal (user or role) with this policy
- Git installed in your environment
Walkthrough
The following steps walk you through this solution.
Setup the container image
Clone the repository and build the container
This command builds an image with the following parameters:
-t ecr-reporter:v0.1.0: Tags the image with the name ecr-reporter and the tag v0.1.0. You can replace the name and tag with any values you want..: Uses the Dockerfile in the current directory as the build context.
When working with Docker, replace finch with docker in the command while keeping all other parameters the same.
Run the Repository Summary report
- Run the following command to generate the repositories summary report:
In the command, we are using a profile named
aws-samplesand the AWS Region was set tous-east-1. We also set a volume to persist the report in our local environment (/Pathin our case) even after the container is stopped. The container has more parameters that can be set:LOG_VERBOSITY: Set toDEBUG,INFO,WARNING, orERROR(default:INFO)DECIMAL_SEPARATOR: Set to.or,for CSV number formatting (default:.)EXPORT_FORMAT: Delimitation format to use for report generation. Set to csv, json, or parquet (default: csv).
You can see the complete list of parameters to run the container in the GitHub repository.
When working with Docker, replace
finchwithdockerin the command while keeping all other parameters the same. - Review the Repository Summary report
One CSV file with this report is created in the output directory that you specified. This report looks like the following:
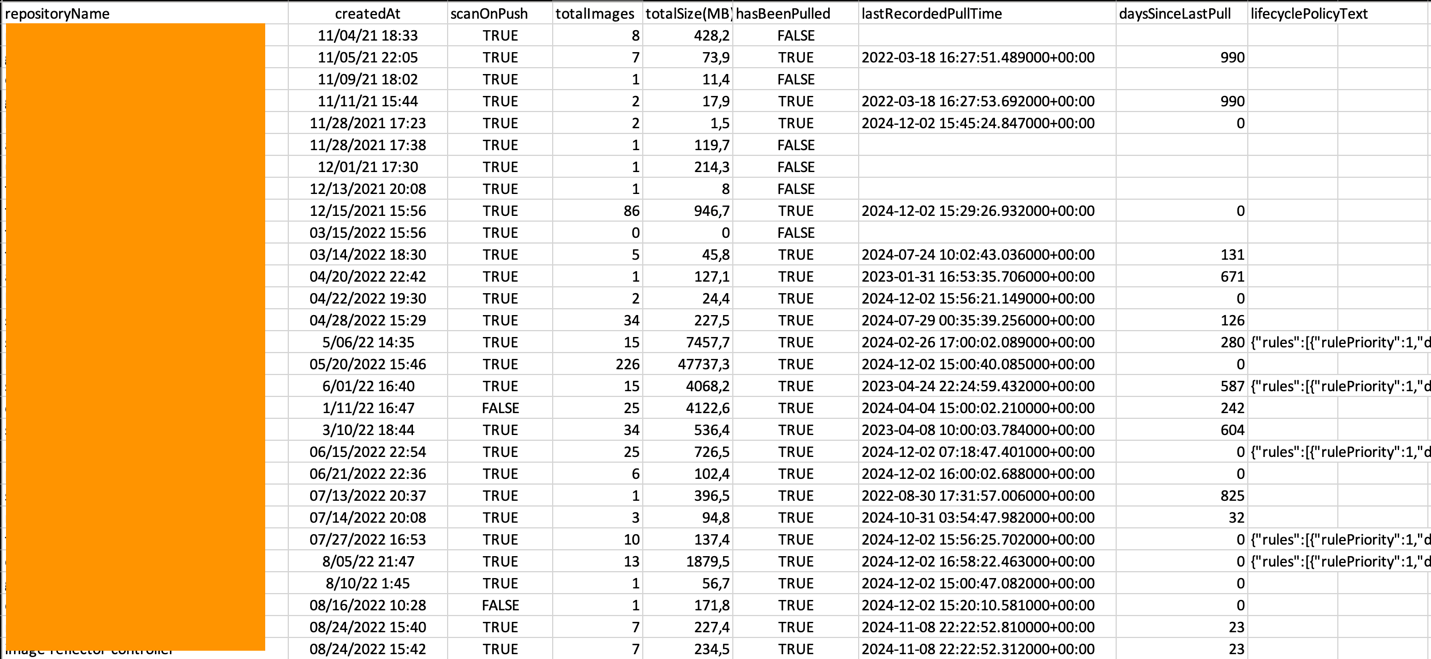
Figure 1: Repository Summary report with sample content
Run the Image-Level report
- Run the following command to generate the image-level report for repository
foobar:
To generate an image-level report, set the environment variable REPORT to the name of the repository. You can see the complete list of parameters to run the container in the GitHub repository.
When working with Docker, replace finch with docker in the command while keeping all other parameters the same.
- Review Image-Level report
One CSV file with this report is created in the output directory that you specified. This report looks like the following:
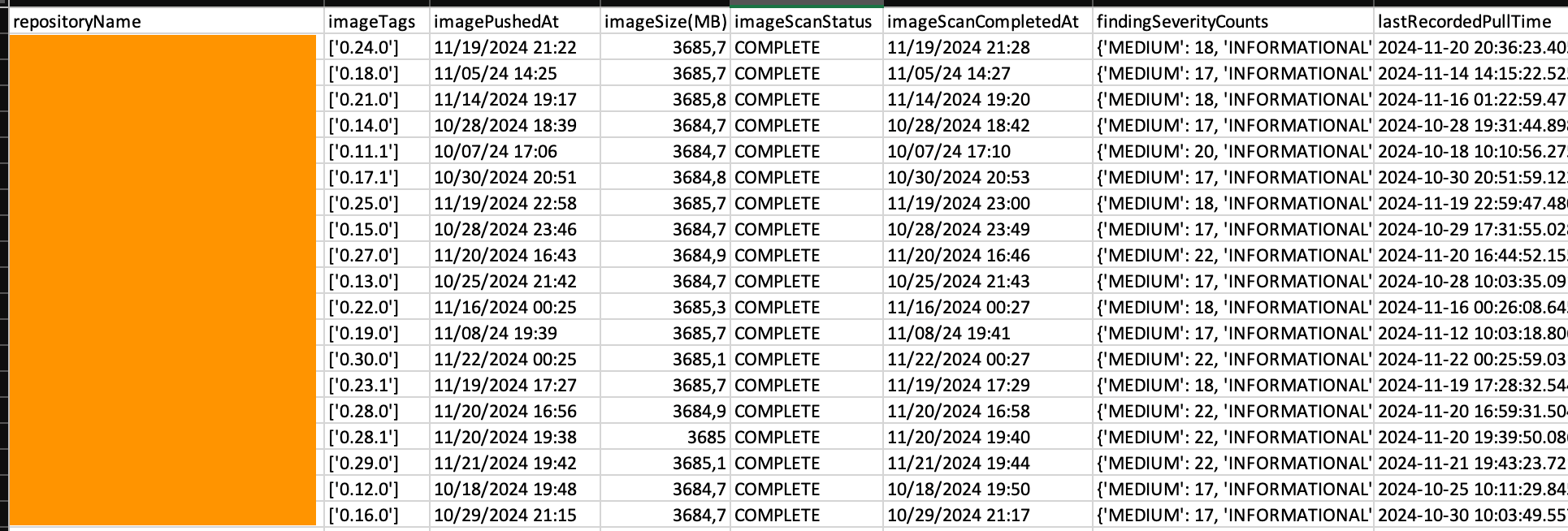
Figure 2: Image-level report with sample content
Further work (optional)
The following steps are optional.
Schedule report generation
You can periodically run this code in any of the AWS container services as 1) a cronjob in Amazon Elastic Kubernetes Service (Amazon EKS) for which you can use these instructions as reference, or 2) a scheduled task in Amazon Elastic Container Service (Amazon ECS).
Use Amazon Athena to analyze reports
You can also store the reports in Amazon S3, which you can query using Amazon Athena. To do so, you need to set this policy to the IAM principal to upload objects to a specific bucket (make sure to specify your bucket when creating the policy). When you have attached the policy, you can generate each report by setting the environment variable AMAZON_S3_BUCKET to the name of the bucket:
When working with Docker, replace finch with docker in the command while keeping all other parameters the same.
After the report is generated, you can analyze its content using Athena. This example assumes you have configured Athena before. If not, you can follow this getting started guide and then come back to continue.
- Create a database to hold the schemas for the Repository Summary report named
ecr_repository_summary. Run the following query in the Athena Query Editor:
- Create the table schema for the Repository Summary report
To show the details of the Repository Summary report, you must create a table inside this database that holds the schema of the report stored in Amazon S3. To do this, you can run the following query inside the Athena Query Editor:
Remember to substitute the <s3 bucket name> with the name of the bucket that you created to store the generated reports.
After running this query, you have a new table named repo_summary that you can query to get the records of the data inside the Repository Summary report CSV that you generated and saved into the bucket.
- Query the new table to see the data
This outputs something like the following:
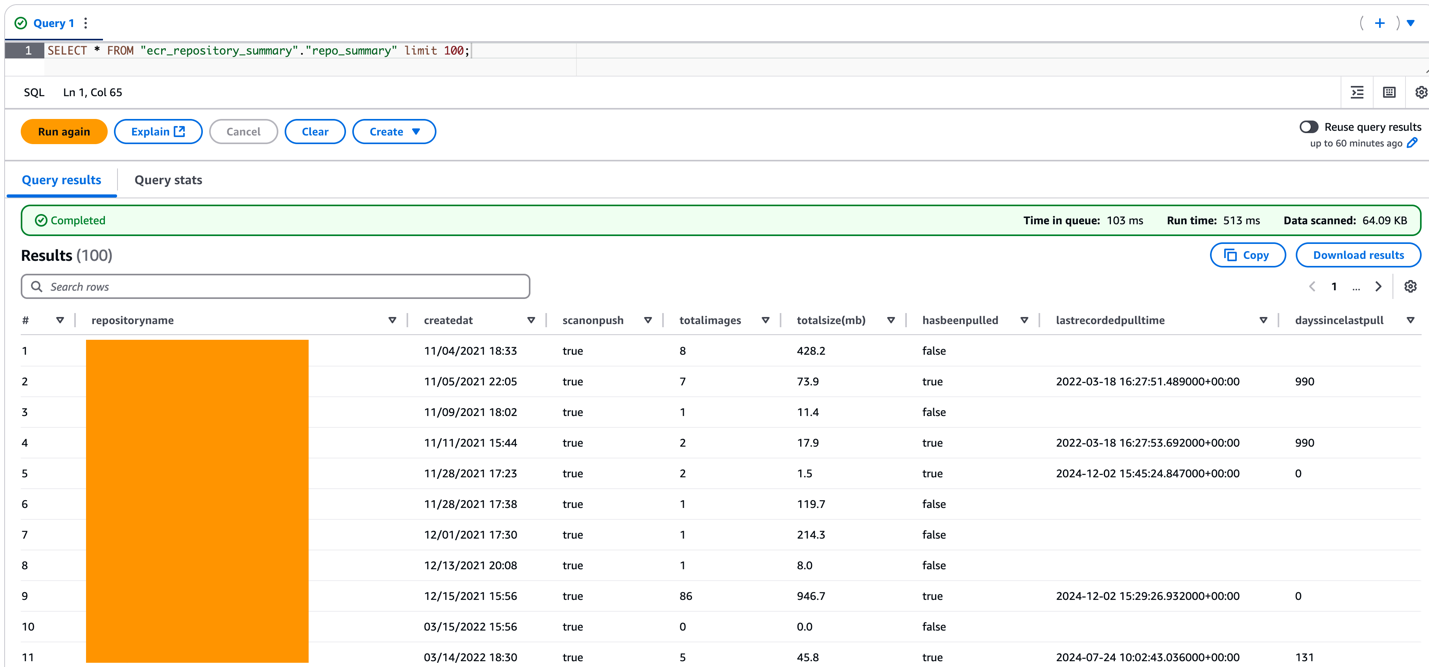
Figure 3: Using Amazon Athena to navigate the Repository Summary report with SQL
- Gather insights and analyze
Now that you have an easy way to query the data, you can use it to get relevant insights that can help you make informed decisions for cost optimization, hygiene, and the maintenance of your Amazon ECR repositories. For example, you can quickly find those repositories that sum up the most in storage using the following query:
Or you can find those with images that have never been pulled:
Or you can find those that have not been pulled in more than a year so that you can remove stale resources:
In other words, you can get as creative as you want with this data! These instructions used the csv export format. Using parquet and json is similar, but they may need some minor changes that are outside of the scope of this post.
Cleaning up
You will be charged to your AWS account when storing your reports in Amazon S3 and using Amazon Athena to analyze them. If you decide to clean up to avoid unwanted charges to your AWS account, delete all the AWS resources created during this deployment:
- Delete Amazon S3 buckets with their content
- Clean up Athena resources
- Detach IAM policies attached to either an IAM user or role
Conclusion
Optimizing AWS costs while maintaining performance and innovation is achievable through effective observability. Using insights into Amazon ECR allows organizations to make data-driven decisions that enhance their container operations. Detailed visibility into repositories—such as cost breakdowns, usage metrics, security scan outcomes, and compliance statuses—means that teams are well-equipped to streamline their container infrastructure while accelerating innovation.
Using the sample code provided in this post allows you to generate comprehensive reports that not only provide insights into your Amazon ECR repositories but also allow dive deeper into individual image details. These reports enable you to proactively review and optimize your Amazon ECR usage for cost-effectiveness, efficient resource usage, and enhanced security. We encourage you to try the sample code and share your feedback. Your input helps us improve and enhance it to better serve the AWS containers community.
For questions, feature requests, or to contribute to the project, visit our GitHub repository.
About the authors
 Herbert Gomez is a Principal Solutions Architect in Medellin, Colombia.
Herbert Gomez is a Principal Solutions Architect in Medellin, Colombia.
 Manuel Ortiz is a Sr. Solutions Architect in San Juan, Puerto Rico.
Manuel Ortiz is a Sr. Solutions Architect in San Juan, Puerto Rico.
 Andrés Victoria is a Sr. Solutions Architect in Bogota, Colombia.
Andrés Victoria is a Sr. Solutions Architect in Bogota, Colombia.