AWS Database Blog
Amazon Ads upgrades to Amazon ElastiCache for Valkey to achieve 12% higher throughput and save over 45% in infrastructure costs
Amazon Ads enables businesses to meaningfully engage with customers throughout their shopping journey, reaching over 300 million audience in the US alone. Delivering the right ad to the right customer in real time at a global scale requires highly available, low-latency infrastructure capable of processing tens of millions of requests per second.
In this post, we will provide a behind-the-scenes look at how Amazon Sponsored Products, one of the core advertising products at Amazon, relies on Amazon ElastiCache to deliver billions of ad impressions a day using a custom multi-cluster architecture that coordinates data across large-scale cache deployments. We also walk through how upgrading from ElastiCache for Redis to ElastiCache for Valkey provided improved performance while reducing infrastructure cost by over 45%, with zero-downtime while maintaining strict latency and availability requirements.
The challenge
Amazon Sponsored Products uses in-memory caching to deliver billions of ad impressions a day to hundreds of millions of our global shoppers, peaking at tens of millions of read requests per second across terabytes of data. We consistently deliver p99 latencies under 5ms with 99.99% availability—even during traffic surges like Prime Day or the holiday season. Furthermore, we hold strict latency and availability requirements even as traffic, throughput, and memory footprint continues to grow.
At this scale, continuously optimizing for performance and cost is essential. Even small efficiency gains can translate into significant savings and improved responsiveness for our shoppers. However, with the strict availability and latency requirements, any disruption to our caching layer directly impacts ad delivery and thus the shopper experience. To facilitate fast deployment and improvements to ad retrieval methods we designed a multi-tenant environment that must maintain isolation, while enabling resource utilization across diverse workloads.
To meet these requirements at scale, we rely on Amazon ElastiCache, which provides the necessary reliability, flexibility, and operational controls to execute system upgrades and optimizations without requiring downtime or service degradation.
The solution
To achieve the scale and performance we required, we invested in two keys. First, we built a multi-cluster architecture that isolates workloads and scales each one independently. Second, we adopted ElastiCache for Valkey through a zero-downtime migration path that strengthens reliability while improving efficiency.
Multi-cluster architecture for scale
Our cache management service, Horus, uses ElastiCache to scale out a cluster across 500 nodes. To keep pace with the ever-increasing data volume, we developed a multi-cluster solution. Different ad retrieval techniques are distributed across cache clusters depending on data volume and scaling needs. For example, if one of the methods needs a large cache space, we create a dedicated cluster for it, allowing for independent space planning, scaling, performance and cost monitoring.
The Horus cache client uses AWS AppConfig to dynamically route each retrieval method to its cache cluster and employs multi-threading to issue parallel cache calls. Within each child thread, failures are handled in isolation so that a single key failure does not impact others, ensuring requests are routed appropriately and system resilience is maintained without cascading impact. The following diagram provides a high-level view of how Horus coordinates dynamic request routing and cross-cluster data publication within its multi-cluster ElastiCache architecture.
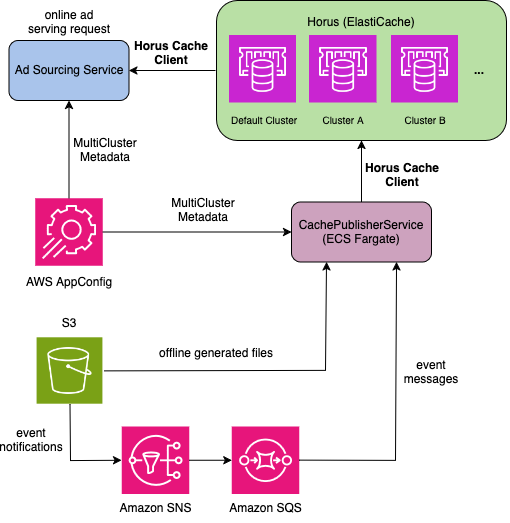
Upgrading to ElastiCache for Valkey with zero downtime
While evaluating the option of migrating to Graviton based clusters, we wanted a solution that would provide zero disruption to our ad delivery and provide the option of instantaneous rollbacks in case of any failure. The move to ElastiCache for Valkey 8.0 allowed us to meet both goals.
We first used ElastiCache’s streamlined deployment capabilities to create a zero downtime migration plan. The support for Valkey as a drop-in replacement for Redis OSS eliminated the need for any application code changes. We then provisioned new Valkey 8.0 clusters on Graviton-based instances, which were spun up in parallel to our existing Redis based clusters. The comprehensive Amazon CloudWatch metrics emitted by ElastiCache allowed monitoring both clusters and provided baseline performance metrics before starting the migration.
Next, a dual-write implementation configured the Horus cache client to write to both Redis and Valkey clusters simultaneously. This approach ensured data consistency across both clusters and validated that all new data was properly replicated, creating a safety net for the transition.
In the following code sample, we show the implementation of MultiWriteCacheClient, a specialized cache wrapper that used a multi-write pattern to simultaneously publish data to multiple cache clusters. It uses CompletableFuture for parallel execution across all cache clusters with a 100ms timeout and aggregates exceptions to ensure partial failures don’t block other operations. The client deliberately blocks read operations since those are handled by separate clients during the migration phase, while providing proper resource cleanup when closing underlying connections.
We then gradually shifted the read traffic to the new Valkey cluster while closely monitoring performance metrics and error rates. Throughout this process, we had the ability to roll back to the Redis cluster as a backup. After successful validation of the Valkey cluster under full load, the old Redis cluster was decommissioned, and resources were reclaimed. Throughout the migration we had no impact on either service availability or performance, ensuring continuous ad delivery for our shoppers.
With the cost efficiency of Graviton-based instances, Valkey pricing advantage, and performance advantages over ElastiCache for Redis, this migration effort reduced our infrastructure spend by over 45% while improving throughput by 12%.
Considerations
Evaluating single and multi-cluster: While the multi-cluster architecture provides significant benefits, it introduces additional operational overhead that must be carefully managed. This approach is most suitable for larger cache systems (>30TB), while smaller cache requirements (<30TB) may be better served by a single cluster setup for operational simplicity and reduced maintenance needs.
Ensuring data consistency: Data consistency presents another important consideration during transitions. The dual-write approach requires careful monitoring to ensure consistency across environments. Maintaining data integrity across cluster boundaries is critical to prevent service degradation or incorrect ad delivery.
Performance monitoring: Careful performance monitoring is essential when operating across multiple clusters. We relied on CloudWatch metrics emitted by ElastiCache to track cache health, including engine CPU utilization, memory utilization, read/write transactions per second (TPS), keys reclaimed or expired, and current connection counts. On the client side, we captured detailed service performance metrics such as cache hit rate and TPS across multiple dimensions (cache cluster, sourcing technique, marketplace, widget, and more), as well as read/write latencies and error rates. These metrics were visualized through dashboards and supported by alerting systems, enabling us to quickly detect anomalies and proactively address issues before it causes service degradation.
Cost Savings: Balancing cost against performance is always a key consideration, especially at the scale Horus operates. While migrations—such as adopting Valkey 8.0 and moving to Graviton instances—require careful planning, the long-term gains can be substantial. In this case, the performance improvements and infrastructure cost savings delivered by Valkey 8.0 clearly outweighed the short-term complexity of the migration, making it a high-impact upgrade that paid off quickly.
Conclusion
The successful migration to ElastiCache for Valkey, combined with a scalable multi-cluster architecture, helped Amazon Sponsored Products meet the growing demands of real-time ad delivery at Amazon scale. By leveraging ElastiCache’s performance, observability, and ease of use—together with Valkey’s improved memory efficiency and throughput—we executed a zero-downtime upgrade without any changes to application code or disruption to ad delivery.Through this migration, we reduced infrastructure spend by over 45% while improving throughput by 12%.
More importantly, the upgrade established a recipe for modernizing cache infrastructure with minimal risk. Whether you’re looking to boost performance, cut costs, or improve scalability, ElastiCache for Valkey provides the flexibility and reliability to do so at any scale.
Learn more and get started with Amazon ElastiCache for Valkey by visiting the ElastiCache product pages and documentation. For a step-by-step guide to upgrade to the latest version of ElastiCache for Valkey, see the upgrade documentation.