AWS Database Blog
Build interactive graph data analytics and visualizations using Amazon Neptune, Amazon Athena Federated Query, and Amazon QuickSight
Customers have asked for a way to interact with graph datasets in Amazon Neptune using business intelligence (BI) tools such as Amazon QuickSight. Although some BI tools offer generic HTTP connectors that allow you to define a set of REST API calls to extract data from REST endpoints, you have to predefine either Gremlin or SPARQL queries for this purpose. That defeats the purpose of using the abstraction layer of BI tools for data analysts.
In this post, we show how to query and visualize property graph datasets in a Neptune graph database using the Amazon Athena Neptune Connector and QuickSight.
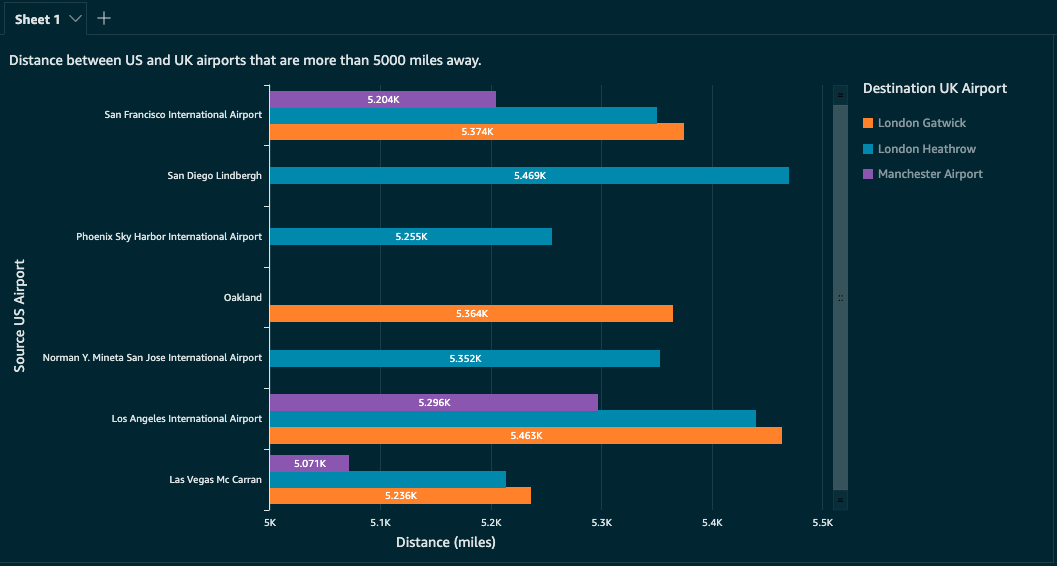
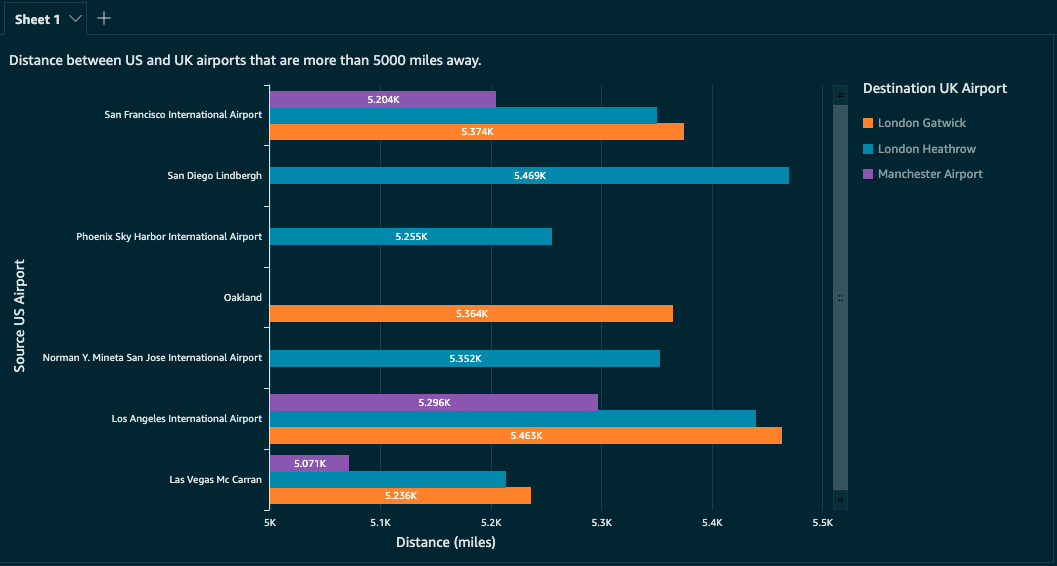
As an example, we create a QuickSight dashboard (see the following screenshot) to show the distance between airports in the US and UK where the distance is greater than 5,000 miles.
Solution overview
First, some background on the key services and features that we use in this solution:
- Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. The core of Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with millisecond latency.
- Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to set up or manage, and you can start analyzing data immediately.
- Amazon Athena Federated Query is an Athena feature that enables data analysts, engineers, and data scientists to run SQL queries across data stored in relational, non-relational, object, and custom data sources. With federated queries, you can submit a single SQL query and analyze data from multiple sources running on premises or hosted on the cloud.
- The Athena Neptune Connector is built using the Amazon Athena Query Federation SDK. It allows Athena to communicate with your Neptune graph database instance, making your Neptune graph data accessible by SQL queries.
- QuickSight is a scalable, serverless, embeddable, machine learning (ML) powered BI service built for the cloud. QuickSight lets you easily create and publish interactive BI dashboards that include ML-powered insights.
- We also use the AWS Glue Data Catalog, Amazon S3, and AWS Lambda in this solution.
We show you how to deploy a Neptune cluster and load a sample graph dataset, and deploy and configure the Athena Neptune Connector and dependencies that can interact with an existing or newly created Neptune cluster. We also show how to configure QuickSight to interact with Neptune via the Athena Neptune Connector.
The following diagram illustrates the high-level architecture and simplified process flow.
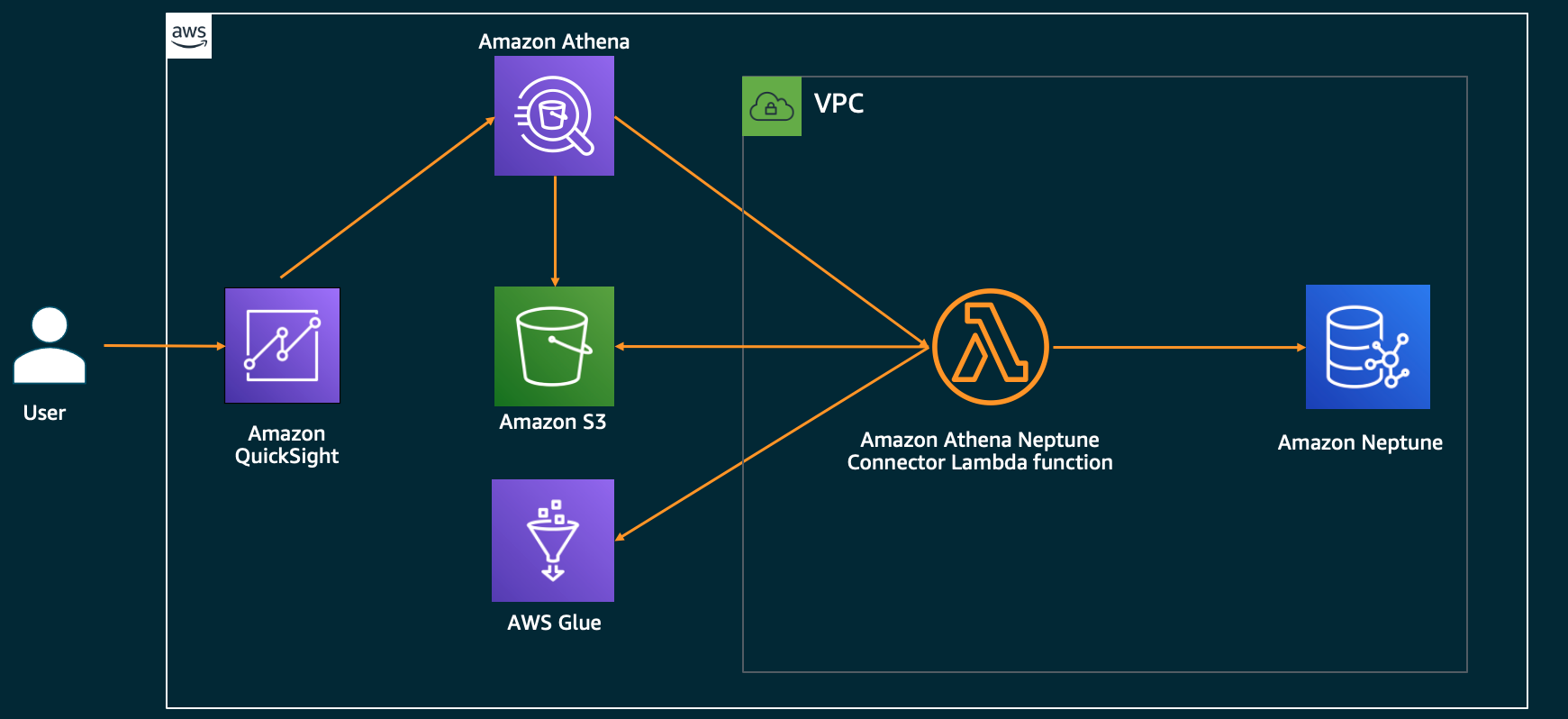
The process flow contains the following steps:
- A user signs in to QuickSight and accesses the analysis or dashboard connected to an Athena dataset.
- QuickSight sends the associated SQL query to Athena.
- The Athena Federated Query functionality talks to the Athena Neptune Connector Lambda function to fetch the data from Neptune. In the case of graph datasets, where the schema or properties of the graph nodes and edges may vary, we need to predefine the database and the table schemas. We use the Data Catalog to predefine these and let the connector Lambda function retrieve the details from the Data Catalog.
- The Athena Neptune Connector Lambda function converts the incoming SQL query into a Gremlin traversal and sends the query to Neptune. It then converts the graph traversal output into a SQL result set by mapping it to the predefined schema in the Data Catalog, and returns that to Athena and thereby to QuickSight for visualization purposes.
Any data fetched by the connector Lambda function that goes beyond the function’s limits, like memory allocation, is spilled over to an S3 bucket to be read by Athena later.
Create a Neptune cluster and load sample data
You can skip this step if you have an existing Neptune cluster and property graph dataset in it that you want to use. Make sure you have an internet gateway and NAT gateway in the VPC hosting your Neptune cluster. The private subnets in which the Athena Neptune Connector Lambda function runs should have a route to the internet via this NAT gateway. The Athena Neptune Connector Lambda function uses the NAT gateway later to talk to AWS Glue.
To create a Neptune cluster and load the sample air routes property graph dataset into it, we follow the instructions in the GitHub repo.
After the Neptune cluster and notebook are set up and the data load is complete, you can explore the rest of the steps in the notebook. For this post, we only require that the airport data is loaded.
Set up the AWS Glue Data Catalog
The next step is to set up the AWS Glue Catalog, database, and tables that are later referenced by the Athena Neptune Connector. For more details, such as mapping the property graph node and edge properties to the AWS Glue tables, see the GitHub repo.
Deploy the Athena Neptune Connector
To set up the Athena Neptune Connector, follow the step-by-step instructions in the GitHub repo.
Set up an Athena workgroup and custom data source
Athena Federated Query is only supported with Athena engine version 2. You should either upgrade your existing workgroup to Athena engine version 2 or create a new workgroup with this engine version. For this post, I create a new workgroup that supports Athena engine version 2.
- On the Athena console, on the Workgroups page, choose Create workgroup.
- For Workgroup name, enter a name (for this post,
Sample-AV2-WG). - Designate your S3 bucket for the Athena query result location.
For this post, we reuse the spillover bucket created earlier as the Athena query result location. You can create a separate bucket and use that as well. - Select Manually choose an engine version now and select Athena engine version 2.

- Choose Create workgroup.
- After the new workgroup is created, choose that workgroup and choose Switch workgroup.

- In the new workgroup, on the Data sources tab, choose Connect data source.
- Select Query a data source.
- Select All other data sources.
- Choose Next.

- For Lambda function¸ choose the function you created in the previous step.
- For Catalog name, enter a name (for this post, we use the same as the Lambda function name,
athena-catalog-neptune). - Choose Connect.
 This creates a new custom data source that we test next.
This creates a new custom data source that we test next. - Switch to Query editor and select the data source that you just created.
It automatically selects thegraph-databasein the database drop-down menu and populates the corresponding tables.Now let’s run a sample query to check connectivity to Neptune via the connector. - Choose Preview table.

You should see results similar to the following screenshot.

Now that we’re done with the Athena setup, let’s move to the QuickSight steps.
Configure QuickSight and create a dataset
Before we can create a dataset and visualization, we need to grant QuickSight access to the Athena Neptune Connector Lambda function that we created earlier, the Athena query results S3 bucket, and the S3 bucket where the Athena Neptune Connector spills over the results.
- On the QuickSight console, on the user name menu, choose Manage QuickSight.
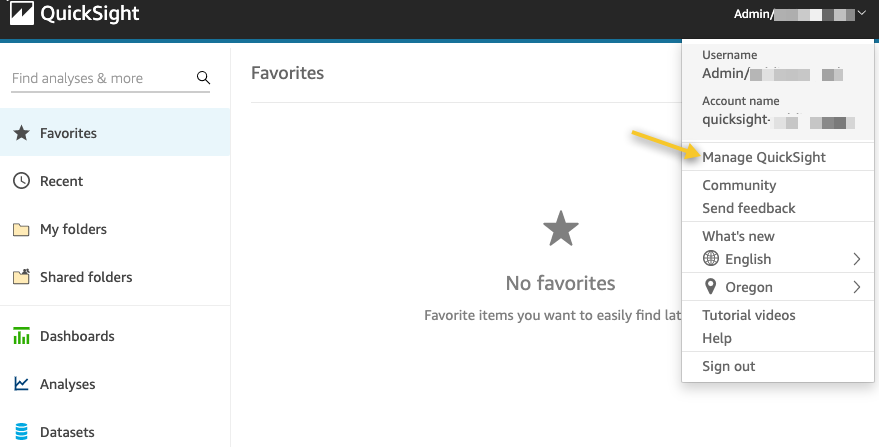
- Choose Security & permissions in the navigation pane.
- Under QuickSight access to AWS Services, choose Add or remove.

- From the list of services, select Athena.
A prompt should appear for Athena permissions. - Choose Next.

- On the S3 tab, select the Athena Neptune Connector spill bucket and Athena query results bucket. (For this post, we use the same bucket.)
- Select Write permission for Athena Workgroup.

- On the Lambda tab, and select the Lambda function that you created during the Athena Neptune Connector deployment.

- Choose Finish and Update to save your changes.
This completes the necessary initial configuration for QuickSight.
Now let’s proceed with the creation of a new dataset with Athena as our data source. - On the QuickSight console, choose Datasets in the navigation pane.
- Choose New dataset.
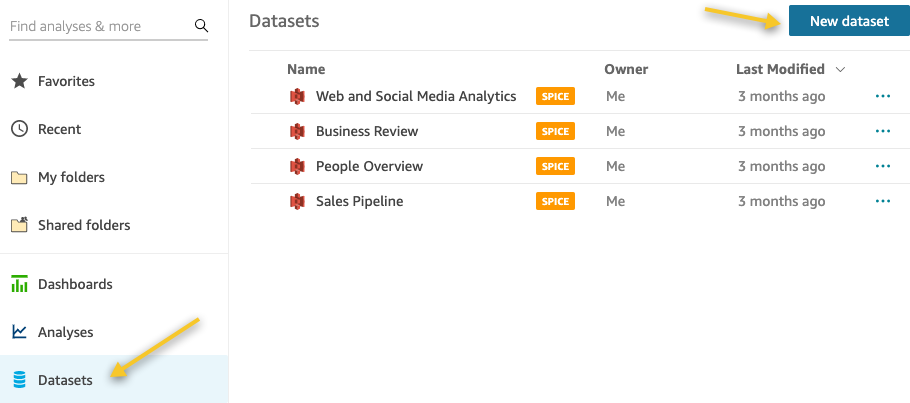
- Choose Athena as the data source.
- In the pop-up that appears, for Data source name, enter the data source name (
athena-neptune). - For Athena workgroup, choose the workgroup you created (
Sample-AV2-WG). - Choose Create data source.

- In the Choose your table section, choose the catalog associated with the Athena Neptune Connector, and choose the database associated with it.
- Under Tables, select the data to visualize (for this post, we use the
airporttable). - Choose Edit/Preview data.

- For Add data, choose Data source.
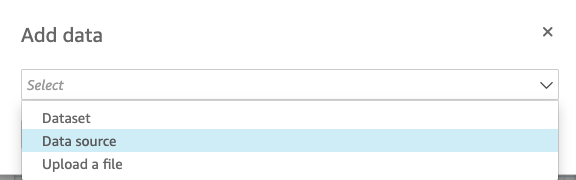
- For Catalog, choose athena-catalog.
- For Database, chose graph-database.
- For Table, select airport and route.
- Choose Select.

You should see something similar to the following screenshot after adding the two tables.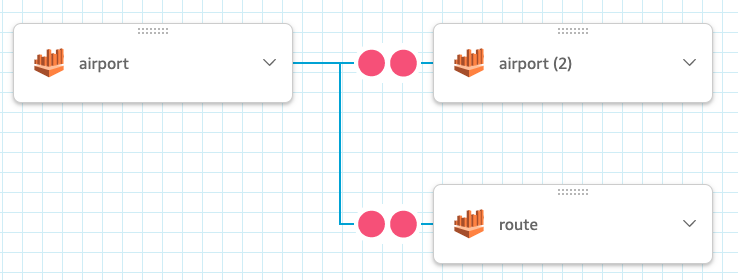
Now let’s arrange the tables visually in a way that the join operation is between theairport,route, andairport (2)tables. - Drag the
airport (2)table onto the route table.
This should create a join that looks similar to the following screenshot.
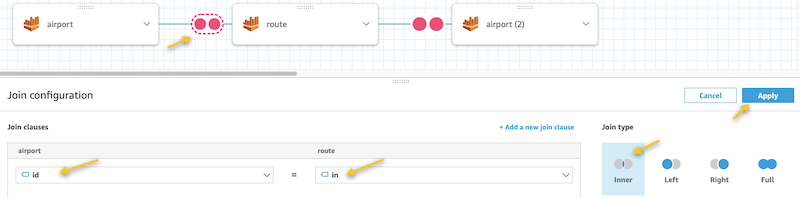
- Choose the join indicator (two red circles) between the
airportandroutetables. - In the Join configuration section, choose the id column for airport and in for route.
- For Join type, choose Inner.
- Choose Apply.
- Choose the join indicator between the
routeandairport (2)tables. - In the Join configuration section, choose out for route and id for airport.
- For Join type, choose Inner.
- Choose Apply.

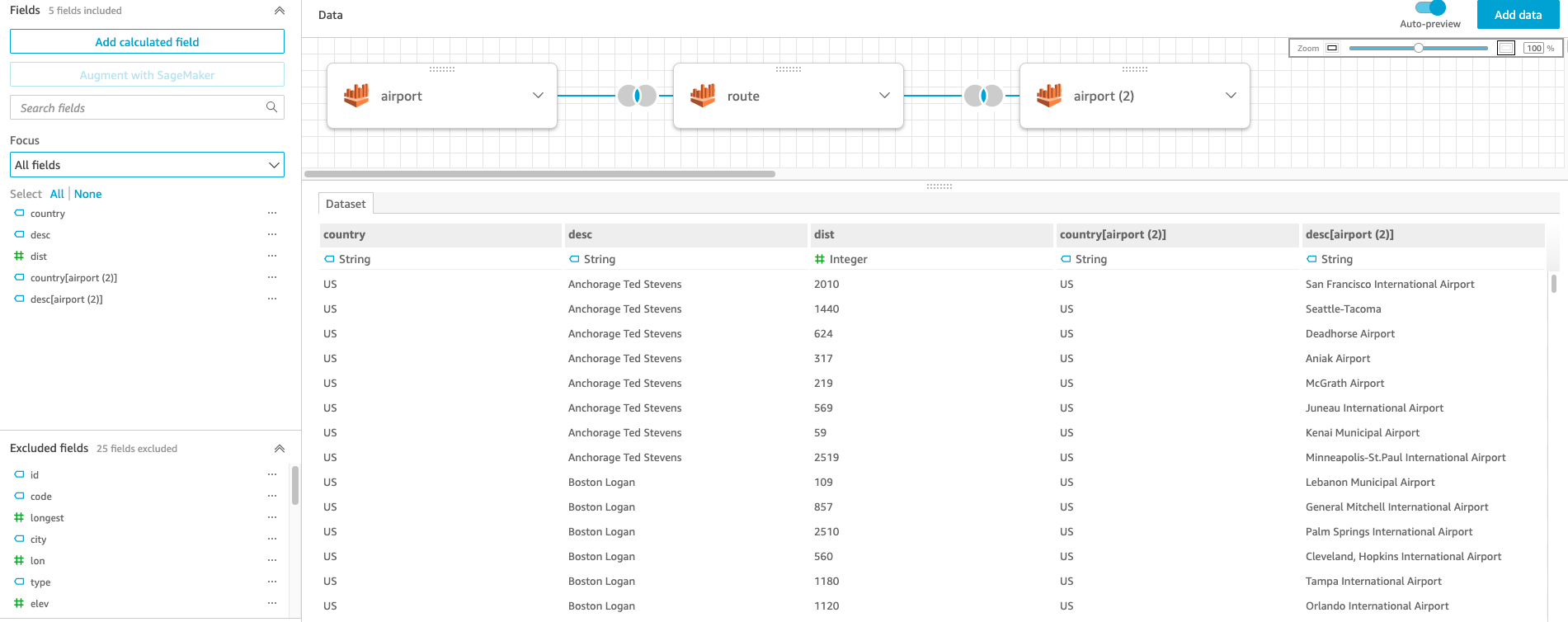
Now, let’s exclude the fields that we’re not going to use for data visualization purposes. We’re only interested in the following data fields:- The country and desc fields from the
airportandairport (2)tables - The dist field from the
routetable
- The country and desc fields from the
- Choose the menu icon (three dots) next to each field to exclude and choose Exclude field.

After all the unwanted data fields are excluded, you should see the joined dataset as in the following screenshot.
Visualize in QuickSight
In the next step, we create a QuickSight visualization to show the distance between airports in the US and UK, where the distance is greater than 5,000 miles, using this joined dataset.
- Choose Save & visualize.

- For Visual types, choose the horizontal bar chart.
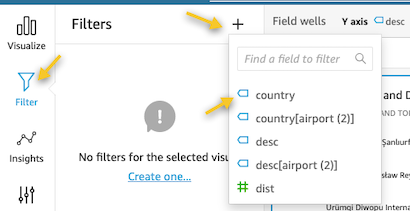
- Add the desc field to Y axis, dist to Value, and desc[airport(2)] to Group/Color.

- Choose Filters and choose the plus sign.
- Choose the country field.
- On the options menu (three dots), choose Edit.

- For Filter type¸ choose Custom filter and Equals.
- Enter US.
- Choose Apply.

- Apply similar filters to set the destination
country[airport (2)]as the UK and the distancedistbetween airports greater than 5,000 miles.The filters and visual should look similar to the following screenshot.

You can further customize this chart as per your requirements. In this case, I modified the title, color theme, X and Y axis labels, and legend title.

- To publish this analysis to a QuickSight dashboard, choose Share and Publish dashboard.

- Enter a name for the dashboard and choose Publish dashboard.

You can grant access to the dashboard for additional people or skip the step. TheUS-UK-Airportsdashboard is now available on the Dashboards page on the QuickSight console.This completes a very simple analysis of a property graph node and edge data.If you want to see the actual query being sent by QuickSight to Athena, you can find that on the History tab on the Athena console.


Current limitations
As of this writing, the Athena Neptune Connector only supports property graph datasets and not Resource Description Framework (RDF) graph datasets.
Summary
The Athena Neptune Connector is built using the Athena Query Federation SDK and allows you to run SQL queries against a Neptune property graph database. This unlocks the data in your Neptune database so you can use it for analysis via BI tools using Athena.
In this post, we walked through how to build a QuickSight dashboard using property graph data in Neptune via the Athena Neptune Connector.
If you have any questions or suggestions, please leave a comment.
About the Authors
 Abhishek Mishra is a Sr. Neptune Specialist Solutions Architect at AWS. He helps AWS customers build innovative solutions using graph databases. In his spare time, he loves making the earth a greener place.
Abhishek Mishra is a Sr. Neptune Specialist Solutions Architect at AWS. He helps AWS customers build innovative solutions using graph databases. In his spare time, he loves making the earth a greener place.
 Sandeep Veldi is a Sr. Solutions Architect at AWS. He helps AWS customers with prescriptive architectural guidance based on their use cases and helps navigate their cloud journey. In his spare time, he loves to spend time with his family.
Sandeep Veldi is a Sr. Solutions Architect at AWS. He helps AWS customers with prescriptive architectural guidance based on their use cases and helps navigate their cloud journey. In his spare time, he loves to spend time with his family.