AWS Database Blog
Category: Advanced (300)

Strategies for upgrading Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL from version 13
In this post, we help you plan your upgrade from PostgreSQL version 13 before standard support ends on February 28, 2026. We discuss the key benefits of upgrading, breaking changes to consider, and multiple upgrade strategies to choose from.

MaiCoin case study: Blue/green upgrade from Amazon ElastiCache Redis to Valkey
MaiCoin is a leading cryptocurrency exchange and brokerage platform in Taiwan. The MaiCoin platform previously ran on a set of Amazon ElastiCache deployment clusters on Redis OSS. This post explores MaiCoin’s practical approaches using RedisShake for migrating from Amazon ElastiCache for Redis OSS to Amazon ElastiCache for Valkey using blue/green deployment strategies.
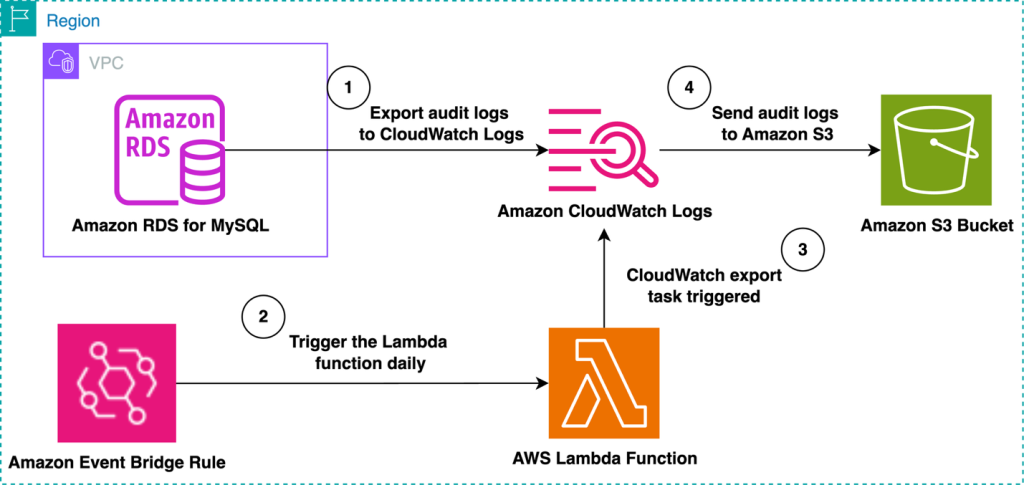
Automate the export of Amazon RDS for MySQL or Amazon Aurora MySQL audit logs to Amazon S3 with batching or near real-time processing
Amazon RDS for MySQL and Amazon Aurora MySQL provide built-in audit logging capabilities, but customers might need to export and store these logs for long-term retention and analysis. Amazon S3 offers an ideal destination, providing durability, cost-effectiveness, and integration with various analytics tools. In this post, we explore two approaches for exporting MySQL audit logs to Amazon S3: either using batching with a native export to Amazon S3 or processing logs in real time with Amazon Data Firehose.
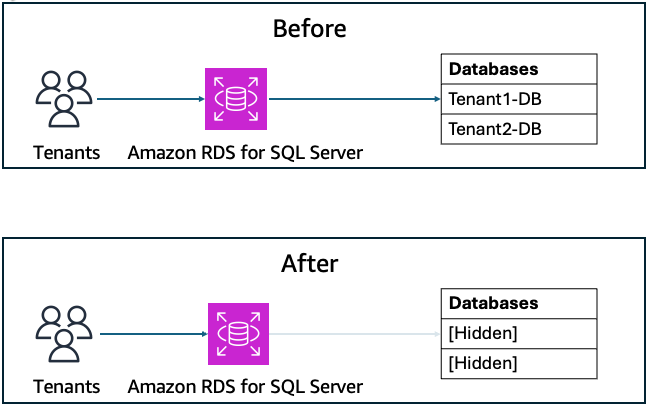
Control database name visibility in Amazon RDS for SQL Server instances
In Amazon Relational Database Service (Amazon RDS) for SQL Server, database visibility is configured using a dedicated stored procedure. In this post, we demonstrate tenant isolation at the visibility level, preventing tenants from seeing database names belonging to other customers while maintaining their access to their own resources. This solution addresses an important architectural consideration in multi-tenant SQL Server environments where database names might reveal tenant information. By using the Amazon RDS for SQL Server custom stored procedure msdb.dbo.rds_manage_view_db_permission, users can effectively control database visibility on a per-login basis while maintaining full application functionality.

Using the shared plan cache for Amazon Aurora PostgreSQL
In this post, we discuss how the Shared Plan Cache feature of the Amazon Aurora PostgreSQL-Compatible Edition can significantly reduce memory consumption of generic SQL plans in high-concurrency environments.

Effectively managing storage in Amazon RDS for Oracle Databases
Efficient storage management is crucial for maintaining the performance, reliability, and cost-effectiveness of your Oracle databases running on Amazon RDS. As your data grows and your workloads evolve, it’s essential to proactively monitor and optimize your storage utilization. In this post, we explore various techniques and best practices for effectively managing storage in RDS for Oracle Databases.
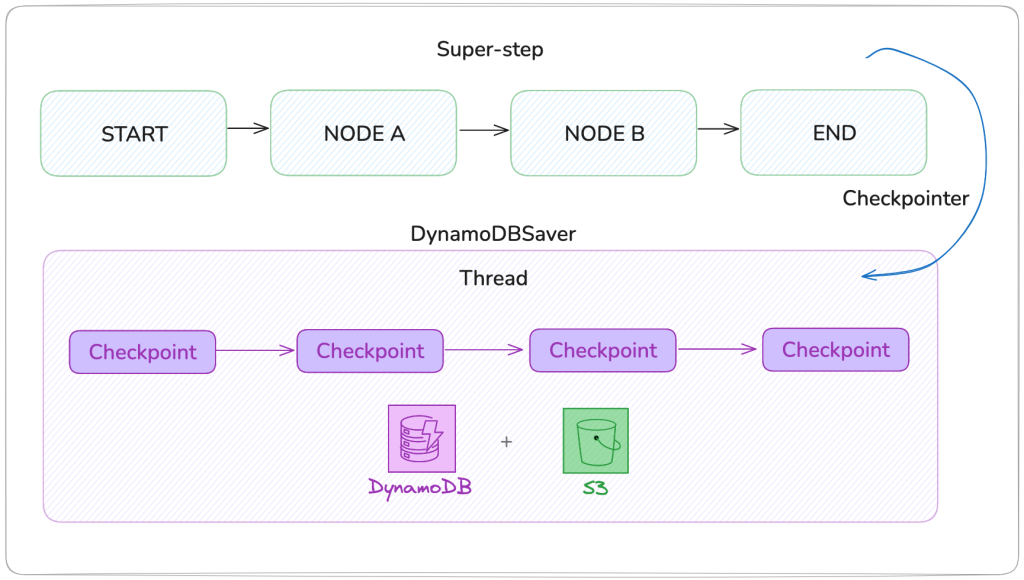
Build durable AI agents with LangGraph and Amazon DynamoDB
In this post we show you how to build production-ready AI agents with durable state management using Amazon DynamoDB and LangGraph with the new DynamoDBSaver connector, a LangGraph checkpoint library maintained by AWS for Amazon DynamoDB.

Best practices for creating and reorganizing data with additional storage volumes in Amazon RDS for Oracle
In this post, we show you how to use additional storage volumes to expand your RDS for Oracle storage capacity beyond 64 TiB. In addition, we walk through use cases for additional storage volume and best practices while working with additional volumes.
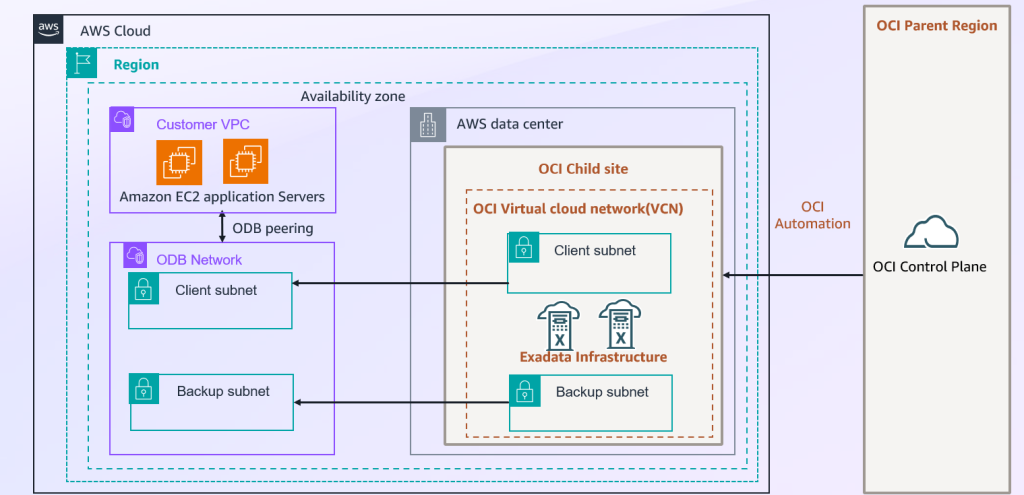
Provision Oracle Database@AWS stack using AWS CloudFormation
In this post, we explain how to set up key components of Oracle Database@AWS offering including ODB network, Oracle Exadata infrastructure, Exadata VM clusters and Autonomous VM clusters using AWS CloudFormation template.

Unlock Amazon Aurora’s Advanced Features with Standard JDBC Driver using AWS Advanced JDBC Wrapper
In this post, we show how you can enhance your Java application with the cloud-based capabilities of Amazon Aurora by using the JDBC Wrapper. Simple code changes shared in this post can transform a standard JDBC application to use fast failover, read/write splitting, IAM authentication, AWS Secrets Manager integration, and federated authentication.