AWS Database Blog
Lower cost and latency for AI using Amazon ElastiCache as a semantic cache with Amazon Bedrock
Large language models (LLMs) are the foundation for generative AI and agentic AI applications that power many use cases from chatbots and search assistants to code generation tools and recommendation engines. As we have seen with growing database workloads, the rising use of AI applications in production is driving customers to seek ways to optimize cost and performance. Most AI applications invoke the LLM for every user query, even when queries are repeated or very similar. For example, consider an IT help chatbot where thousands of customers ask the same question, invoking the LLM to regenerate the same answer from a shared enterprise knowledge base. Semantic caching is a method to reduce cost and latency in generative AI applications by reusing responses for identical or semantically similar requests by using vector embeddings. As detailed in the Impact section of this post, our experiments with semantic caching reduced LLM inference cost by up to 86 percent and improved average end-to-end latency for queries by up to 88 percent.
This post shows how to build a semantic cache using vector search on Amazon ElastiCache for Valkey. At the time of writing, Amazon ElastiCache for Valkey delivers the lowest latency vector search with the highest throughput and best price-performance at 95%+ recall rate among popular vector databases on AWS. This post addresses common questions such as:
- What is a semantic cache and how does it reduce the cost and latency of generative AI applications?
- Why is ElastiCache well suited as a semantic cache for Amazon Bedrock?
- What real-world accuracy, cost, and latency savings can you achieve with a semantic cache?
- How to set up a semantic cache with ElastiCache and Amazon Bedrock AgentCore?
- What are some key considerations and best practices for semantic caching?
Overview of semantic caching
Unlike traditional caches that rely on exact string matches, a semantic cache retrieves data based on semantic similarity. A semantic cache uses vector embeddings produced by models like Amazon Titan Text Embeddings to capture semantic meaning in a high-dimensional vector space. In generative AI applications, a semantic cache stores vector representations of queries and their corresponding responses. The system compares the vector embedding of each new query against cached vectors of prior queries to see if a similar query has been answered before. If the cache contains a similar query, the system returns the previously generated response instead of invoking the LLM again. Otherwise, the system invokes an LLM to generate a response and caches the query embedding and response together for future reuse.
This approach is particularly effective for generative AI applications that handle repeated queries, including Retrieval Augmented Generation (RAG)-based assistants and copilots, where many queries are duplicate requests from different users. For example, an IT help chatbot might see queries like “how do I install the VPN app on my laptop?” and “can you guide me through setting up the company VPN?”, which are semantically equivalent and can reuse the same cached answer. Agentic AI applications break down tasks into multiple small steps that may repeatedly look up similar information, allowing reuse of cached tool outputs or answers. For example, a compliance agent can reuse information retrieved from a policy tool to handle queries such as “Is my data storage in compliance with our privacy policies?” and “Set my data retention period to comply with our policies.” Semantic caching also works for data beyond text, such as matching similar audio segments in automated phone systems to reuse the same guidance for repeated requests like checking store hours or locations. The key benefits of using a semantic cache include, in all these applications:
- Reduced costs – Reusing answers for similar questions reduces the number of LLM calls and overall inference spend.
- Lower latency – Serving answers from the cache provides faster responses to users than running LLM inference.
- Improved scalability – Reducing LLM calls for similar or repeated queries enables you to serve more requests within the same model throughput limits without increasing capacity.
- Improved consistency – Using the same cached response for semantically similar requests helps deliver a consistent answer for the same underlying question.
ElastiCache as a semantic cache store for Amazon Bedrock
Semantic caching workloads continuously write, search, and evict cache entries to serve the stream of incoming user queries while keeping responses fresh. Therefore, a semantic cache must support real-time vector updates so new queries and responses are immediately available in the cache, maintaining cache hit rates and enabling dynamic data changes. Since the semantic cache sits in the online request path of every query, it must provide low-latency lookups to mitigate the impact on end-user response time. Finally, a semantic cache must efficiently manage an ephemeral hot set of entries that are written, read, and evicted frequently.
ElastiCache for Valkey is a fully managed and scalable cache service trusted by hundreds of thousands of AWS customers. Vector search in ElastiCache lets you index, search, and update billions of high-dimensional vector embeddings from providers like Amazon Bedrock, Amazon SageMaker, Anthropic, and OpenAI, with latency as low as microseconds with up to 99% recall. Vector search on ElastiCache uses a multithreaded architecture that supports real-time vector updates and high write throughput while maintaining low-latency for search requests. Built-in cache features such as time to live (TTL), eviction policies, and atomic operations help you manage the ephemeral hot set of entries that semantic caching creates. These properties make ElastiCache well-suited to implement a semantic cache. Further, ElastiCache for Valkey integrates with Amazon Bedrock AgentCore through the LangGraph framework, so you can implement a Valkey-backed semantic cache for agents built on Amazon Bedrock, following the guidance provided in this post. AgentCore and LangGraph provide higher level agent orchestration with tools and a managed runtime that handles scaling and Bedrock integration.
Solution overview
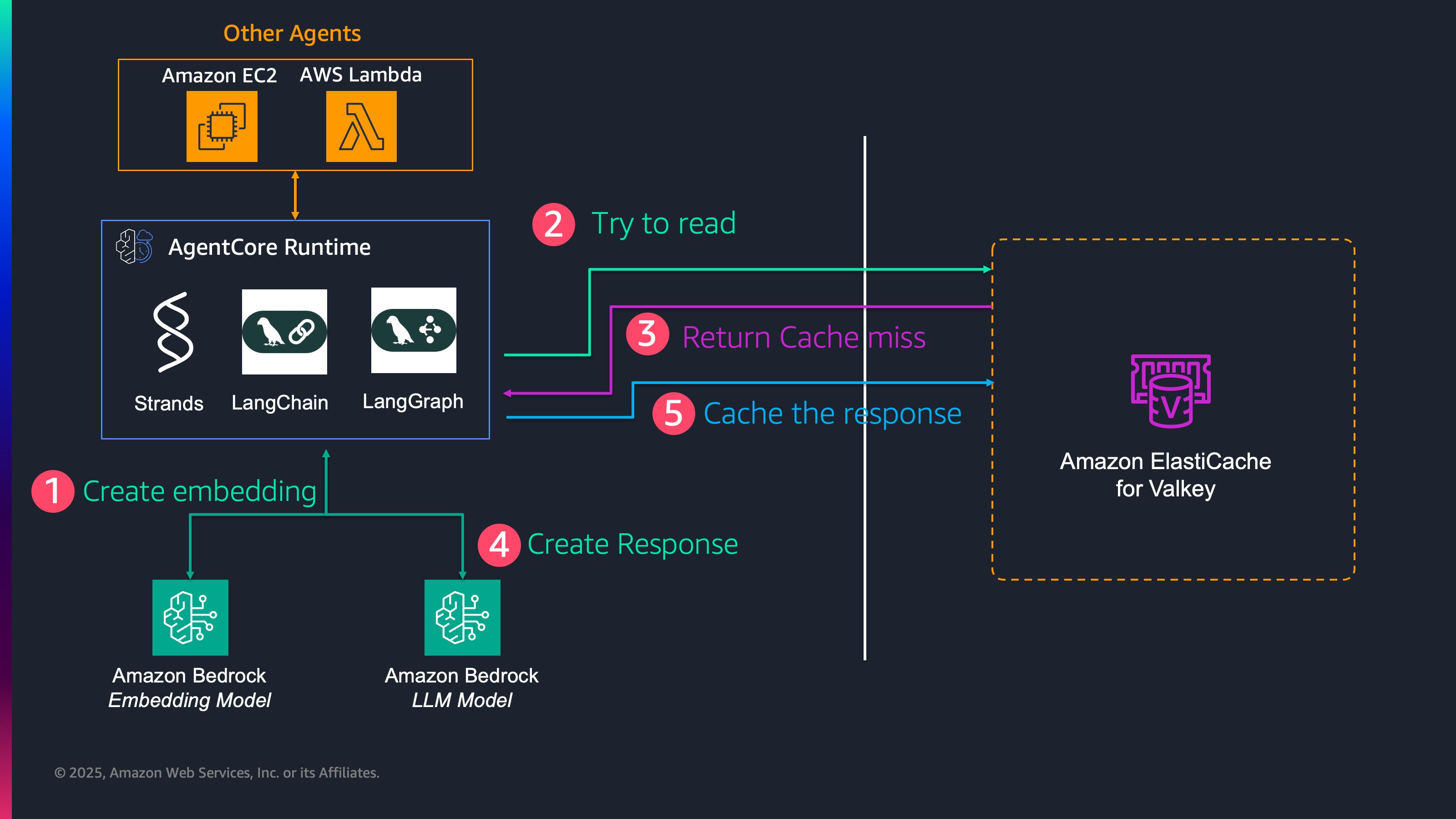
The following architecture implements a read-through semantic cache for an agent on AgentCore. The key components of this solution are an agent, an embedding model that converts text queries into vectors, an LLM to generate answers, and a vector store to cache these embeddings with their associated responses for similarity search. In this example, LangGraph orchestrates the workflow, Amazon Bedrock AgentCore Runtime hosts the agent and calls Amazon Titan Text Embeddings and Amazon Nova Premier models, and Amazon ElastiCache for Valkey is the semantic cache store. In this application, AgentCore calls the embedding model for each user query to generate a vector representation. AgentCore then invokes a semantic cache tool to send this vector to ElastiCache for Valkey to search for similar past queries stored in the cache. A request follows either of two paths in the application:
- Cache hit: If the tool finds a prior query above a configured similarity threshold, AgentCore returns the cached answer immediately to the user. This path only invokes the embedding model and does not require an LLM inference. Therefore, this path has millisecond-level end-to-end latency and does not incur an LLM inference cost.
- Cache miss: If the application does not find a similar prior query, AgentCore invokes a LangGraph agent that calls the Amazon Nova Premier model to generate a new answer and returns it to the user. The application then caches this result by sending the prompt’s embedding and answer to Valkey so that future similar prompts can be served from the semantic cache.
Deploy the solution
You must have the following prerequisites:
- An AWS account with access to Amazon Bedrock, including Amazon Bedrock AgentCore Runtime, Amazon Titan Text Embeddings v2 model, and Amazon Nova Premier enabled in the US East (N. Virginia) Region.
- The AWS Command Line Interface (AWS CLI) configured with Python 3.11 or later
- SSH into your Amazon Elastic Compute Cloud (Amazon EC2) instance inside your Virtual Private Cloud (VPC) and install the Valkey Python client and related SDKs:
Set up an ElastiCache for Valkey cluster and Amazon Titan embedding model
Launch an ElastiCache for Valkey cluster with version 8.2 or later that supports vector search using the AWS CLI:
From your application code running on your EC2 instance, connect to the Valkey configuration endpoint:
Set up Amazon Bedrock Titan embeddings:
ElastiCache for Valkey uses an index to provide fast and accurate vector search. See the ElastiCache documentation to learn more. Configure a ValkeyStore that automatically embeds “query” using a Hierarchical Navigable Small World (HNSW) index and COSINE for vector search:
Set up functions to search and update the semantic cache
Look up a semantically similar cached response from Valkey that is above a similarity threshold:
Update the semantic cache with the new query and answer pairs for future reuse:
Set up an AgentCore Runtime app with a read-through semantic cache
Follow the configuration steps in this guide to configure AgentCore Runtime to call ElastiCache from within a VPC. Implement a read-through semantic cache with Valkey Store using AgentCore entrypoint:
Although the solution in this blog uses Amazon Bedrock, semantic caching is deployment, framework, and model agnostic. You can apply the same principles to build a semantic cache with your preferred tools, for example by using an AWS Lambda function to orchestrate these steps. To learn more, refer to the following sample implementation of a semantic cache for a generative AI application, using ElastiCache for Valkey as the vector store with AWS Lambda.
Clean up
To avoid incurring additional cost, delete all the resources you created previously:
The impact of a semantic cache
To quantify the impact, we set up a semantic cache on 63,796 real user chatbot queries and their paraphrased variants from the public SemBenchmarkLmArena dataset. This dataset captures user interactions with the public Chatbot Arena platform across general assistant use cases such as question answering, writing, and analysis.
The application used ElastiCache cache.r7g.large instance as the semantic cache store, Amazon Titan Text Embeddings V2 for embeddings and Claude 3 Haiku for LLM inference.
The cache was started empty, and the 63,000 queries were streamed as random incoming user traffic, similar to what an application might experience in a day. Similar to traditional caching, we define cache hit rate as the fraction of queries answered from cache. However, unlike traditional caching, a semantic cache hit may not always answer the intent of user’s query. To quantify the quality of cached responses, we define accuracy as the fraction of cache hits whose responses correctly answer the user’s intent. Cost is measured as the sum of embedding generation, LLM inference, and ElastiCache instance costs. The cost of ancillary components such as EC2 instances are excluded since they are lower. Response latency is measured as the end-to-end time for embedding generation, vector search, LLM processing and network transfers.
Table 1 summarizes the trade-off between cost and latency reduction versus accuracy across different similarity thresholds for the semantic cache. You can tune the similarity threshold to choose a balance between cost savings and accuracy that best fits your workload. In this evaluation, enabling a semantic cache reduced LLM cost by up to 86% while maintaining 91% answer accuracy at a similarity threshold of 0.75. We should note that the choice of LLM, embedding model, and backing store for the semantic cache affects both cost and latency. In our evaluation, we use Claude 3 Haiku, a smaller, lower cost, fast model, but semantic caching can often deliver larger benefits when used with bigger, higher cost LLMs.
| Table 1: Impact of Semantic Cache on Cost and Accuracy | |||||||
| Similarity Threshold | Number of Cache Hits | Cache Hit Ratio | Accuracy of Cached Responses | Total Daily Cost | Savings With Cache | Average Latency with Cache (s) | Latency Reduction |
| Baseline with no cache | – | – | – | $49.5 | – | 4.35 | – |
| 0.99 | 14,989 | 23.5% | 92.1% | $41.70 | 15.8% | 3.60 | 17.1% |
| 0.95 | 35,749 | 56.0% | 92.6% | $23.8 | 51.9% | 1.84 | 57.7% |
| 0.9 | 47,544 | 74.5% | 92.3% | $13.6 | 72.5% | 1.21 | 72.2% |
| 0.8 | 55,902 | 87.6% | 91.8% | $7.6 | 84.6% | 0.60 | 86.1% |
| 0.75 | 57,577 | 90.3% | 91.2% | $6.8 | 86.3% | 0.51 | 88.3% |
| 0.5 | 60,126 | 94.3% | 87.5% | $5.9 | 88.0% | 0.46 | 89.3% |
Table 2 shows examples of user queries with similar intents and the impact of a semantic cache on response latency. A cache hit reduced latency by up to 59x, from multiple seconds to a few hundred milliseconds.
| Table 2: Impact of Semantic Cache on Individual Query Latency | ||||
| Intent | Query | Cache Miss (s) | Cache Hit (s) | Reduction |
| Intent 1.a | Are there instances where SI prefixes deviate from denoting powers of 10, excluding their application? | 6.51 | 0.11 | 59x |
| Intent 1.b | Are there situations where SI prefixes deviate from denoting powers of 10, apart from how they are conventionally used? | |||
| Intent 2.a | Sally is a girl with 3 brothers, and each of her brothers has 2 sisters. How many sisters are there in Sally’s family? | 1.64 | 0.13 | 12x |
| Intent 2.b | Sally is a girl with 3 brothers. If each of her brothers has 2 sisters, how many sisters does Sally have in total? | |||
Best Practices for Semantic Caching
Choosing data that can be cached : Semantic caching is well suited for repeated queries whose responses are relatively stable, whereas real-time or highly dynamic responses are often poor candidates for caching. You can use tag and numeric filters derived from existing application context (such as product ID, category, region, or user segment) to decide which queries and responses are eligible for semantic caching and to improve the relevance of cache hits. For example, in an e-commerce shopping assistant, you can route queries about static product information through the semantic cache while sending inventory and order status queries directly to the LLM and underlying systems. When users ask about a specific product, your application can pass the product ID and category from the product page as filters to the semantic cache so it retrieves similar prior queries and responses for that product.
Standalone query versus conversations: An AI assistant can either receive isolated, one-off queries or multi-turn conversations that build on previous messages. If your application has mostly standalone queries, you can use semantic cache directly on the user query text. For multi-turn conversational bots, first use your conversation memory (for example, session state or a memory store) to retrieve the key facts and recent messages needed to answer the current turn. Then apply semantic caching to the combination of the current user message and that retrieved context, instead of embedding the entire raw dialogue. This lets similar questions reuse cached answers without making the embeddings overly sensitive to small changes.
Set cache invalidation periods: Cached responses must be refreshed over time to keep answers accurate as underlying data such as product information, pricing, and policies evolve or as model behavior changes. You can use a TTL to control how long cached responses are served before they are regenerated on a cache miss. Choose a TTL that matches your application use case, as well as how often your data or model outputs change, to balance response freshness, cache efficiency, and application cost. Longer TTLs increase cache hit rates but raise the risk of outdated answers, while shorter TTLs keep responses fresher but lower cache hit rates and require more LLM inference, increasing latency and cost. For example, if your product catalog, pricing, or support knowledge base is updated daily, you can set the TTL to around 23 hours and add random jitter to spread out cache invalidations over time.
Personalizing responses: On a cache hit, the application might return the same response for every user, without taking their profile or current context into account. To serve personalized responses, you can either scope cache lookups to the user or segment, or generate personalized outputs by feeding the cached response plus user context into a lightweight, low-cost model for final response generation. While this approach offers smaller cost savings, it enables you to deliver personalized responses to users.
Conclusion
In this post, we explored semantic caching for generative AI applications using ElastiCache, covering a sample implementation of semantic caching, performance concepts, and best practices. Vector search on ElastiCache enables low-latency, in-memory storage of vectors, with zero downtime scalability and high-performance search across billions of vectors. To get started, create a new ElastiCache Valkey 8.2 cluster using the AWS console, AWS SDK, or AWS CLI. You can use this capability with popular Valkey client libraries such as valkey-glide, valkey-py, valkey-java, and valkey-go. To learn more about vector search or the list of supported commands to get started with semantic caching, see the ElastiCache documentation.