AWS Database Blog
Reduce read I/O cost of your Amazon Aurora PostgreSQL database with range partitioning
| June 2023: For Aurora databases where IO is greater than 25% of your costs, check out this blog post and recent announcement to see if you can save money with Aurora I/O-Optimized. |
Amazon Aurora PostgreSQL-Compatible Edition offers a SQL database with enterprise-grade speed, availability, and scale at a cost comparable to open-source databases. With Aurora, you pay for storage I/O operations that you consume. This pay-per-use model makes Aurora low-cost compared to traditional enterprise databases. However, it’s important to design your Aurora clusters to use I/O effectively at scale.
In this post, we demonstrate how to use PostgreSQL native partitioning to reduce I/O costs and increase read and write throughput with in-place partitioning that requires minimal downtime. Our example demonstrates a production-scale system that partitions a time series table database with over a hundred columns and relationships. The procedure migrates an application with 33 TB of data and ingests 46 GB a day into a partitioned-managed database that scales horizontally up to the current Aurora storage limit (128 TB). Our experiment optimizes the I/O costs (ReadIOPS) of the writer and readers database instances by up to 40% with a monthly partitioning policy and 60% with a daily partitioning policy. We also validated the solution with a smaller dataset (1 TB) that includes only 10 columns and ingested only 20 GB a day to demonstrate the impact on smaller databases. For the smaller dataset, we observed similar cost reduction.
Before going further, we recommend reviewing our previous post with tips on achieving high performance processing with Aurora when the database working set exceeds the available cache.
What is partitioning in PostgreSQL and why does it matter?
Table partitioning in PostgreSQL enables high-performance data input and reporting. You can use partitioning for databases ingesting large amounts of transactional data. Partitioning also provides faster queries of large tables and helps maintain data without provisioning a large database instance because it requires fewer I/O resources.
In this post, we partition the time series data of the fictitious ordering system for monthly and daily ranges to compare the trade-offs.
When the PostgreSQL optimizer reads a database query, it examines the WHERE clause of the query and tries to direct the database scan to only the relevant partitions. In the fictitious ordering system, the database engine routes the INSERT and UPDATE statements to the correct partitions, which are the child tables of the main table. That’s why it’s important to consider detaching old partitions if your business allows it. Furthermore, PostgreSQL version 14 allows you to detach the partition from the table as an online command. The data churning is simpler if you align your data size with the database instance size to limit compute costs.
Finally, Aurora PostgreSQL supports automatic management of partition creation and runtime maintenance with the Partition Manager (pg_partman) extension. pg_partman is a PostgreSQL extension that helps you manage your time series table partition sets.
Simulate hyperscale data growth in Aurora PostgreSQL
We ran a benchmark with a load simulator that generated 1,000 write (insert and update) and 10,000 read (select) transactions per second, weighing an average of 47 GB per day. We partitioned the database after the total database size was 33 TB of data and observed the I/O usage before and after partitioning.
The load simulator mimics a fictitious ordering system that allows users to place new orders (steps 1 and 2 in the following diagram) and update the orders throughout the order lifecycle (steps 3 and 4).

The load is simulated by a cyclic positive sine wave that triggers a thread, which inserts new orders. The orders IDs are stored in an Amazon Simple Queue Service (Amazon SQS) queue for processing by another type of thread that updates the orders. The write load consumes up to 60% of an db.r6g.8xlarge database CPU and processes up to 1,000 insert and update transactions per second.
The following figure shows more details of our ordering system load simulation.

Partitioning the orders table
Our dataset size was 33 TB before partitioning the orders table, including its indexes. There are a few ways to partition tables. The first method uses AWS Database Migration Service (AWS DMS), and the second migrates the data in-place. The first method uses PostgreSQL logical replication, which provides fine-grained control over replicating and synchronizing parts of your tables. AWS DMS copies data from a non-partitioned table to a partitioned table and enables migration to a partitioned table with minimal downtime.
We chose the in-place method because it’s the fastest and simplest method, but required a few brief (10 seconds) application interruptions throughout the migration steps.
We also needed to adapt the application to the new primary key that includes the partition key, so anytime the application used the primary key public_id, we added the partition key created_at. Unique constraints (and therefore primary keys) on partitioned tables must include all the partition key columns. This limitation exists because the individual indexes making up the constraint can only directly enforce uniqueness within their own partitions; therefore, the partition structure must guarantee no duplicates in different partitions. For example, in the insert simulation, instead of RETURNING public_id;, we add RETURNING public_id,created_at;. For updates, we add to the following code:
The following is our updated code:
The procedure is mostly done while the application is online, but a few applications interruptions are required to avoid exclusive locks to the database when running ALTER TABLE commands, so before steps 2, 4, and 5 in the following instructions, which require ALTER TABLE, we blocked the application access to the database, changed the table for a moment, and then restored application access to the database.
- Create the partitioned table with the original name and a
_parentsuffix (for example,orders_parent).
We extract theorders_parenttable and indexes DDL based on the existing schema with pg_dump, a tool that extracts a PostgreSQL database into a script file (the output ofpg_dump -Ox --schema-only -t orders -U postgres) and add the PARTITION BY RANGE clause. See the following code: - Scope the existing orders before partitioning to be the first partition.
We need to specify date and time upper and lower boundaries by setting a constraint on the partition key,created_at. We do this by determining the target day for transitioning to the partitioned table and generate the ALTER TABLE statement that creates the constraint.In our example, we create theorders_old_created_atconstraint 20 days in advance:We create the constraint with no validation and run the validation separately in step 4 as an online operation that requires only a brief application interruption for the duration of the ALTER TABLE command.
- Prepare the partition management with the
pg_partmanextension on Amazon RDS for PostgreSQL versions 12.5 and higher:Note that we configured the
p_start_partitionvalue based on the constraint value from step 2,max(created_at). - Validate the constraint validation from step 2 ended. This step requires a brief application interruption.
- The transition day to the partitioned table. This step requires an application interruption. Rename the existing orders table as the old partition table.
- Attach the old orders table as a partition:
Now that the orders table is daily partitioned, queries with created_at use only the relevant partitions when populating the shared buffer pool. This keeps the working set in-memory optimized.
Performance analysis
The IOPS cost optimization derived from the reduction in IOPS needed to fetch a transaction record by index and table, denoted by the db.IO.blks_read metric, because the working set fits the database instance memory size and better utilizes the buffer cache, denoted by db.Cache.blks_hit.avg.
Our simulation shows 600,000 blocks/second spikes of db.IO.blks_read before partitioning with the 33 TB working set, compared with 25,000 blocks/second spikes of db.IO.blks_read with daily partitioning (46 GB working set size). We also observed only 600,000 blocks/second of db.Cache.blks_hit.avg before partitioning and up to 1.5 million db.Cache.blks_hit.avg with daily partitions.
The following figure shows the CloudWatch metrics of the memory blocks in the writer instance before partitioning (33 TB).

The following figure shows the memory blocks in the writer instance with daily partitioning (45 GB).

Next, we compare the ReadIOPS that derives from the memory blocks reads optimization in the writer and reader instances. Note the same 140,000 per-second writes (db WriteIOPS), caused by inserts and updates before and after partitioning. The ReadIOPS on the writer (db ReadIOPS) instances is 100, 000 per second, compared to 40,000 per second with daily partitioning. We noticed similar optimization on the reader instance (db2 ReadIOPS).
The following figure shows the read/write IOPS in the writer instance before partitioning (33 TB).
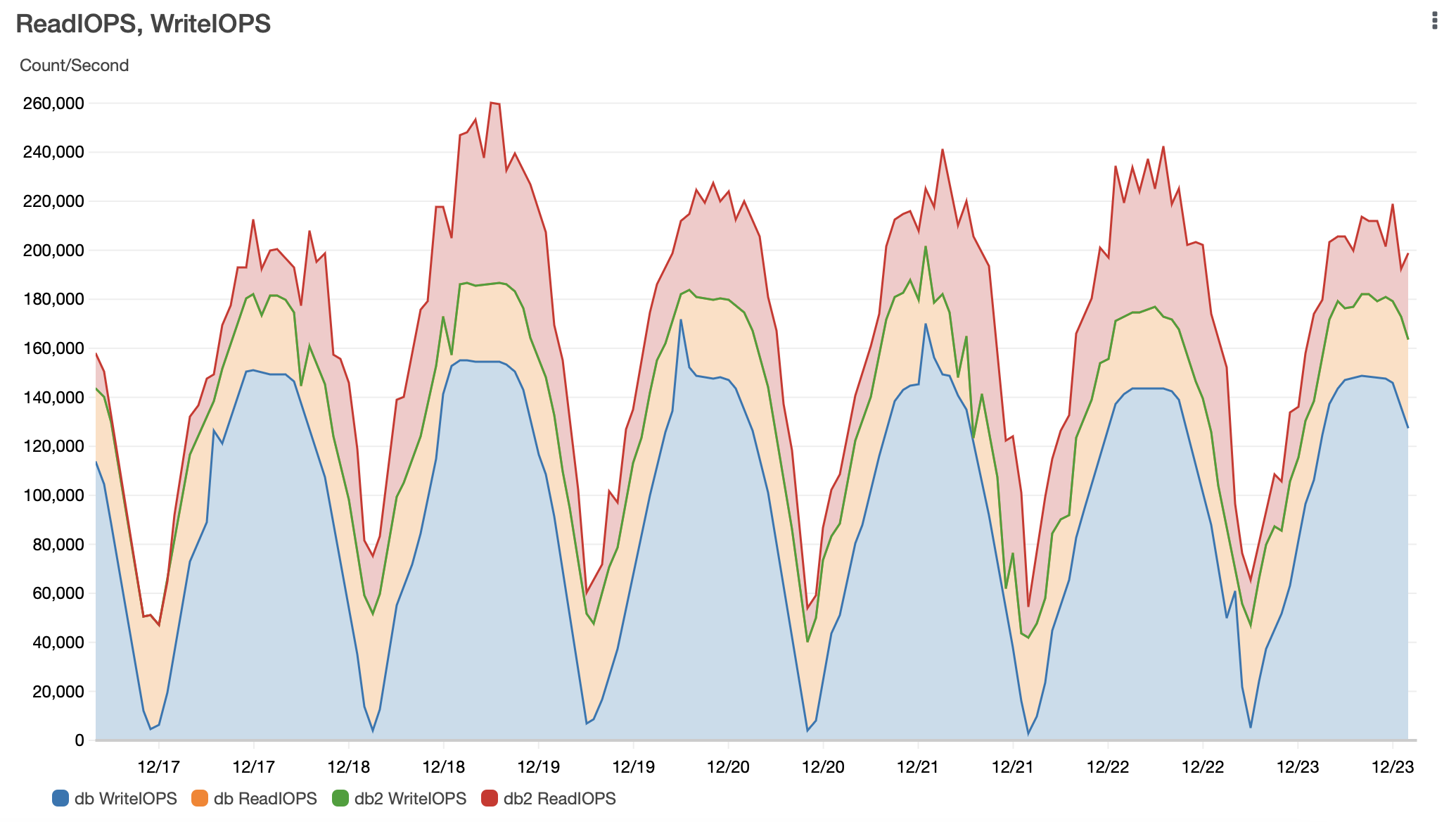
The following figure shows the read/write IOPS in the writer instance with daily partitioning (45 GB).

Cost analysis
We analyzed the Aurora storage I/O cost and usage with AWS Cost Usage Reports and found an average cost savings of up to 40% for the storage I/O for the synthetic workload we simulated. We analyzed weekly, bi-weekly, and monthly ranges of time and assessed the storage I/O cost savings to remove data bias.
The following table summarizes our weekly findings, as illustrated in the following figures that denotes hourly RDS IOPS charges (Region-RDS:PIOPS-Storage and Region-RDS:PIOPS)
| Partition | Time range | Storage I/O | cost ($) |
| Before | Weekly: 12/24/2021–12/31/2021 | 6.36365E+08 | 17676.81 |
| After | Weekly: 2/16/2022–2/23/2022 | 2.019E+08 | 5608.33 |


Conclusion
In this post, we showed you how to optimize Aurora storage I/O costs by up to 60% due to rapid growth challenges in PostgreSQL databases using the native PostgreSQL support in partitioning and with the pg_partman extension. We also discussed partitioning strategies and trade-offs with an example workload and provided both performance and cost analysis.
We’re eager to hear from you about similar challenges you experienced with your PostgreSQL database. Please leave a comment in the comment section or create an issue in the simulator code sample.
About the Authors
 Sami Imseih is a Database Engineer specialized in PostgreSQL at AWS. Sami has been overseeing mission critical database environments for over a decade. Since 2019, Sami has been helping customers achieve success with database migrations to Amazon RDS for PostgreSQL.
Sami Imseih is a Database Engineer specialized in PostgreSQL at AWS. Sami has been overseeing mission critical database environments for over a decade. Since 2019, Sami has been helping customers achieve success with database migrations to Amazon RDS for PostgreSQL.
 Yahav Biran is a Principal Solutions Architect in AWS, focused on game tech at scale. Yahav enjoys contributing to open-source projects and publishes in the AWS blog and academic journals. He currently contributes to the K8s Helm community, AWS databases and compute blogs, and Journal of Systems Engineering. He delivers technical presentations at technology events and works with customers to design their applications in the cloud. He received his PhD (Systems Engineering) from Colorado State University.
Yahav Biran is a Principal Solutions Architect in AWS, focused on game tech at scale. Yahav enjoys contributing to open-source projects and publishes in the AWS blog and academic journals. He currently contributes to the K8s Helm community, AWS databases and compute blogs, and Journal of Systems Engineering. He delivers technical presentations at technology events and works with customers to design their applications in the cloud. He received his PhD (Systems Engineering) from Colorado State University.