AWS Database Blog
Tag: Amazon Neptune

Building and querying the AWS COVID-19 knowledge graph
This blog post details how to recreate the AWS COVID-19 knowledge graph (CKG) using AWS CloudFormation and Amazon Neptune, and query the graph using Jupyter notebooks hosted on Amazon SageMaker in your AWS account. The CKG aids in the exploration and analysis of the COVID-19 Open Research Dataset (CORD-19), hosted in the AWS COVID-19 data […]

Moving to the cloud: Migrating Blazegraph to Amazon Neptune
During the lifespan of a graph database application, the applications themselves tend to only have basic requirements, namely a functioning W3C standard SPARQL endpoint. However, as graph databases become embedded in critical business applications, both businesses and operations require much more. Critical business infrastructure is required not only to function, but also to be highly […]

Change data capture from Neo4j to Amazon Neptune using Amazon Managed Streaming for Apache Kafka
After you perform a point-in-time data migration from Neo4j to Amazon Neptune, you may want to capture and replicate ongoing updates in real time. For more information about automating point-in-time graph data migration from Neo4j to Neptune, see Migrating a Neo4j graph database to Amazon Neptune with a fully automated utility. This post walks you […]

How Waves runs user queries and recommendations at scale with Amazon Neptune
This is a guest post by Pavel Vasilyev, Director of Solutions Architecture at ClearScale, an APN Premier Consulting Partner that provides a full range of cloud professional services. When executive management from Waves, a Y Combinator-backed mobile dating app, realized they were outgrowing their existing IT architecture on Google Cloud, they knew it was time […]
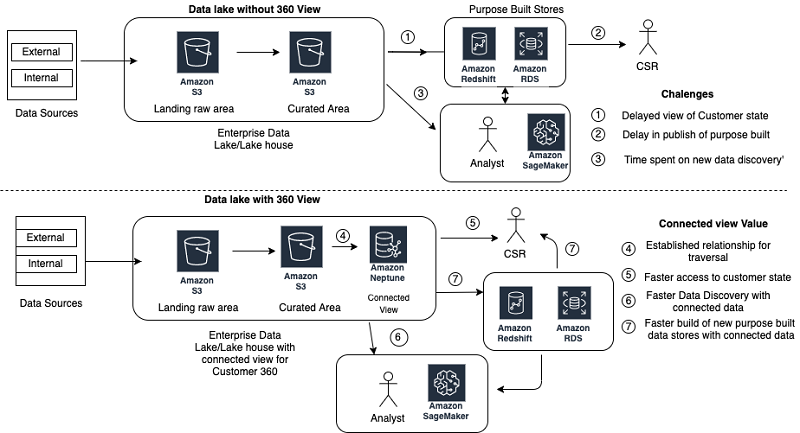
Building a customer 360 knowledge repository with Amazon Neptune and Amazon Redshift
Organizations build and deploy large-scale data platforms like data lakes, data warehouses, and lakehouses to capture and analyze a holistic view of their customer’s journey. The objective of such a data platform is to understand customer behavior patterns that influence satisfaction and drive more engagement. Applications today capture each point of contact with a customer, […]

How Gunosy built a comment feature in News Pass using Amazon Neptune
This guest post is a translation and adaption from How to implement and operate News Pass comment feature in GraphDB using Amazon Neptune, published in Japanese by Gunosy. Gunosy’s motto is to “Optimally deliver information to people around the world.” In their own words “Gunosy has developed and operated multiple media businesses, including the information […]

Exploring scientific research on COVID-19 with Amazon Neptune, Amazon Comprehend Medical, and the Tom Sawyer Graph Database Browser
COVID-19 is a global crisis that has affected us all. A massive research effort is underway to gain knowledge on every facet of the virus, including symptoms, treatments, and risk factors. To aid in the relief effort, AWS has created the public COVID-19 data lake, which contains various datasets you can use to help in the […]
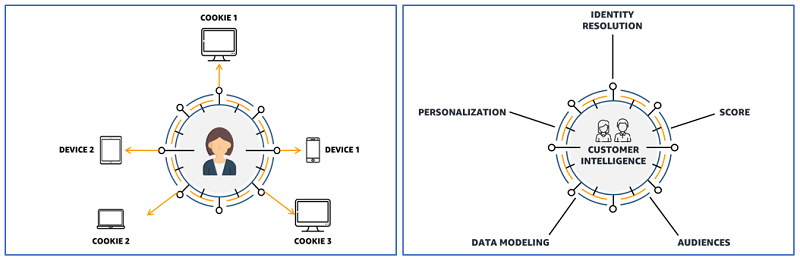
Building a customer identity graph with Amazon Neptune
A customer identity graph provides a single unified view of customers and prospects by linking multiple identifiers such as cookies, device identifiers, IP addresses, email IDs, and internal enterprise IDs to a known person or anonymous profile using privacy-compliant methods. It also captures customer behavior and preferences across devices and marketing channels. It acts as […]

Migrating a Neo4j graph database to Amazon Neptune with a fully automated utility
Amazon Neptune is a fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. You can benefit from the service’s purpose-built, high-performance, fast, scalable, and reliable graph database engine when you migrate data from your existing self-managed graph databases, such as Neo4j. This post shows […]
Lower the cost of building graph apps by up to 76% with Amazon Neptune T3 instances
When you are building a graph application, you want a fast, cost-effective instance as you iterate to build your Apache TinkerPop or RDF/SPARQL graph application. Amazon Neptune now allows you to choose burstable performance instances (T3) in addition to the fixed performance instances (R5 and R4). Amazon Neptune db.t3.medium burstable performance instances are engineered specifically […]