AWS Database Blog
Building a customer identity graph with Amazon Neptune
A customer identity graph provides a single unified view of customers and prospects by linking multiple identifiers such as cookies, device identifiers, IP addresses, email IDs, and internal enterprise IDs to a known person or anonymous profile using privacy-compliant methods. It also captures customer behavior and preferences across devices and marketing channels. It acts as a central hub and enables targeted advertising, personalization of customer experiences, and measurement of marketing effectiveness.
This post provides an overview of how to build a customer identity graph on AWS. It reviews key business drivers, challenges, use cases, customer success stories and the benefits of the solution. You also walk through the solution, sample data model, AWS CloudFormation templates, and other technical components that you can use to kick-start your development.
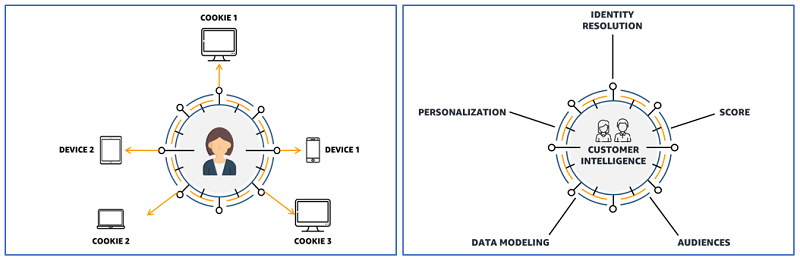
The following diagrams illustrate the collection of data around a given user, such as device identifiers, cookies, browsers, and behavior in a customer identity graph platform to enable identity resolution, scoring, and creation of audience segments for personalization.
You build the solution in Amazon Neptune, a purpose-built graph database for the cloud. It’s ideal for storing and navigating billions of interconnected relationships and supports millisecond latency for real-time advertising and marketing applications. The solution also uses Amazon SageMaker, a fully-managed platform for building, training, and developing machine learning models. For this solution, you use Amazon SageMaker for its ability to provide hosted Jupyter notebooks for loading customer identity graph data, and query it for a few common use cases.
Privacy-compliant customer experiences
Marketers, advertisers, and digital platforms must identify, understand, and anticipate customer needs and personalize experiences at scale using privacy-compliant methods.
Delivering on these expectations is challenging on many fronts. From a business standpoint, it entails aggregating data from enterprise silos across marketing, sales, loyalty, and others. From a technology standpoint, it requires a secure and flexible database platform that can scale globally to continually maintain a real-time customer identity and behavior graph for billions of interconnected relationships between devices, customer identifiers, channels, and preferences.
Building a customer identity graph solution on AWS
The customer identity graph solution provides a reference application so you can build a cost-efficient, scalable, secure, and highly available customer data platform with your own proprietary business rules. You can respond to customer signals in real time to automate your advertising and marketing applications and customer journey orchestration.
The solution enables marketers, ad-tech, mar-tech, gaming, media, and entertainment companies to capture and activate insights in real time from billions of relationships for millions of customer profiles. Customers like Zeta Global, NBCUniversal, and Activision Blizzard use Amazon Neptune to build identity graphs and capture consumer journeys to personalize advertising, content, and in-game experiences for millions of users.
This solution includes a sample data model, CloudFormation template, and Amazon SageMaker notebooks to query the database for common use cases. A complete customer identity graph solution usually consists of an ingestion pipeline, data validation, cleansing, identity resolution algorithms, identity graph database, and audience segmentation. This post focuses on ingesting data into a Neptune database, data modeling to capture interconnected profiles, and query mechanisms to support cross-device graphs, audience segmentation and other use cases.
Use cases
The following are some common use cases for this solution:
- Cross-device and interest graph – Find a given user’s interests by analyzing the customer journey and time spent across devices to personalize advertising
- Convince undecided consumers – Identify ecommerce site visitors based on prior website visits
- Audience segmentation by brand – Create specific audiences based on brand and category interest or affinity scores
- Interest-based advertising – Target ads based on prior interest in specific websites
- Early adopter path to purchase insights – Analyze the customer’s journey on a website from initial site visit to product purchase confirmation
- Identify look-alike customers – Query for common audience characteristics for a given purchased product
Graph databases are ideal for building customer identity graphs to capture and link billions of interconnected relationships to support these use cases. Although traditional Relational Database Management Systems (RDBMS) are ideal for building enterprise applications that require transactional integrity, they aren’t designed to capture highly connected datasets such as customer device graphs and support millisecond latency at scale. Similarly, SaaS solutions provide limited flexibility to capture and model multiple relationships. In contrast, graph databases are easy to model one-to-many and many-to-many relationships, flexible to redesign, and store relationships at a physical storage level to support low-latency queries.
The customer identity graph solution is built on Neptune—a fast, reliable, fully-managed graph database service that makes it easy to build and run applications that work with highly connected datasets. At the core of Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with millisecond latencies.
Solution overview
Creating a customer identity graph in Neptune requires three primary components:
- The customer identity graph data model – You first have to collect and transform your data to a graph data model in a format that you can load into your graph database (Neptune). This post also discusses the data elements required for a knowledge graph and the potential sources for that data.
- Jupyter notebook and Python library – You need a way to easily query your graph, explore the data, and potentially visualize the results. For this you use Jupyter notebooks, which is a common framework that many data engineers and data scientists use. Amazon SageMaker provides you with a fully managed Jupyter notebook environment made available through its notebook instance feature.
- Creating a Neptune cluster and Amazon SageMaker notebook instance: You create a Neptune cluster, load your data, and connect your Amazon SageMaker notebook instance with a pre-built CloudFormation stack.
The customer identity graph data model
As mentioned earlier, a customer identity graph is a collection of data around a given user, such as the device identifiers, browsers, cookies, and history of sites visited or mobile apps recently used. It can also contain known demographics about the user based on information provided through various account profiles. All this data is highly connected in a way that gives you insights to personalize and target advertising and marketing initiatives.
You can look for this relevant data in several places:
- Web and clickstream logs, which are a good source of information on user behavior
- Cookies or device IDs (such as IDFA for iOS and Android ID for Android devices) that are exposed through mobile applications
After collecting these datasets, you must determine a method for matching and connecting the different elements to a given user identity or a group of users.
This post uses an open dataset from the CIKM Cup 2016 Track 1: Cross-Device Entity Linking Challenge. The raw dataset contains three CSV files and a JSON file that are anonymized website visits from a list of devices. Multiple devices can be linked to a single user.
The dataset, on its own, isn’t very interesting. The data is highly obfuscated using hash keys to make it anonymous. The following diagram visualizes the data. It contains a persistent ID for each unique user, a device ID or a cookie for a user represented with a transient ID, and website visits linked back to a device (or transient ID). The data contained in this open dataset is very similar to what you might find via web server logs or clickstream data.

The dataset provides limited insights about customer identity and behavior such as top interests for iOS and Android device users, or by geography. To simulate a real-world example of a customer identity graph, the dataset also contains the following attributes:
- User attributes – Device operating system, browser type, email (for opted-in)
- Identity group – Persistent IDs grouped to a household or audience segments and affinity groups such as sports enthusiasts or gadget geeks
- Website groups – Websites categorized by main content theme or subject, such as news and politics, sports, shopping, or automotive
- User location – Opted-in IP addresses to derive the user’s city and state
- Time and data attributes – Customer behavior patterns by time, day of the week, seasons, and more
The following diagram is a full depiction of the open dataset combined with the manufactured portions.

As mentioned earlier, this post doesn’t provide the identity resolution algorithms used to link various persistent IDs to identity groups. In a larger identity resolution architecture, you could use portions of the customer identity graph to drive an identity resolution workflow. For this post, identity groups are manufactured and provided as part of the dataset.
For ease of use, the dataset is stored on Amazon Simple Storage Service (Amazon S3) in the following locations:
Each CSV file represents a set of vertices (nodes) and edges from the preceding data model. The CSV format used is in conformance to the format required to use the Neptune bulk load API. This allows you to load this data from Amazon S3 into Neptune directly.
Jupyter notebook and Python library
Jupyter notebooks are comprised of a web front end for an underlying Python console that allows you to run and execute Python code from a browser. This works nicely with the Python libraries for both Apache TinkerPop/Gremlin and RDF/SPARQL, the two graph frameworks and query languages Neptune supports. For this post, you use Apache TinkerPop and Gremlin to model and query the dataset. Gremlin has a gremlin-python client that you can use directly within the Jupyter notebooks to query your customer identity graph.
To simplify the code within the notebooks, a custom Python library of scripts helps generate many of the visualizations for each use case. The visualizations are generated using a Python library called networkx. These libraries were developed in conjunction with Clearcode, an AWS technology partner specializing in advertising and marketing technology application development.
Creating a Neptune cluster and Amazon SageMaker notebook instance
This post provides a CloudFormation template that creates the required resources and infrastructure and loads the data into Neptune automatically. The stack creates the following resources:
- Neptune VPC with three subnets and a VPC Amazon S3 endpoint
- Neptune cluster comprising a single r4.xlarge instance, with appropriate subnet, parameter, and security groups
- IAM role that allows Neptune to load data from Amazon S3
- Amazon SageMaker Jupyter notebook instance with IPython Gremlin extension modules, Gremlin console, and some sample notebook content
The following diagram illustrates the solution architecture.

The Neptune and Amazon SageMaker resources deployed in this solution incur costs. With Amazon SageMaker hosted notebooks, you pay for the Amazon EC2 instance and Amazon SageMaker notebooks. For Neptune, the cost is comprised of the Neptune instances used within the cluster, the storage capacity consumed by the data in the cluster, and the I/O between the instances and the storage.
For this post, you use a Neptune cluster with an r5.12xlarge for bulk loading and an ml.m4.xlarge Amazon SageMaker notebook instance. After you deploy the solution, you can scale down the Neptune instance to an r5.2xlarge to save on cost while still providing enough resources to run the provided examples. By scaling down to an r5.2xlarge, it costs approximately $2 per hour to run this solution.
- Launch the stack that corresponds to your preferred Region:
Region View Launch US East (Ohio) View 
US East (N. Virginia) View US West (Oregon) View EU (Ireland) View When you launch the stack, the Quick create stack page opens.
- Under Capabilities, select the two check boxes that give the stack permissions to create the required AWS Identity and Access Management (IAM)
- Choose Create stack.
 It takes approximately 1 hour to launch the stack and load the data into Neptune.
It takes approximately 1 hour to launch the stack and load the data into Neptune. - When the stack is ready, on the AWS CloudFormation console, choose the root stack of the CloudFormation stack you deployed (if you didn’t change the name of the stack, it should be named
Identity-Graph-Sample). - On the Outputs tab, find the SageMakerNotebook output and choose the provided link.
This launches the Jupyter console for the Amazon SageMaker notebook the CloudFormation stack created.

- In the Jupyter window below, open the Neptune directory, and then choose the
identity-graphsubdirectory. - Choose
identity-graph-sample.ipynbnotebook.
 After you connect to the
After you connect to the identity-graph-sample.ipynbnotebook, you can read through the initial section on the data for this walkthrough and run through each use case. To run each code block in the notebook, highlight the code block and choose Run. Make sure to run each code block in order, because there are dependencies that are loaded for each exercise. Some later exercises depend on output from former exercises.
 The notebook walks you through the remaining examples. It starts with examples showing the shape and size of the dataset that you loaded into Neptune. It then proceeds through the customer identity graph use cases listed earlier.
The notebook walks you through the remaining examples. It starts with examples showing the shape and size of the dataset that you loaded into Neptune. It then proceeds through the customer identity graph use cases listed earlier.
Conclusion
This post demonstrated how to use Neptune as a graph database to host a customer identity graph that you could use as part of a larger identity resolution architecture. You can use the CloudFormation template from this post or view the source code for the dataset, Python libraries, and Jupyter notebook on the GitHub repo.
Customer success stories
The following are success stories from customers using their solution to personalize their user experiences. They shared their experiences at re:Invent 2019.
Zeta Global is a data-driven marketing technology platform that helps marketers connect with their customers to drive personalization. They built their customer identity graph and insights platform on AWS with Neptune. Their identity resolution data store has 1 billion customer profiles in a 24/7, high-availability system that receives 450 million queries per day, with an average response time of 35 milliseconds. For more information, see the video Reimagining advertising analytics and identity resolution at scale on YouTube.
NBCUniversal used Neptune to personalize content experiences for their users, and achieved up to 40% cost reduction over the legacy system. For more information, see Real-world customer use cases with Amazon Neptune on YouTube.
Activision Blizzard’s consumer technology team presented at re:Invent 2019 to share how they use Amazon Neptune to store data from Call of Duty player journeys and states to enable machine learning-based personalized player experiences for millions of players. For more information, see How Call of Duty uses ML to personalize player engagement.
Resources for developers
Below you will find resources you need to get started with customer identity graph and Amazon Neptune. If you have not already done so, please see the Launch Stack links in the post above to launch the identity graph sample application. Further review of the code used for this application can be found on GitHub.
- Amazon Neptune resources
- Reference Architectures for Graph Databases on AWS on GitHub
- Best Practices: Getting the Most Out of Neptune
- Neptune Graph Data Model
- Writing to Amazon Neptune from Amazon Kinesis Data Streams on GitHub
About the Authors

Rajesh Wunnava is Global Head of Industry Solutions for digital advertising and marketing at AWS. He is responsible for developing industry strategy and AWS solutions to serve the needs of agencies, ad-tech, and mar-tech customers. He has over 15 years’ experience enabling advertising, media, and entertainment industries through data and technology capabilities. Prior to joining AWS, he was VP, Product- advertising and personalization at Nielsen/Gracenote. Other experience includes product and technology roles at Mindshare and Warner Music Group.

Taylor Riggan is a Sr. Specialist Solutions Architect focusing on graph databases at AWS. He works with customers of all sizes to help them learn and use purpose-built NoSQL databases via the creation of reference architectures, sample solutions, and delivering hands-on workshops.