AWS Database Blog
Tag: graph database

How Gunosy built a comment feature in News Pass using Amazon Neptune
This guest post is a translation and adaption from How to implement and operate News Pass comment feature in GraphDB using Amazon Neptune, published in Japanese by Gunosy. Gunosy’s motto is to “Optimally deliver information to people around the world.” In their own words “Gunosy has developed and operated multiple media businesses, including the information […]
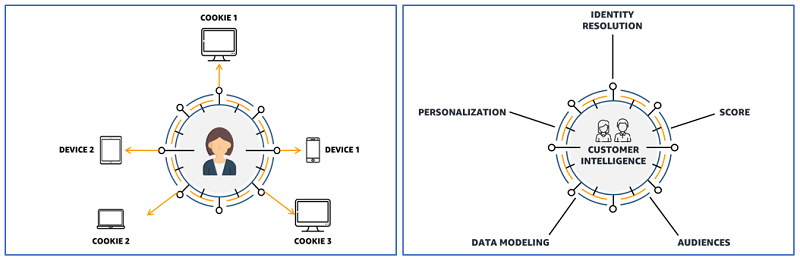
Building a customer identity graph with Amazon Neptune
A customer identity graph provides a single unified view of customers and prospects by linking multiple identifiers such as cookies, device identifiers, IP addresses, email IDs, and internal enterprise IDs to a known person or anonymous profile using privacy-compliant methods. It also captures customer behavior and preferences across devices and marketing channels. It acts as […]

Migrating a Neo4j graph database to Amazon Neptune with a fully automated utility
Amazon Neptune is a fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. You can benefit from the service’s purpose-built, high-performance, fast, scalable, and reliable graph database engine when you migrate data from your existing self-managed graph databases, such as Neo4j. This post shows […]

Graphing investment dependency with Amazon Neptune
Storing and querying investment dependencies as a graph in Amazon Neptune reveals new relationships. EDGAR (Electronic Data Gathering, Analysis, and Retrieval) is an online public database from the U.S. Securities and Exchange Commission (SEC). EDGAR handles automated collection, validation, indexing, acceptance, and submission forwarding by entities that are required by law to file forms with […]