AWS Developer Tools Blog
Serverless data engineering at Zalando with the AWS CDK
This blog was authored by Viacheslav Inozemtsev, Data Engineer at Zalando, an active user of the serverless technologies in AWS, and an early adopter of the AWS Cloud Development Kit.
Infrastructure is extremely important for any system, but it usually doesn’t carry business logic. It’s also hard to manage and track. Scripts and templates become large and complex, reproducibility becomes nearly impossible, and the system ends up in an unknown state, that’s hard to diagnose.
The AWS Cloud Development Kit (AWS CDK) is a unified interface between you, who defines infrastructure, and AWS CloudFormation, which runs infrastructure in AWS. It’s a powerful tool to create complex infrastructure in a concise and, at the same time, clean way.
Let’s quickly go through the phases of how a company’s infrastructure can be handled in AWS.
1. You start with the UI of AWS, and create resources directly, without any idea of stacks. If something goes wrong, it’s hard to reproduce the same resources in different environments, or even recreate the production system. This approach works only to initially explore the possibilities of the service, and not for production deployments.
2. You begin using the AWS API, most commonly by calling it using the AWS Command Line Interface (AWS CLI). You create bash or Python scripts that contain multiple calls to the API, done in imperative way, trying to reach a state where resources are created without failing. But the scripts (especially bash scripts) become large and messy, and multiply. They’re not written in a standard way, and maintenance becomes extremely tough.
3. You start migrating the scripts to AWS CloudFormation templates. This is better, but although AWS CloudFormation is a declarative and unified way of defining resources in AWS, the templates also get messy pretty quickly, because they mirror what happens in the scripts. You have to create the templates, usually by copying parts from other existing templates, or by using the AWS CloudFormation console. In either case, they grow big pretty fast. Human error occurs. Verification can only be done at the time of submission to AWS CloudFormation. And you still need scripts to deploy. Overall, it’s better, but still not optimal.
4. This is where the AWS CDK makes the difference.
Advantages of using the AWS CDK
The AWS CDK is a layer on top of AWS CloudFormation that simplifies generation of resource definitions. The AWS CDK is a library that you can install using npm package manager, and then use from your CLI. The AWS CDK isn’t an AWS service, and has no user interface. Code is the input and AWS CloudFormation templates are the output.
The AWS CDK does three things:
- It generates an AWS CloudFormation template from your code. This is a major advantage, because writing those templates manually is tedious and error prone.
- It generates a list of changes that would happen to the existing stack, if you applied the generated template. This gives better visibility and reduces human error.
- It deploys the template to AWS CloudFormation, where changes get applied. This simplifies the deployment process and reduces it to a call of a single AWS CDK command.
The AWS CDK enables you to describe your infrastructure in code. Although this code is written in one of these imperative programming languages — TypeScript, Python, Java, C# — it’s declarative. You define resources in the style of object-oriented programming, as if they were simply instances of classes. When this code gets compiled, an engineer can quickly see if there are problems. For example, if AWS CloudFormation requires a parameter for a certain resource, and the code doesn’t provide it, you see a compile error.
Defining resources in a programming language enables flexible, convenient creation of complex infrastructure. For example, one can pass into a function a collection of references to a certain resource type. Additional parameters can be prepared before creating the stack, and passed into the constructor of the stack as arguments. You can use a configuration file, and load settings from it in the code wherever you need it. Auto-completion helps you explore possible options and create definitions faster. An application can consist of two stacks, and output of the creation of one stack can be passed as an argument for the creation of the other.
Every resource created by the AWS CDK is always part of a stack. You can have multiple stacks in one application, and those stacks can be dependent. That’s necessary when one stack contains resources that are referenced by resources in another stack.
You can see how convenient it is. Now let’s have a look at a few common patterns we encountered while using the AWS CDK at Zalando.
Common patterns – reusable constructs
The AWS CDK has four main classes:
- Resource – Represents a single resource in AWS.
- Stack – Represents an AWS CloudFormation stack, and contains resources.
- App – Represents the whole application, and can contain multiple stacks.
- Construct – A group of resources that are bound together for a purpose.
The following diagram shows how these classes interact.
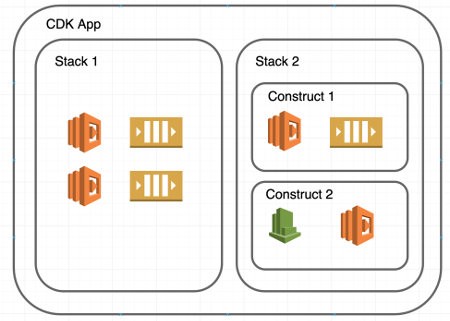
Every resource in AWS has a corresponding class in the AWS CDK that extends class Resource. All those classes start with the Cfn prefix, which stands for CloudFormation Native, and comprise the so called level 1 of the AWS CDK. Level 1 can be used, but usually it isn’t, because there is level 2.
Level 2 contains standard constructs that represent groups of resources usually used together. For example, a construct Function from the @aws-cdk/aws-lambda package represents not just a Lambda function, but also contains two resources: a Lambda function and its IAM role. This simplifies creation of a Lambda function, because it always requires a role to run with. There are many other level 2 constructs that are handy, and that cover most standard use cases.
There is also level 3, which is a way to share your own constructs between your projects, or even with other people anywhere in the world. The idea is that one can come up with a generic enough construct, push it to the npm registry — the same way, as, for example, @aws-cdk/aws-lambda package is pushed — and then, anyone can install this package and use that construct in their code. This is an extremely powerful way of sharing definitions of resources.
Now I am going to talk about a few patterns we uncovered so far working on data pipelines. These are:
- Periodic action
- Reactive processing
- Fan-out with Lambda functions
- Signaling pub/sub system
- Long-running data processing
Periodic action

The first pattern I want to show is a combination of a cron rule and a Lambda function. Lambda gets triggered every N minutes to orchestrate other parts of the system, for example, to pull new messages from an external queue, and push them into an internal Amazon SQS queue.
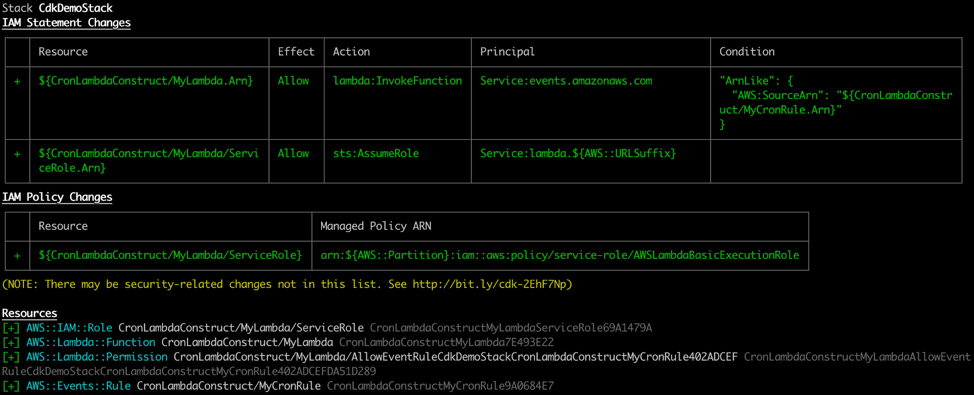
The following code example shows how the AWS CDK helps you manage defining infrastructure. In the code, a class CronLambdaConstruct extends class Construct of the AWS CDK. Inside there’s only a constructor. Every resource, defined in the constructor, will be created as part of the stack containing this construct. In this case the resources are a Lambda function, its IAM role, a rule with rate, and a permission to allow the rule to trigger the function.
The following picture depicts the output of the cdk diff, a command showing the plan of changes. Although only Function and Rule objects are explicitly initiated in the code, four resources will be created. This is because Function hides creation of its associated role, and Rule object results in creation of the rule itself together with the permission to trigger Lambda function.
Reactive processing
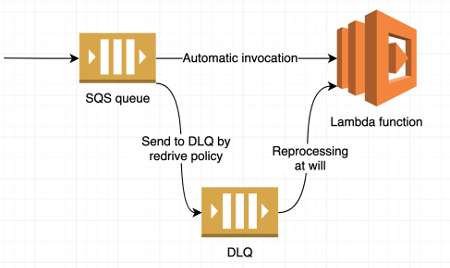
One of the major patterns useful in data pipelines is to connect an Amazon SQS queue to a Lambda function as its source, using event source mapping. This technique allows you to immediately process everything coming to the queue with the Lambda function, as new messages arrive. Lambda scales out as needed. You can detach the queue to stop processing, for example, for troubleshooting purposes.
The most interesting part is that you can attach another SQS queue to the source queue, known as a dead letter queue. A retry policy specifies how many attempts to process a message must fail before it will go to the dead letter queue. Then the same Lambda function can use the dead letter queue as its second source, normally in a detached state, to reprocess failed messages later. As soon as you fix the problem that caused Lambda to fail, you can attach the dead letter queue to the Lambda function. Then it can try to reprocess all the failed messages. This activity takes a click of a button in the Lambda console.
Fan-out with Lambda functions
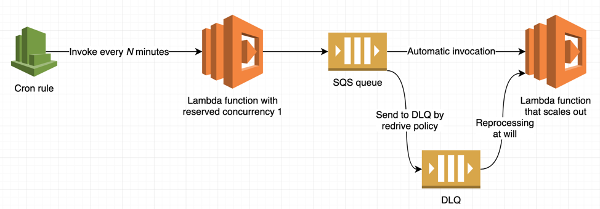
Now, let’s reuse the two previous constructs to get another pattern: fan-out of processing.
First there is an orchestrating Lambda function that runs with reserved concurrency 1. This prevents parallel executions. This Lambda function prepares multiple activities that can vary, depending on certain parameters or state. For each unit of processing, the orchestrating Lambda function sends a message to an SQS queue that is attached as a source of another Lambda function with high concurrency. Processing Lambda then scales out and executes the tasks.
A good example of this pattern is processing all objects by a certain prefix in Amazon S3. The first Lambda function does the listing of the prefix, and for each listed object it sends a message to the SQS queue. The second Lambda gets invoked once per object, and does the job.
This pattern doesn’t necessarily need to start with a cron Rule. The orchestrating Lambda function can be triggered by other means. For example, it can be reactively invoked by an s3:ObjectCreated event. I’ll talk about this next.
Signaling pub/sub system
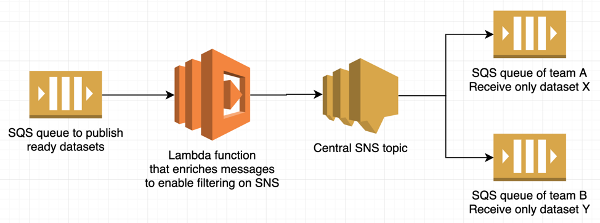
Another important approach, which we use across Zalando, is signaling to others that datasets are ready for consumption. This appeared to be a great opportunity to use AWS CDK constructs.
In this use case, there is a central Amazon SNS topic receiving notifications about all datasets that are ready. Anyone in the company can subscribe to the topic by filtering on the dataset names.
To subscribe, there is a construct that contains an SQS queue and an SNS subscription, which receives notifications from the central SNS topic and moves them to the queue.
Here we have two constructs. The first construct contains the input SQS queue, the Lambda function that enriches messages with MessageAttributes (to enable filtering), and the central SNS topic for publishing about ready datasets. The second construct is for the subscriptions.
Long-running data processing
The last pattern I want to describe is a long-running processing job. In data engineering this is a Hello World problem for infrastructure. Essentially, you want to run a batch processing job using Apache Spark or a similar framework, and as soon as it’s finished, trigger downstream actions. In AWS this can be solved using AWS Step Functions, a service where you can create state machines (in other words – workflows) of any complexity. The picture below depicts the pattern being described.
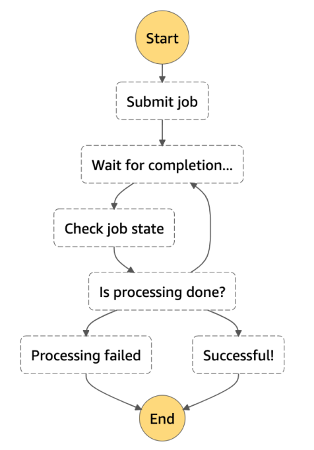
To do this using the AWS CDK, you can create a StateMachine object from the @aws-cdk/aws-stepfunctions package. It triggers a job, waits for its completion or failure, and then reports the result. You can even combine it with the previous pattern, to send a signal to the queue of the central SNS topic, informing it that the dataset is ready for downstream processing. For this purpose, integration of Step Functions with SQS via CloudWatch event Rules can be used.
Conclusion
The AWS CDK provides an easy, convenient, and flexible way to organize stacks and resources in the AWS Cloud. The CDK not only makes the development lifecycle faster, but also enables safer and more structured organization of the infrastructure. We, in the Core Data Lake team of Zalando, have started migrating every part of our infrastructure to the AWS CDK, whenever we refactor old systems or create new ones. And we clearly see how we benefit from it, and how resources become a commodity instead of being a burden.
About the Author
 Viacheslav Inozemtsev is a Data Engineer at Zalando, has 8 years of data/software engineering experience, a Specialist degree in applied mathematics and a MSc degree in computer science, mostly on the topics of data processing and analysis. In the Core Data Lake team of Zalando he is building an internal central data platform on top of AWS. He is an active user of the serverless technologies in AWS, and an early adopter of the AWS Cloud Development Kit.
Viacheslav Inozemtsev is a Data Engineer at Zalando, has 8 years of data/software engineering experience, a Specialist degree in applied mathematics and a MSc degree in computer science, mostly on the topics of data processing and analysis. In the Core Data Lake team of Zalando he is building an internal central data platform on top of AWS. He is an active user of the serverless technologies in AWS, and an early adopter of the AWS Cloud Development Kit.
Disclaimer
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.