AWS HPC Blog
Category: Amazon EC2

A Technical Deep Dive into Amazon EC2 Hpc8a Performance for Engineering and Scientific Workloads
High performance computing (HPC) workloads continue to grow in scale and complexity. Whether simulating airflow over an aircraft wing, modeling structural behavior under load, or performing crash simulation and multi-physics analysis, these workloads demand sustained compute throughput, high memory bandwidth, and efficient scaling across large clusters. Improvements in any one of these dimensions can reduce […]

Scaling life sciences research by deploying AWS ParallelCluster and AWS DataSync
In life sciences research, managing large-scale computational resources and data efficiently is important for success. However, traditional on-premises environments often struggle to meet these requirements effectively. This post demonstrates how JSR Corporation transformed their research infrastructure using AWS ParallelCluster and AWS DataSync, achieving a 33% reduction in CPU usage and 85% in storage requirements. JSR’s […]

Meet the Advanced Computing team of AWS at SC25 in St. Louis
We want to empower every scientist and engineer to solve hard problems by giving them access to the compute and analytical tools they need, when they need them. Cloud HPC can be a real human progress catalyst. If you run large scale simulations, tune complex models, or support researchers who consistently need more compute, the […]

AWS re:Invent 2025: Your Complete Guide to High Performance Computing Sessions
AWS re:Invent 2025 returns to Las Vegas, Nevada on December 1, uniting AWS builders, customers, partners, and IT professionals from across the globe. This year’s event offers you exclusive access to compelling customer stories and insights from AWS leadership as they tackle today’s most critical challenges in high-performance computing, from accelerating scientific discovery to optimizing […]

Petrobras optimizes cost and capacity of HPC applications with Amazon EC2 Spot Instances
Discover how Petrobras and Universidade Federal Fluminense (Rio de Janeiro — Brazil) developed an innovative HPC solution on AWS, leveraging Spot Instances to optimize costs. Explore the automations in place to avoid interruptions and use the lowest-cost instances available.

Application deep-dive into the AWS Graviton3E-based Amazon EC2 Hpc7g instance
In this post we’ll show you application performance and scaling results from Hpc7g, a new instance powered by AWS Graviton3E across a wide range of HPC workloads and disciplines.

Cost-effective and accurate genomics analysis with Sentieon on AWS
In this blog post, we benchmark the performance of Sentieon’s DNAseq and DNAscope pipelines using publicly available genomics datasets on AWS. You will gain an understanding of the runtime, cost, and accuracy performance of these germline variant calling pipelines across a wide range of Amazon EC2 instances.
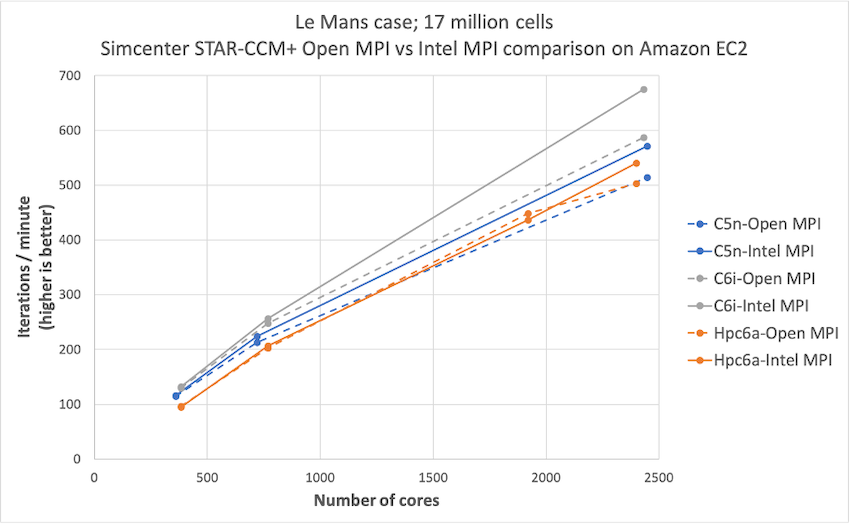
Simcenter STAR-CCM+ price-performance on AWS
Organizations such as Amazon Prime Air and Joby Aviation use Simcenter STAR-CCM+ for running CFD simulations on AWS so they can reduce product manufacturing cycles and achieve faster times to market. In this post today, we describe the performance and price analysis of running Computational Fluid Dynamics (CFD) simulations using Siemens SimcenterTM STAR-CCM+TM software on AWS HPC clusters.

GROMACS performance on Amazon EC2 with Intel Ice Lake processors
We recently launched two new Amazon EC2 instance families based on Intel’s Ice Lake – the C6i and M6i. These instances provide higher core counts and take advantage of generational performance improvements on Intel’s Xeon scalable processor family architectures. In this post we show how GROMACS performs on these new instance families. We use similar methodologies as for previous posts where we characterized price-performance for CPU-only and GPU instances (Part 1, Part 2, Part 3), providing instance recommendations for different workload sizes.

Coming soon: dedicated HPC instances and hybrid functionality
This year, we’ve launched a lot of new capabilities for HPC customers, making AWS the best place for the length and breadth of their workflows. EFA went mainstream and is now available in sixteen instance families for fast fabric capabilities for scaling MPI and NCCL codes. We’ve written deep-dive studies to explore and explain the optimizations that will drive your workloads faster in the cloud than elsewhere. We released a major new version of AWS ParallelCluster with its own API for controlling the cluster lifecycle. AWS Batch became deeply integrated into AWS Step Functions and now supports fair-share scheduling, with multiple levers to control the experience. Today we’re signaling the arrival of a new HPC-dedicated instance family – the Hpc6a – and an enhanced EnginFrame that will bring the best of the cloud and on-premises together in a single interface.