AWS HPC Blog
High Throughput Scheduling for Financial Services with YellowDog HTS on AWS
This post was contributed by Kirill Bogdanov (Pr. Solutions Architect at AWS) and Alan Parry, (CTO at YellowDog).
Large-scale compute grids sit at the heart of modern financial services operations. They power overnight batch runs for regulatory risk and prepare traders for the coming day. During trading, the same grids drive intraday ‘value at risk’ (VaR), trade pricing, real-time ‘Greeks’, and profit and loss calculations. These workloads routinely fan out into millions of independent, loosely coupled, and short-running tasks. At that scale on the cloud, the scheduler can become the bottleneck – its ability to continuously feed work into available compute is what determines how fast the entire workload completes. Compute demand is growing and Financial Services Institutions (FSI) workload patterns are becoming increasingly volatile with regulatory requirements expanding the scope of batch runs, while market volatility demands more frequent intraday pricing and risk calculations.
YellowDog is a high performance computing solution that combines compute orchestration with workload scheduling. It provisions and manages resources across multiple AWS regions, giving access to many instance types whilst prioritizing Amazon EC2 Spot capacity through a single control plane to optimize cost and maximize capacity. In response to increasing demand for higher throughput from financial services customers, YellowDog has recently introduced its High Throughput Scheduling (HTS) solution: a new scheduling architecture built specifically for massively parallel, fine-grained workloads.
In this post, we present an evaluation of YellowDog HTS on AWS and demonstrate a sustained throughput of 40,000 tasks per second, a 13x improvement over our previous analysis. This is the third post in our series with YellowDog, building on our earlier work scaling YellowDog to 3.2 million vCPUs and benchmarking scheduling performance for FSI workloads.
YellowDog High Throughput Scheduling
YellowDog High Throughput Scheduling (HTS) is a re-engineered task allocation pipeline built for the massively parallel, fine-grained workloads that define modern financial services compute. Traditional schedulers become a bottleneck as task volumes climb into the hundreds of millions across FRTB, XVA, RWA, and Monte Carlo runs. HTS removes that constraint by sustaining dispatch rates high enough to keep every worker busy, so available cloud capacity gets converted directly into completed work. No changes are needed to the workload submission model or worker configuration. Because workers stay fully utilized, HTS pairs well with Amazon EC2 Spot Instances and the compute efficiency you get translates directly into cost savings.
This matters in practice because Spot Instances can occasionally be reclaimed. When a worker running on Spot gets interrupted, its in-flight tasks need to be rescheduled to other workers. A scheduler that’s already at capacity will struggle to absorb that rework on top of the normal task flow. With HTS, interrupted tasks get redistributed without creating a backlog. YellowDog automatically handles the re-provisioning if Spot capacity is reclaimed; replacement instances are brought up automatically and workers resume pulling from the queue. The net effect is that firms can run aggressively on Spot without worrying that interruptions will cause them to exceed their batch window.
Benchmark Configuration
In this testing, we’re using the same terminology as our previous benchmarking post. In summary: a task is a single unit of work, jobs group tasks that are submitted and run together, and a workload is a larger set of jobs that delivers a business outcome (for example, a complete nightly batch). On the compute side, workers are processes running on Amazon EC2 instances, with multiple workers per instance.
To evaluate YellowDog HTS on AWS, we configured a cluster of 200 Amazon EC2 instances hosting a total of 40,000 YellowDog workers. The workload consisted of 100 million tasks, each executing a one-second computational payload. This task duration is representative of the short-running, fine-grained work units common in Monte Carlo simulations, scenario-based risk calculations, and pricing engines used across capital markets.
On the client side, 20 concurrent processes each submitted 5 million tasks in batches of 1,000, feeding a single shared work requirement that distributed the full 100 million tasks across the worker pool. Task completion was collected via client polling at 15-second intervals.
Results
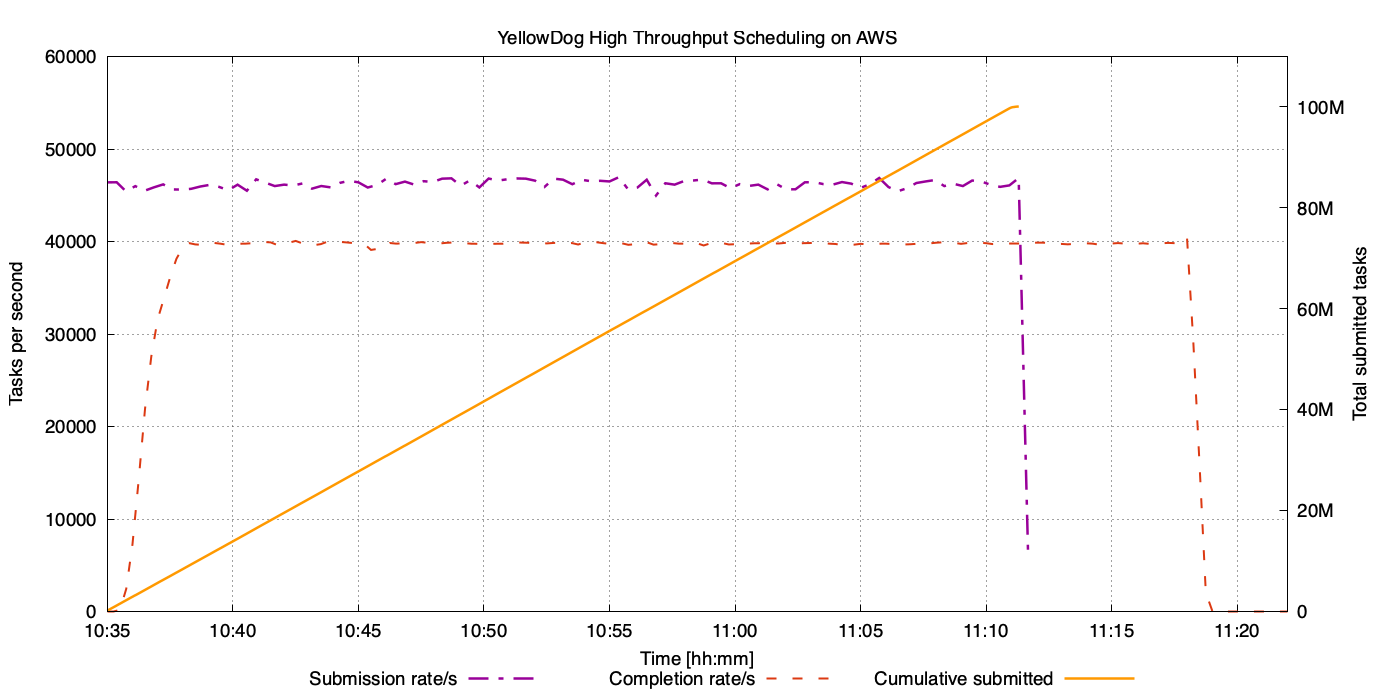
Figure 1: Sustained task throughput over the duration of the benchmark run. The purple line shows the client-side submission rate (~46,000 TPS), and the orange line traces cumulative tasks submitted, rising steadily to 100 million. The Red dashed line shows 40,000 workers processing 1 second jobs at the corresponding rate of 40,000 TPS.
The plot above shows the full lifecycle of a 100-million-task benchmark run. The x-axis represents time of the day, while the left y-axis measures throughput in tasks per second and the right y-axis tracks the cumulative number of tasks submitted. The purple line shows the client-side submission rate, sustained at approximately 46,000 tasks per second across 20 parallel submission processes. The orange line traces the cumulative total of submitted tasks, rising steadily to 100 million.
The close alignment between scheduling and completion rates shows that HTS keeps workers fully utilized with no significant queuing delay.
The table below summarizes the key benchmark results and their relevance to FSI workloads across throughput, utilization, workload completion, and flexibility.
| Performance dimension | Metric / result | FSI relevance |
| Peak scheduling throughput | 40,000+ TPS sustained across a 200-node cluster | Intraday VaR, Greeks, P&L recalculation at trading-day pace |
| Task submission rate | ~44,600 TPS sustained across 20 parallel submission processes | Feeds large FRTB / XVA fan-outs without queuing delay |
| Task collection rate | ~39,200 TPS sustained with polling at 15-second intervals | Continuous result harvest without back-pressure |
| Worker utilization | >99% saturation of 40,000 workers across 200 nodes | Maximizes value of preferred Spot instance types; idle compute eliminated |
| Queuing delay | Negligible delays with scheduling and completion rates aligned | Removes the throughput ceiling that constrains traditional schedulers at scale |
| 100M-task workload runtime | <45 minutes with 1-second tasks across a heterogeneous fleet | Overnight batch windows compressed; faster response to changing market conditions |
How It Works
HTS achieves and sustains throughput of more than 40,000 tasks per second through a fundamentally different scheduling architecture built to eliminate per-task coordination overhead. Instead of centrally dispatching individual tasks, HTS uses an adaptive batching model designed from first principles for the unique characteristics of compute deployed across multiple cloud regions. YellowDog achieves this by allocating workers with intelligently sized and timed batches of work, drastically reducing scheduler interactions and contention. The scheduler dynamically tunes the queue depth for each node based on real-time performance signals, allowing distributed, heterogeneous and volatile compute fleets, such as Amazon EC2 Spot, to remain fully utilized. This decentralized, pull-based approach removes traditional bottlenecks such as locking, hot partitions, and control-plane saturation, enabling near-linear scaling to tens of thousands of concurrent workers while maintaining high efficiency under constantly changing cloud conditions.
Conclusion
In this post, we evaluated YellowDog’s High Throughput Scheduling on AWS. We measured aggregate submission throughput of ~44,600 tasks per second and collection throughput of ~39,200 tasks per second across 100 million tasks – that’s a 13x improvement over the base scheduler we measured in our previous post.
To put that in perspective: at a sustained 40,000 TPS, a 100-million-task overnight batch completes in under 42 minutes. At the previous rate of 3,000 TPS, that same batch would take over 9 hours – longer than a typical overnight calculation window. For firms running nightly VaR, FRTB, or RWA batches, this is the difference between completing on time and still being in the queue when the trading day starts.
Combined with the scaling capabilities we demonstrated earlier (3.2 million vCPUs in 33 minutes at 95% utilization) and sub-second scheduling overhead for intraday workloads, these results demonstrate that YellowDog on AWS can handle both latency-sensitive intraday workloads and large-scale overnight batch processing.
To explore YellowDog and HTS further you can contact YellowDog directly via their website at https://yellowdog.ai. YellowDog is an AWS HPC Competency Partner and is available through AWS Marketplace.