AWS HPC Blog
Introducing AWS HPC Connector for NICE EnginFrame
HPC customers regularly tell us about their excitement when they’re starting to use the cloud for the first time. In conversations, we always want to dig a bit deeper to find out how we can improve those initial experiences and deliver on the potential they see. Most often they’ve told us they need a simpler way to get started with migrating and bursting their workloads into the cloud.
Today we’re introducing AWS HPC Connector, which is a new feature in NICE EnginFrame that allows customers to leverage managed HPC resources on AWS. With this release, EnginFrame provides a unified interface for administrators to make hybrid HPC resources available both on-premises and within AWS. It means highly specialized users like scientists and engineers can use EnginFrame’s portal interface to run their important workflows without having to understand the detailed operation of infrastructure underneath. HPC is, after all, a tool used by humans. Their productivity is the real measure of success, and we think AWS HPC Connector will make a big difference to them.
In this post, we’ll provide some context around EnginFrame’s typical use cases, and show how you can use AWS HPC Connector to stand up HPC compute resources on AWS.
Background
NICE EnginFrame is an installable service-side application that provides a user-friendly application portal for HPC job submission, control, and monitoring. It includes sophisticated data management for every stage of a job’s lifetime, and integrates with HPC job schedulers and middleware tools to submit, monitor, and manage those jobs. The modular EnginFrame system allows for extreme customization to add new functionality (application integrations, authentication sources, license monitoring, and more) via the web portal.
The favorite feature for end users is EnginFrame’s web portal which provides an easy-to-understand, and consistent, user interface. The underlying HPC compute and storage can be used without needing to be fluent in either command line interfaces (CLIs), or in writing scripts. This frees you to scale your HPC systems underneath, and make them available to non-IT audiences who are focused on curing cancer or designing a better wind turbine.
Behind the scenes, EnginFrame “spools” a management process for each submitted job. This spooler runs in the background to manage data movement and job placement on the selected computational resource, and returns the results when the job finishes. This is transparent to the end user. As the administrator, you provide the necessary configuration to set up an application —app-specific parameters, location of data, where to run analysis, who can submit jobs. The admin portal also shows health and state information for the registered HPC systems, as shown in Figure 1.
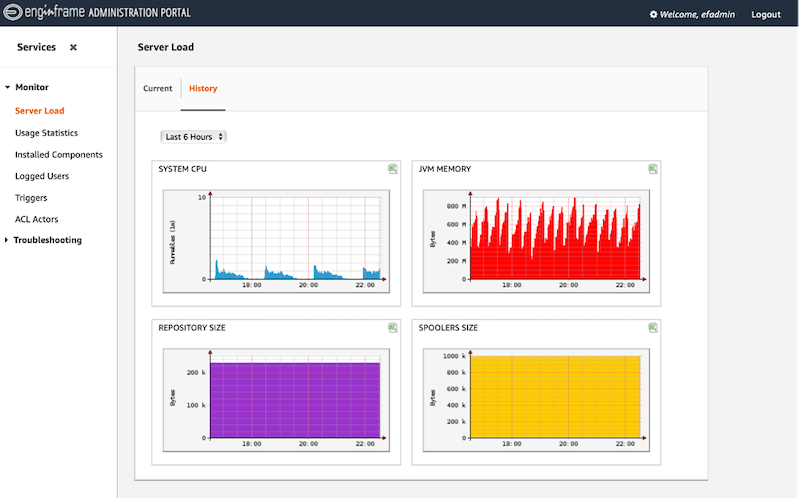
Figure 1: NICE EnginFrame operational portal showing historical resource usage.
Prior to this release, EnginFrame treated all registered HPC clusters as the same, even if some were static on-premises resources, and others elastic clusters in the cloud. Specific to AWS, EnginFrame left all the decisions about your AWS infrastructure to you, including network layouts, security posture, and scaling. Quite often customers used AWS ParallelCluster (our cluster-management tool that makes it easy to deploy and manage HPC clusters on AWS) to stand up clusters within an AWS Region. They’d then manually install EnginFrame on their head node and integrate the two. While this approach worked, we knew the experience could be better.
In September, we introduced new API capabilities in ParallelCluster 3, in preparation for today, so you can have all the functionality of ParallelCluster in EnginFrame with a single administration, management, and deployment path for hybrid HPC.
AWS HPC Connector
AWS HPC Connector begins by letting you register ParallelCluster 3 configuration files in the EnginFrame admin portal. The ParallelCluster configuration file is designed as a simple YAML text file for describing the resources needed for your HPC applications and automating their provisioning in a secure manner. Once a ParallelCluster configuration is registered within EnginFrame, you can start and stop clusters as necessary. The cluster will scale the compute resources based on the number of submitted jobs, according to your defined scaling criteria and node types, up to the limits you set for running instances. Once the submitted jobs are complete, ParallelCluster is designed to automatically stop the compute instances it created, by scaling down to the minimum number of instances you defined, which is usually zero. At that point, only the head node remains running – ready to receive new jobs. Figure 2 has a high-level architecture diagram showing AWS HPC Connector in EnginFrame working in concert with ParallelCluster to stand up resources on AWS.
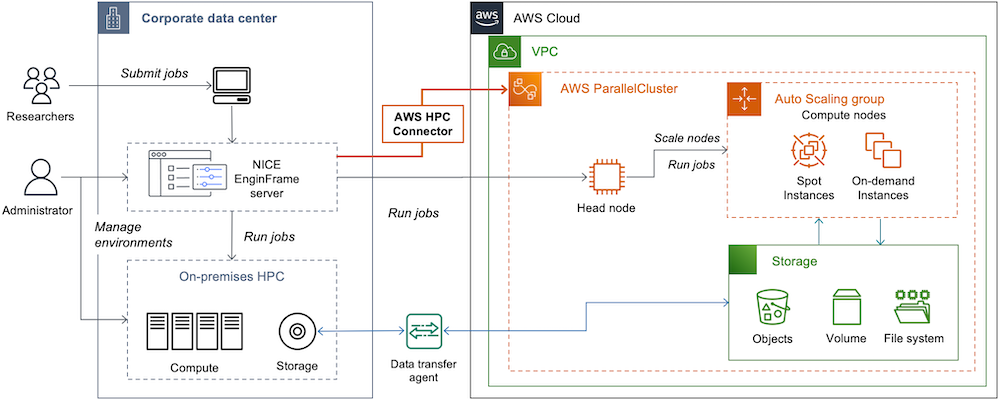
Figure 2: High-level architecture of NICE EnginFrame AWS HPC Connector.
Using AWS HPC Connector
Let’s take a quick look at AWS HPC Connector in action. For this demo, we’re using a preconfigured EnginFrame installation.
When you login as an EnginFrame administrator, you’ll see a section in the Admin View called “AWS Cluster Configurations”. This is where all the ParallelCluster configuration files are located. Figure 3 shows that we already have a cluster registered.
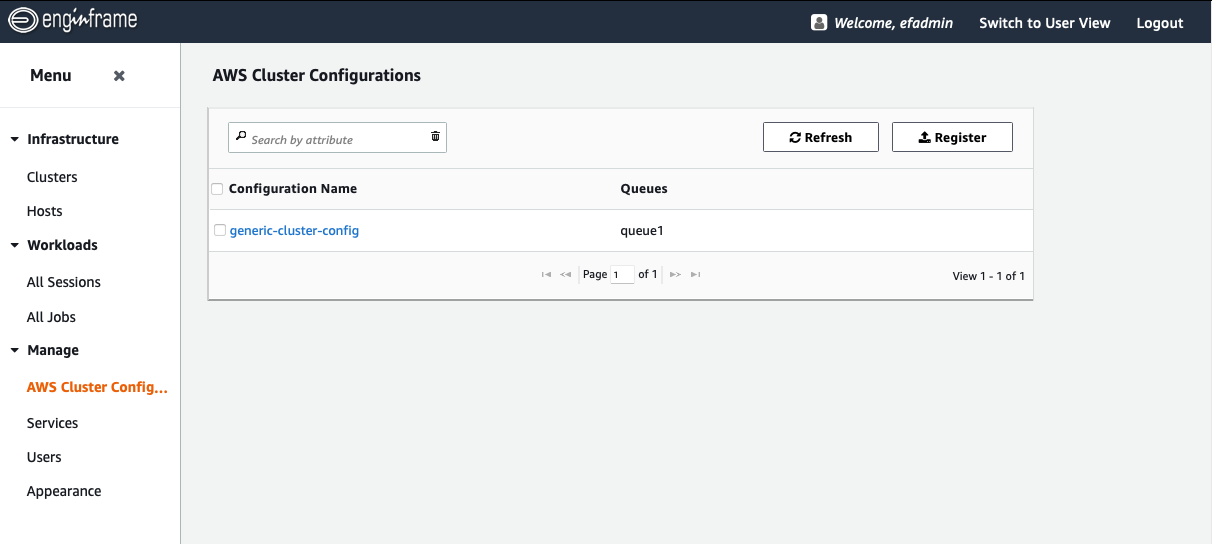
Figure 3: The AWS HPC Connector view showing the currently registered AWS ParallelCluster configurations.
To add a new configuration file, click on “Register” to either upload an existing configuration file, or to paste one into a text box. For this post, we opted to copy/paste from an existing ParallelCluster config file (Figure 4). Since we want to use this new cluster for tightly coupled computational fluid dynamics, we will want to define some beefy compute nodes — specifically c5n.18xlarge nodes with Elastic Fabric Adapter (EFA) enabled and within a placement group.

Figure 4: Registering a new AWS ParallelCluster configuration in EnginFrame. The parameters to note are that we define appropriate compute nodes for CFD — c5.18xlarge with EFA enabled in a placement group.
Once the configuration is registered, you can start the cluster by choosing Create cluster.
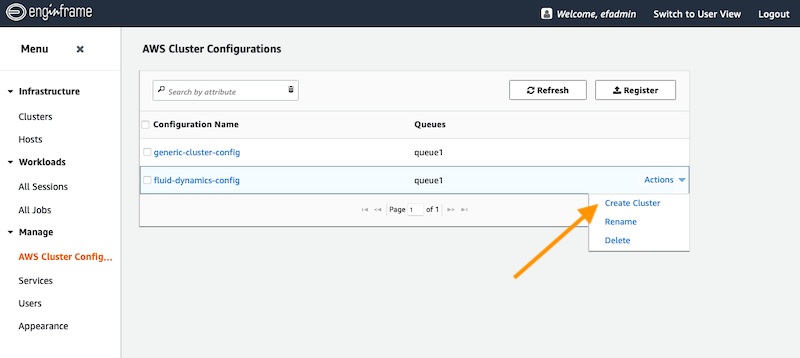
Figure 5: Creating the cluster from the Actions drop-down list.
When the cluster is started, you can view it in the Infrastructure → Clusters view (Figure 6).
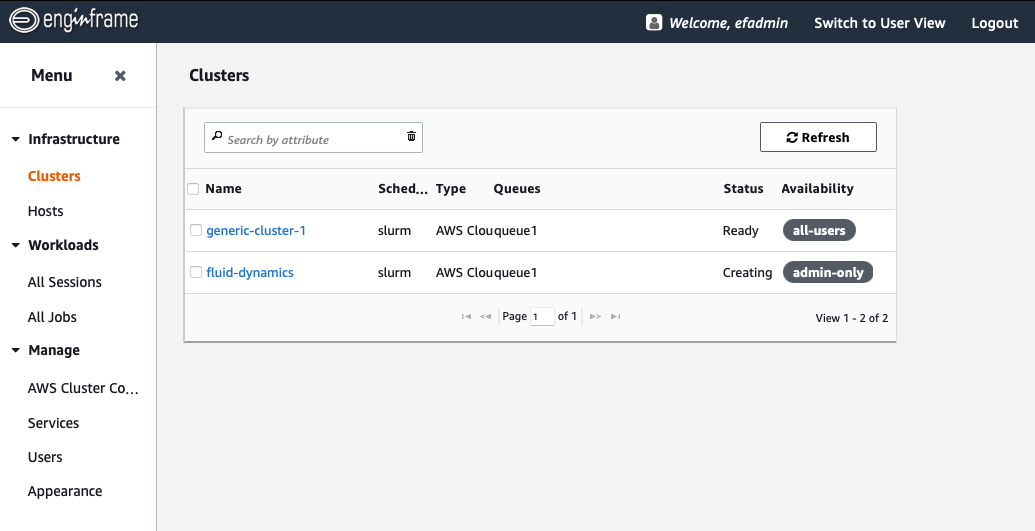
Figure 6: The Infrastructure Cluster view in EnginFrame showcasing that two clusters are viewable to all users, but the newly added cluster is restricted to the administrator.
Note that new clusters are only visible to the administrator. For your users to be able to leverage these new resources, you’ll need to allow them to view it as we show in Figure 7. This lets you set up, tweak and test new configurations before you’re ready to deploy to your users.
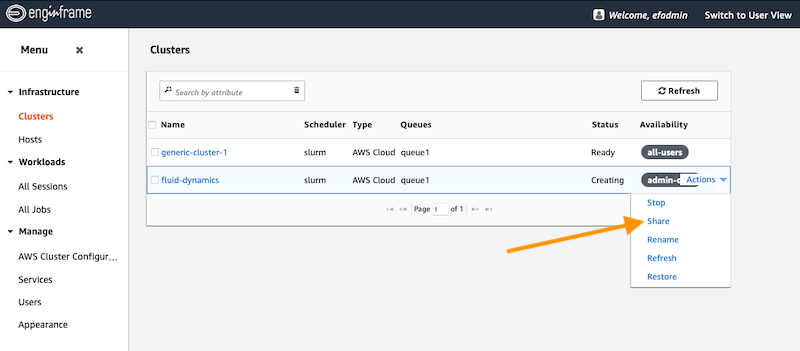
Figure 7: Sharing the newly created cluster with users.
Now that the cluster is registered, you’ve started it, and made it available to your users, you can use this as a resource when you’re defining EnginFrame services. The example in Figure 8 shows the admin view where we create a service (a web form) for Ansys Fluent. In Figure 9 we show the user’s view of that same service – where they’re choosing which cluster to run their analysis on.
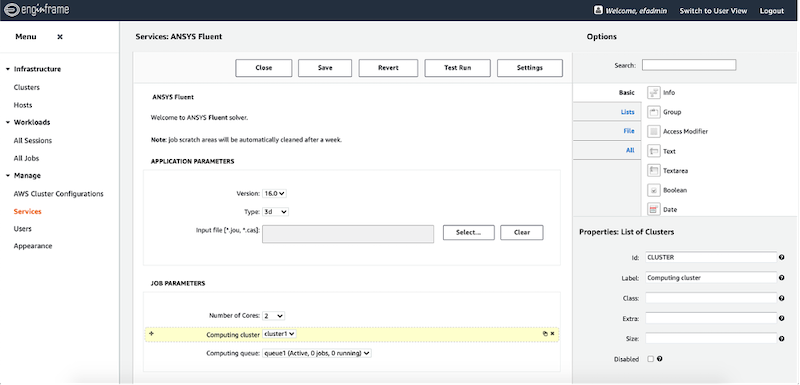
Figure 8: The administrator view of creating a web form for Ansys Fluent.
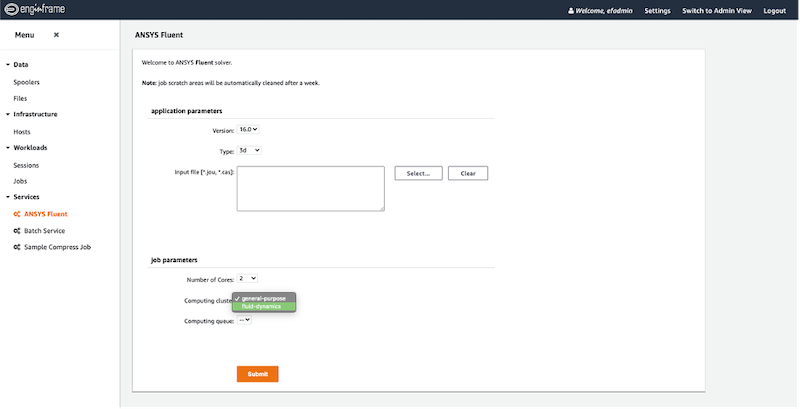
Figure 9: The user’s view of submitting an Ansys Fluent job, offering a choice of compute resource to use in this submission.
When to use AWS HPC Connector
Now that you have a sense for how to use EnginFrame AWS HPC Connector, let’s tackle why and when to use it:
Cloud bursting – Most on-premises HPC systems have a static footprint of compute, and are often run close to their maximal capacity. This makes it difficult (sometimes impossible) to run large out-of-band analysis requests because you’re either going to wait days or weeks for runtime, or impact others’ wait-times because you’ve de-prioritized their work to make way for yours. Infrequent but regularly-scheduled workloads are also a good target for this kind of cloud bursting. While it would be nice to have extra resources reserved for these episodic requests, it doesn’t make much economic sense because they’d go idle for most of the year.
Workload migration – Since NICE EnginFrame provides a job submission portal interface to users, administrators can change the underlying compute resource that any application runs on while still providing them a consistent interface. This comes in handy in different scenarios like long maintenance windows, equipment decommissioning, or even for moving workloads to the cloud closer to upstream or downstream data flows (or just closer to collaborators).
Cloud-only HPC – Cloud is still new to a lot of customers. We think EnginFrame makes AWS more accessible to HPC administrators and end-users who might be unfamiliar with how to set up, access, and run jobs in the cloud. AWS HPC Connector for EnginFrame provides administrators a helping hand to adopt cloud leveraging familiar concepts and advanced tooling to integrate their applications, data, and users.
There is a lot more to cover
As we mentioned, EnginFrame is a product for managing and making available complex HPC systems. It should come as no surprise, then, that we’ve only scratched the surface of what EnginFrame can do in this short blog post.
In future posts, we’ll dive into the details and best practices for service definitions and data management. We’ll also cover resource allocation for interactive and non-interactive jobs, and of course, user management. We’ll strive to help you think about hybrid HPC services differently, and show you some ways that other AWS services can solve problems, too.
Conclusion
In this post, we introduced a NICE EnginFrame AWS HPC Connector, a new EnginFrame plugin that allows for creation and management of remote HPC clusters on AWS. We gave some background on EnginFrame and a high-level overview of how AWS HPC Connector works from the perspective of the administrator.
We want to meet our customers’ needs for maximizing their on-premises investments while also getting the benefits of AWS. NICE EnginFrame AWS HPC Connector is our first step towards enabling some really imaginative hybrid HPC deployments, and we’re excited for you to try it out.
There’s no additional charge for using EnginFrame on AWS. You only pay for AWS resources you use to store data and run your applications. When using EnginFrame on-premises, you will be asked for a license file. To obtain an evaluation license, or to purchase new production licenses, please reach out to one of the authorized NICE distributors or resellers who can provide sales, installation services, and support in your country.
We’re pretty excited about enabling hybrid HPC capabilities for our customers, and curious to see what you do with them. This is just a taste of what’s possible with hybrid HPC, and we look forward to your feedback to help us shape what comes next.
To try out NICE EnginFrame AWS HPC Connector on AWS, check out the EnginFrame documentation. It’ll guide you through all the steps for standing up EnginFrame on AWS — deploying EnginFrame, registering a ParallelCluster configuration, through to running your first job.
For more information on NICE EnginFrame visit our product page.