AWS for Industries

Author: Sujaya Srinivasan
Sujaya Srinivasan is a Solutions Architect specializing in Genomics and Life sciences. She has a strong background in both technology and bioinformatics, and has more than a decade of experience working in oncology, clinical genomics and pharma. She is passionate about using technology to accelerate research and discovery in life sciences, genomics and precision medicine.

Hummingbird – a tool for effective prediction of performance and costs of genomics workloads on AWS
Blog guest authored by Utsab Ray, Amir Alavi, Amit Dixit, Vandhana Krishnan, and Amir Bahmani from Stanford University. Genomics researchers often face challenges in accurately estimating the compute and memory resources required for their workloads as they work to migrate their data processing to the cloud. AWS cloud computing infrastructure offers scalable and cost-effective solutions […]

Perform interactive queries on your genomics data using Amazon Athena or Amazon Redshift (Part 2)
This is part 2 of a blog series – see part 1 for how to generate the data that is used in this blog. One of the main objectives of creating a data lake is to be able to perform analytics queries across large datasets to gain insights that would not be possible if the […]

Build a genomics data lake on AWS using Amazon EMR (Part 1)
As data emerges from population genomics projects all over the world, researchers struggle to perform large-scale genomics analyses with data scattered across multiple data silos within their organizations. In order to be able to perform more sophisticated tertiary analysis on genomics and clinical data, researchers need to be able to access, aggregate, and query the […]
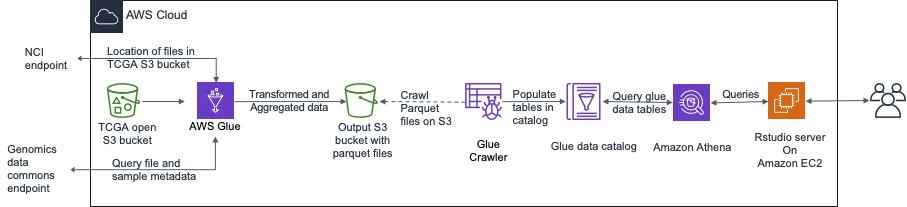
Enabling the aggregation and analysis of The Cancer Genome Atlas using AWS Glue and Amazon Athena
The Cancer Genome Atlas (TCGA) is a landmark cancer genomics program, producing molecular data for nearly 20,000 primary tumors and matched normal tissues from 11,328 patients across 33 cancer types. The TCGA includes germline and somatic variants, copy number variants, mRNA expression, miRNA expression, DNA methylation, and protein expression for most patients. In addition to […]