AWS for Industries
Flexible Telecom AI Workload Deployment Across AWS Hybrid Cloud
As telecommunications operators deploy AI across their networks, they face a fundamental architectural challenge: where should each AI function run? The answer is rarely “all in the cloud” or “all at the edge.” Each phase of the AI lifecycle (data preparation, training, context creation, inference, and optimization) has distinct requirements that map to different infrastructure tiers.
Today, multiple AWS content resources address individual pieces of this puzzle: the Well-Architected Machine Learning Lens covers cloud versus edge deployment evaluation, the Data Residency and Hybrid Cloud Lens provides guidance on Outposts and Local Zones for data sovereignty, AWS Prescriptive Guidance documents Retrieval-Augmented Generation (RAG) architecture options, and SageMaker HyperPod tutorials cover foundation model training on Trainium. However, no single reference consolidates these into a unified view that architects can apply systematically across the full AI lifecycle.
This paper introduces a structured placement approach for AI workloads across AWS hybrid infrastructure. By evaluating each AI lifecycle phase against four dimensions (data sovereignty, latency, data gravity, and operational readiness), architects can determine the optimal deployment tier among AWS Regions, AWS Local Zones, AWS Outposts and AWS AI Factories.
Using a production 5G telecom scenario, we apply the approach to show how placement decisions compound across lifecycle phases. For example, positioning a fine-tuned small language model at the edge for semantic filtering reduces the token volume that reaches cloud-based inference by up to 90%. At the same time, this placement satisfies data sovereignty constraints, meets sub-second latency requirements, and respects data gravity.
Telecom AI Lifecycle & Infrastructure Implications
Before deciding where to place workloads, architects need to analyze each phase of the AI lifecycle and its infrastructure requirements. Each phase has a characteristic blend of compute intensity, memory bandwidth, storage throughput, network latency sensitivity, and data sensitivity.
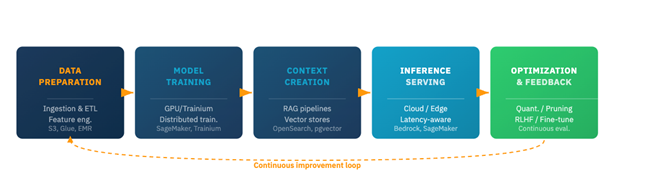
Figure 1: The five phases of the AI system lifecycle.
Several key observations shape placement decisions:
Training is cloud-native by nature. Pre-training telecom-specific models (alarm classification, anomaly detection, or protocol-aware language models) demands massive parallel processing across hundreds of GPUs with petabit-scale interconnects. AWS Regions, equipped with purpose-built accelerators such as AWS Trainium2 and the associated UltraCluster networking fabric, are the infrastructure tier where this is economically and technically practical.
Context creation follows data gravity. RAG pipelines must be co-located with the operational knowledge base they index. If that knowledge base (network configuration databases, trouble ticket history, vendor documentation) lives on-premises for compliance reasons, the embedding model and vector store should live there too.
Inference is where placement decisions become most complex. The same foundation model may need to serve millisecond-latency alarm triage at the network edge for one use case and batch root-cause analysis from an AWS Region for another. A well-designed AI system externalizes the inference routing logic so that placement can be adjusted without rearchitecting the application.
Optimization spans the hybrid infrastructure. Cloud environments support automated hyperparameter tuning and distributed training. Edge deployments in central offices or cell-site aggregation points require aggressive model compression (quantization, pruning, and knowledge distillation) to satisfy the memory and compute budgets of on-premises network equipment. The optimization pipeline must be designed to produce deployment artifacts targeting each tier.
AWS Hybrid Cloud Infrastructure Components
AWS provides four primary infrastructure tiers that together form a coherent, API-consistent hybrid cloud infrastructure. Each tier is designed for a specific range of workload characteristics and compliance profiles.
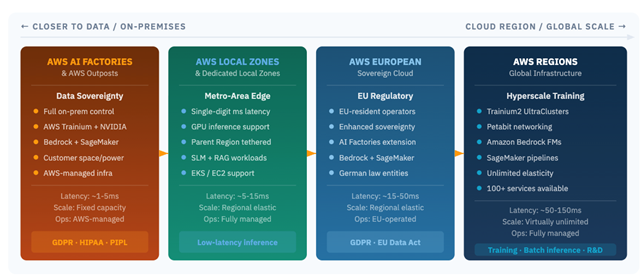
Figure 2: The four primary tiers from dedicated on-premises AI infrastructure (left) to global AWS regions (right).
AWS Regions: The Engine of Scale
AWS Regions provide the foundation for large-scale AI development, hosting the latest generation of accelerators: AWS Trainium2 in UltraCluster configurations with up to 100 Gbps inter-node bandwidth, alongside virtually unlimited elastic storage and the complete catalog of AI services. These AWS Regions are the natural home for pre-training and fine-tuning of foundation models, large-scale batch inference, and workloads where data residency is not a binding constraint.
AWS Local Zones: Metropolitan-Area Edge
AWS Local Zones extend the AWS infrastructure footprint into metropolitan areas, delivering single-digit millisecond latency to end users while maintaining full API integration with the parent region. Available in over 30 metropolitan areas globally, Local Zones support GPU-accelerated inference workloads. AWS Dedicated Local Zones offer an isolated variant for stricter residency requirements, such as those imposed by national telecom regulators.
AWS Outposts: On-Premises Native
AWS Outposts brings native AWS services directly into customer data centers as fully managed physical infrastructure. AWS Outposts runs the same hypervisor, container runtime, and control plane as AWS Regions, eliminating the integration complexity that typically burdens hybrid architectures. Organizations retain complete control over the physical location of their sensitive data that can stay on-premises. It is also possible to anonymize data locally on AWS Outposts before transmitting to a parent Region for foundation model fine-tuning. This exemplifies the privacy-preserving hybrid pattern.
AWS AI Factories: Sovereign-Scale AI Infrastructure
Announced at AWS re:Invent 2025, AWS AI Factories represent the most significant evolution of the on-premises AWS infrastructure model. Where AWS Outposts extends classic compute and storage to customer data centers, AI Factories deliver hyperscale AI training and inference in a fully managed fashion. The hardware includes Trainium2 accelerators, NVIDIA GPUs, petabit-scale networking, and high-performance storage. Customers provide data center space and power capacity; AWS deploys, operates, and maintains the complete infrastructure stack. This resolves the historically binary choice between on-premises control and AWS Cloud-scale AI capability.
Why API-consistent hybrid infrastructure matters for AI workload placement
This approach works only if workloads can move between tiers without code changes. That requires API consistency across all deployment locations: the same container runtime, the same ML serving APIs, and the same orchestration primitives on every tier. AWS has the capability to deliver this API consistency across deployment tiers. Amazon Elastic Kubernetes Service (Amazon EKS) runs the same Kubernetes control plane on Regions, Local Zones, and Outposts, enabling containerized ML inference workloads to deploy identically across tiers. A model fine-tuned in a Region can be packaged as a container and served on EKS on Outposts using the same deployment manifest. For agentic workflows, Amazon Bedrock AgentCore can invoke tools hosted on any tier via Model Context Protocol (MCP) Gateway, enabling an orchestrator in the cloud to call sub-agents or tools running on-premises.
A Design for Optimal Telecom AI Workload Allocation
The principles presented here evaluate workload placement across four dimensions, applied in order of precedence. Hard constraints are evaluated first and serve as eliminators; soft factors are optimized within the remaining feasible set.
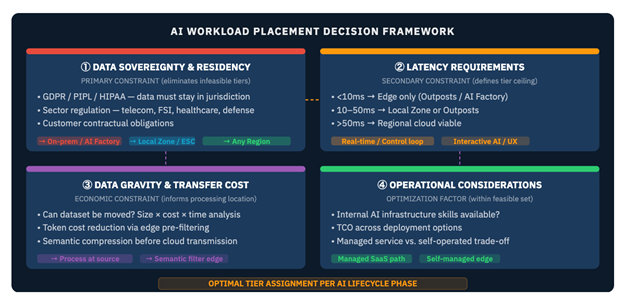
Figure 3: The four-dimension workload placement model.
Dimension 1: Data Sovereignty and Residency
Data residency requirements constitute the primary constraint because they are binary: data either can or cannot leave a defined boundary. Telecom operators must catalog their network data by sensitivity class: subscriber PII, location data, signaling records, and aggregated KPIs. Each class maps to a regulatory framework. This analysis has three components: discovery, cataloging and establishing ownership. The output eliminates infeasible deployment tiers before any performance or cost consideration.
Dimension 2: Latency Requirements
Applications requiring real-time responses under 10 milliseconds (such as 5G network policy enforcement, real-time alarm correlation, and automated traffic rerouting) are latency sensitive. Workloads tolerating 10–50ms can leverage AWS Local Zones for metropolitan-area deployment. Batch and asynchronous inference for document processing, overnight analytics, or offline recommendations can run efficiently from any Regional tier.
Dimension 3: Data Gravity
For many AI workloads, data is bound to its source infrastructure by regulation or technical architecture. In this scenario, the correct response is to move inference to the data. Deploying a Small Language Model (SLM) on AWS Outposts or AWS AI Factories co-locates the model with the data it consumes, eliminating the network hop entirely and preserving regulatory boundaries. This is a sound architectural choice regardless of cost, because both physics and regulation require local processing.
Dimension 4: Operational Considerations
Cloud-based deployment minimizes burden through fully managed services: no hardware procurement cycle, no firmware update process, no on-call rotation for infrastructure incidents. Edge deployment requires internal expertise in model optimization for network equipment constraints, distributed operations across central offices, and edge fleet management across potentially thousands of sites. Operators that lack this expertise should plan for a capability build or partner engagement before committing to edge-heavy architectures.
Table 1: Default Placement Recommendations by AI Lifecycle Phase
| AI Lifecycle Phase | Primary Tier | Conditions for Edge Placement | Key AWS Services |
|---|---|---|---|
| Data Preparation | AWS Region | Data residency prevents cloud transfer | Amazon S3, AWS Glue, Amazon EMR |
| Foundation Model Training | AWS Region | AI Factory if sovereignty requires on-prem training | SageMaker, AWS Trainium2, EC2 P5 |
| Fine-Tuning / Parameter-Efficient Fine-Tuning (PEFT) | AWS Region | Sensitive training data cannot leave on-prem | SageMaker, Amazon Bedrock fine-tuning |
| Context Creation (RAG) | Follows data | When knowledge base is on-prem | AWS Outposts/AI Factory |
| Real-time Inference (<10ms) | Outposts / AI Factory | Always | Custom inference containers on EKS (Outposts) |
| Interactive Inference (10–50ms) | Local Zone | When data residency allows metropolitan deployment | SageMaker, EKS on Local Zones |
| Batch / Async Inference | AWS Region | When data can be transferred | Amazon Bedrock Batch, SageMaker Batch |
| Edge Pre-filtering (Semantic) | Outposts / AI Factory | Always when data gravity is a driver | Custom SLM on EKS (Outposts) |
| Model Optimization | AWS Region | Quantization artifacts deployed to edge tier | SageMaker, Amazon Bedrock Model Distillation |
| Agentic Orchestration | Hybrid | Sub-agent proximity to data; orchestrator in cloud | Amazon Bedrock AgentCore (Region) + RAG tools on EKS (Outposts/AI Factory) |
Table 1. Default placement recommendations by AI lifecycle phase. “Follows data” in the Content Creation (RAG) phase indicates the tier is determined by the location of the knowledge base or data source, not fixed infrastructure preference.
Applying the Framework: Hybrid Inference in a 5G Telecom Scenario
This scenario demonstrates how all four dimensions converge on a single architectural decision: deploying a fine-tuned SLM at the edge.
Dimension 1 (Sovereignty): 5G signaling records contain subscriber identifiers and location data subject to national telecom regulations. In many countries, these records cannot leave the operator’s data center boundary.
Dimension 2 (Latency): The network management plane requires sub-second access to alarm telemetry to enforce Quality of Service (QoS) policies and respond to failure events. Cloud round-trip latency is incompatible with this requirement.
Dimension 3 (Data Gravity): Raw signaling records (AMF, SMF, UPF telemetry) reside on dedicated appliances within the operator’s data center, tightly coupled to adjacent network elements. Moving this data to a cloud region would require moving the network infrastructure itself.
Dimension 4 (Operational Readiness): A 7B–13B parameter SLM deployed on AWS Outposts runs as a managed inference endpoint, requiring limited ML operations. The model is fine-tuned in an AWS Region and deployed as a quantized artifact to the edge tier.
Token economics reinforce the placement decision
Each alarm event spans 15,000–25,000 tokens in raw format. At 1,000 events/hour, direct cloud-based inference costs $52/hour. Edge semantic filtering compresses to 2,000 tokens per event, a 90% reduction, making cloud reasoning economically viable for the subset that requires deeper analysis.
The result is a two-tier architecture where the edge SLM handles sovereignty, latency, and data gravity simultaneously, while the cloud LLM provides reasoning depth on the pre-filtered, token-efficient output.

Figure 4: Token cost comparison for a representative 5G telecom AIOps scenario.
An LLM reasoning over a 2,000-token summary produces higher-quality analysis than one navigating 20,000 tokens of protocol boilerplate. Signal-to-noise ratio in the context window directly affects output quality, as demonstrated in the published studies Collaborative Inference and Learning between Edge SLMs and Cloud LLMs: A Survey of Algorithms, Execution, and Open Challenges (Li, S., Wang, H., Xu, W., et al.) on long-context LLM behavior.
Model selection strategy for the two-tier pattern: For the edge tier, select for domain specificity and inference efficiency. Smaller fine-tuned models often reach the same accuracy as general models on structured extraction tasks. The cloud LLM should be selected for reasoning depth. Claude models or Amazon Nova Pro work well because the compressed input keeps costs manageable at premium per-token rates. Amazon Bedrock’s Intelligent Prompt Routing can further optimize cost within the cloud tier by dynamically routing simpler queries to lighter models while preserving response quality for complex reasoning tasks.
Getting Started: Four Steps for Telecom Operators
For telecom operators maturing an AI strategy on AWS, the following sequence of actions maps directly to the four dimensions of the placement guidance:
- Conduct a data classification and regulatory mapping exercise across all network telemetry, subscriber data, and AI training datasets. Identify which datasets are subject to residency constraints (typically subscriber PII and raw signaling), which are freely movable (aggregated KPIs, anonymized traffic statistics), and which occupy a grey area requiring legal review.
- Instrument existing AI workloads for latency percentile measurement: P50, P95 and P99 for Time to First Token and full round-trip latency. Without empirical baselines, the latency dimension cannot be applied rigorously.
- Build a token volume and cost model for each AI function. Estimate raw token counts, apply a compression ratio (60% floor, 90% target for tuned SLMs), and calculate the savings against cloud-based inference spend.
- If the telecom operator runs central offices or data centers with network telemetry that cannot move to an AWS Region, evaluate AWS Local Zones, AWS AI Factory or AWS Outposts. AWS manages the infrastructure stack, so internal AI hardware expertise is not a prerequisite.
Deploying AI at scale requires preparation. Architects must analyze what data they have, where it must live, how fast applications need to respond, and what their organization can operate. This guidance replaces an open-ended design space with a structured set of choices. Regulatory, latency, and data gravity constraints become the conditions under which the most resilient architectures are built.