AWS Trainium
Purpose-built AI chips to deliver high performance and the best economics for AI training and inference at scale
Why Trainium?
AWS Trainium is a purpose-built AI chip designed for one goal: the best economics for high performance AI training and inference at scale. Today's AI builders face two pressures: train models faster to keep pace with innovation, and serve end users at the performance they expect. Lower the cost of both, and you unlock more experiments, faster iteration, and broader reach. The infrastructure behind every foundation model, every agent, every real-time AI experience determines training speed, inference performance, and the cost of both. The system that delivers the best training and token economics wins. Achieving that requires higher speed, lower cost, accessibility, scale, fault tolerance, and developer velocity. Trainium is at the center of a fully integrated system: chip, server, network, software, and services - purpose-built at every layer and co-designed to work as one.
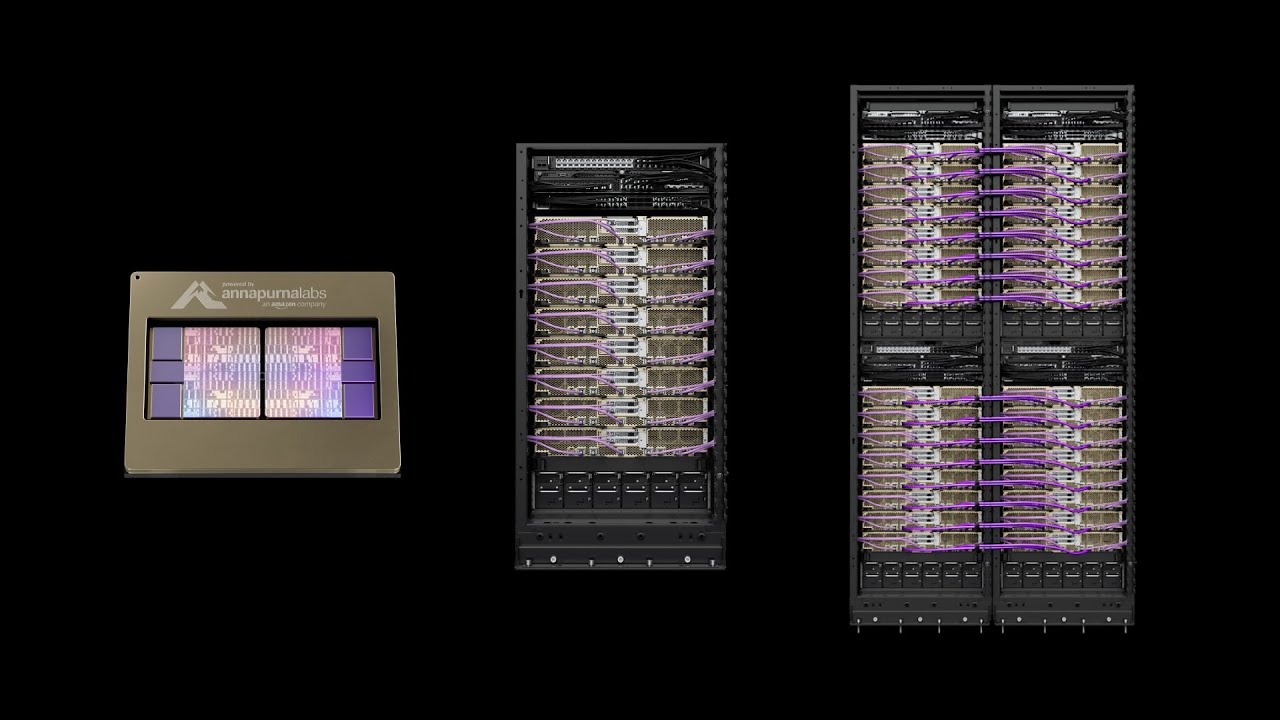
Benefits
Every dollar saved in training is reinvested in the next iteration. Every token served at lower cost means more users, more interactions, more value per dollar. Trainium delivers better cost-per-token at production scale for AI workloads that demand the highest performance — because every layer of the system was designed to minimize waste.
Trainium is purpose-built. So is every layer around it: server, network, software, and services. Graviton as host CPU, Nitro secures, Elastic Fabric Adapter (EFA) scales, Neuron SDK makes it accessible, Amazon EKS as orchestrator, SageMaker HyperPod for managing large-scale AI computing. Every layer designed with the others in mind. A straight line from transistor to token.
Models are getting bigger and more complex. Training them faster demands more compute than any single chip can deliver. Trainium scales from a single chip to millions. The data center is now the new AI accelerator.
At scale, failures are constants, not exceptions. The architecture is designed for resilience: redundant NeuronLink lanes provide fault tolerance at the chip level, hot-swap switch trays enable component replacement without taking nodes offline, and purpose-built networking routes traffic across multiple paths. Orchestration services detect failures and reroute workloads across healthy nodes. Every layer works together to minimize downtime.
PyTorch, vLLM, HuggingFace, Ray — they work without modification. Your existing code runs as-is. No porting, no friction. Neuron Kernel Interface (NKI) gives you unparalleled access to the chip ISA - the same APIs used by the Trainium engineering team. Get started fast, iterate freely, and extract full performance from the chip when you're ready.
Features
Trainium3 contains eight large cores, four specialized engines each — Tensor, Vector, Scalar, GPSIMD — running simultaneously. Up to 2x MXFP8 compute throughput compared to Trainium2. Built-in hardware support for Mixture of Experts (MoE) routing. Optimized for the mathematical primitives that underlie frontier AI workloads.
144 GB HBM3e per chip, 4.9 TB/s bandwidth - 1.7x higher than Trainium2. Hardware-accelerated W4A8 quantization doubles effective weight-loading rate with zero software overhead. A two-level on-chip SRAM hierarchy sits between HBM and the compute engines, keeping data close to compute and minimizing costly memory round-trips. Designed to keep the compute engines fed so data movement is not the bottleneck.
Dozens of communication cores physically separate from compute. Zero contention between compute and communication. On-chip traffic prioritization ensures time-sensitive data moves first. Minimizes the straggler effect so chips spend more time computing and less time idling.
Up to 28.8 Tbps of aggregate scale-out bandwidth per UltraServer. Purpose-built networking that scales Trainium to millions of chips in a non-blocking, petabit-scale network. Every packet is distributed across all available paths to reduce congestion and hotspots.
Trainium3 Next Generation UltraServers scale up to 144 Trainium chips, delivering up to 362 MXFP8 PFLOPs, 20.7 TB of HBM3e, and 706 TB/s of aggregate memory bandwidth. NeuronSwitch provides an all-to-all fabric that doubles interchip interconnect bandwidth over Trainium2 UltraServers. Available in UltraClusters 3.0 to scale to hundreds of thousands of chips.
Neuron SDK: Built for How You Work
The Neuron SDK meets developers where they are — no rewrites, no workarounds, no friction.
Deploy models to production without becoming a hardware expert. vLLM, HuggingFace Transformers, and TorchTitan natively on Trainium — no custom code, no porting effort. Ray, Amazon EKS, and AWS Batch handle orchestration. Your existing stack works out of the box with better economics from day one.
Robust PyTorch support that lets you explore freely. Native eager mode, FSDP, and TorchTitan for rapid experimentation and debugging. One line of code to get started. Your ideas flow directly to silicon — no infrastructure fighting, no workflow changes, just faster iteration on better models.
Get unparalleled instruction-set-level access with the Neuron Kernel Interface (NKI). NKI.isa delivers direct hardware control; NKI.lang provides NumPy-like semantics for rapid kernel development. The open-source NKI Library offers production-ready optimized kernels. Neuron Explorer provides unparalleled visibility into the chips and systems to pinpoint bottlenecks instantly.
Deploy and manage infrastructure with the tools you already know — Ray, Slurm, Amazon EKS, Amazon ECS, and SageMaker HyperPod. Neuron Monitor delivers real-time health and utilization metrics. Hot-swap capability and redundant NeuronLink lanes mean minimizes maintenance. Deterministic compilation ensures reproducible deployments across environments.
Customers
Customers such as Anthropic, Databricks, Decart, Open AI, Ricoh, SplashMusic, Uber, and others, are realizing performance and cost benefits of Trainium instances and UltraServers.
Early adopters of Trainium3 are achieving new levels of efficiency and scalability for the next generation of large-scale generative AI models.

Conquer AI performance, cost, and scale

AWS Trainium2 for breakthrough AI performance

AWS AI chips customer stories

