AWS for Industries
Simplifying Enterprise Data Governance and Management in Regulated Industry
Introduction
Embarking on digital transformation initiatives often requires decommissioning legacy systems, exacerbating the complexity of preserving and accessing crucial data. Failing to address this issue effectively leads to data loss, operational inefficiencies, and potential regulatory violations, which can result in substantial fines and reputational damage.
Financial institutions must retain vast amounts of historical data, like transaction records, customer information, and trade details, to adhere to stringent regulatory requirements and maintain comprehensive audit trails.
To mitigate these risks and ensure compliance with data retention mandates, financial institutions leverage AWS-based solutions to centralize and manage legacy data in a secure and cost-effective manner. By implementing a data management and governance solution on AWS, organizations consolidate and store historical data from various sources, including retired systems, in a scalable and durable environment.
This centralized repository not only facilitates regulatory compliance but also allows users across the organization to access and analyze historical data for business intelligence, risk management, and strategic decision-making purposes.
This blog post expands on the previous discussion about record retention modernization for financial institutions on AWS. We’ll show how these concepts adapt into a universal pattern for data governance and management across any regulated industry.
The goal is to show how to apply the principles and approaches that work for financial record keeping more broadly, helping organizations in regulated sectors manage their data effectively while maintaining compliance.
Architectural Overview
The following are 10 crucial elements that emerge as the foundation for an effective and robust solution, based on the insights gathered from different lines of business across multiple financial institutions. These key success factors represent the core requirements that the solution must address to meet the needs of diverse stakeholders in the financial sector.
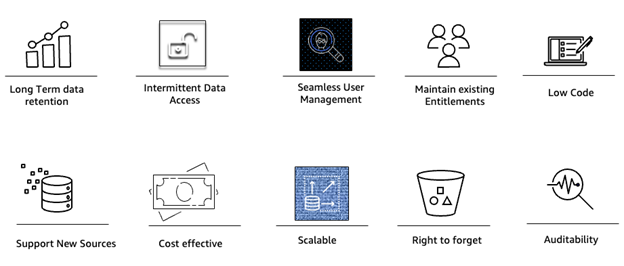
Figure 1 – Key Success Factors
10 Key Success Factors for the solution:
- Long-term data retention. Compliance with regulatory requirements for retaining data for 10 to 30 years.
- Flexible data access. Teams access data periodically without definitive patterns.
- Streamlined identity and access management. Efficient management of enterprise user identities and access rights.
- Preservation of current privileges. Ensure a smooth transition by retaining existing user entitlements.
- Minimal refactoring. Keep existing SQL queries with minimal modifications.
- Diverse data source support. Compatibility with various on-premises databases, including SQL Server and DB2.
- Cost efficiency. Optimize resource utilization and reducing operational expenses.
- Scalability. Accommodate growth in data volumes and user bases without compromising performance.
- Data deletion on demand. Enable the purging of records upon request, adhering to regulatory requirements.
- Transparency and accountability. Fostering trust through comprehensive auditing and reporting capabilities.
Based on these requirements, we can logically group the solution into four major parts.
- User access management
- Data ingestion and processing
- Enforcing data access at scale
- Low code analytics
Solution Architecture
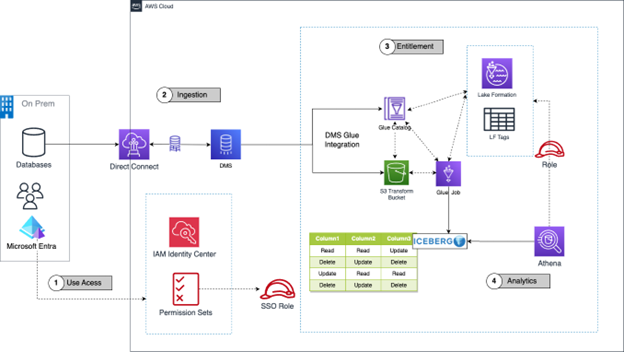 Figure 2: Architecture Overview
Figure 2: Architecture Overview
1. User access management
As organizations grow, managing access requirements at scale becomes increasingly challenging. Enterprises need a solution that helps centralize the management of human users and their permissions across multiple AWS accounts while integrating seamlessly with existing identity management systems.
AWS IAM Identity Center offers a comprehensive solution to these challenges. It serves as the AWS prescribed solution for connecting workforce users to AWS managed applications and AWS resources. This lets customers maintain their existing identity setup without disrupting current workflows.
By leveraging IAM Identity Center, customers leverage their existing identity provider, such as Okta or Microsoft Entra ID, synchronizing users and groups from the IdP directory using the SCIM protocol. This integration ensures that workforce users continue using their enterprise credentials and group memberships without any changes to their identity setup.
One of the key features of IAM Identity Center is Permission Sets. These permission sets act as templates that define collections of AWS Identity and Access Management (IAM) policies, for granular access control across multiple AWS accounts.
Permission sets in IAM Identity Center are highly flexible, supporting AWS managed policies, customer managed policies, and inline policies for job functions. This flexibility allows organizations to craft policies that restrict workforce users’ access to their specific workspaces or roles.
As an example, an organization creates a custom permission set named “Auditor,” configured to include specific policies that grant access to specific accounts and resources. The Auditor permission set might be configured to restrict access solely to the Auditor workgroup within Amazon Athena, allowing the user to run queries only within a designated area.
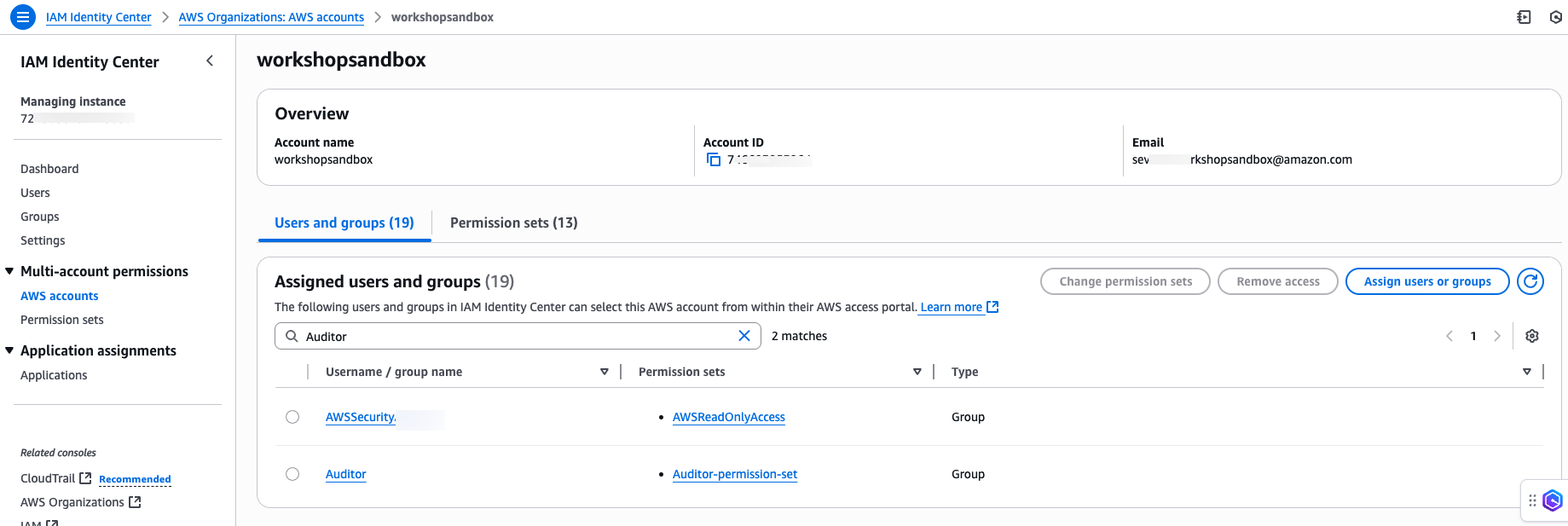
Figure 3: Auditor Group associated with an AWS Account
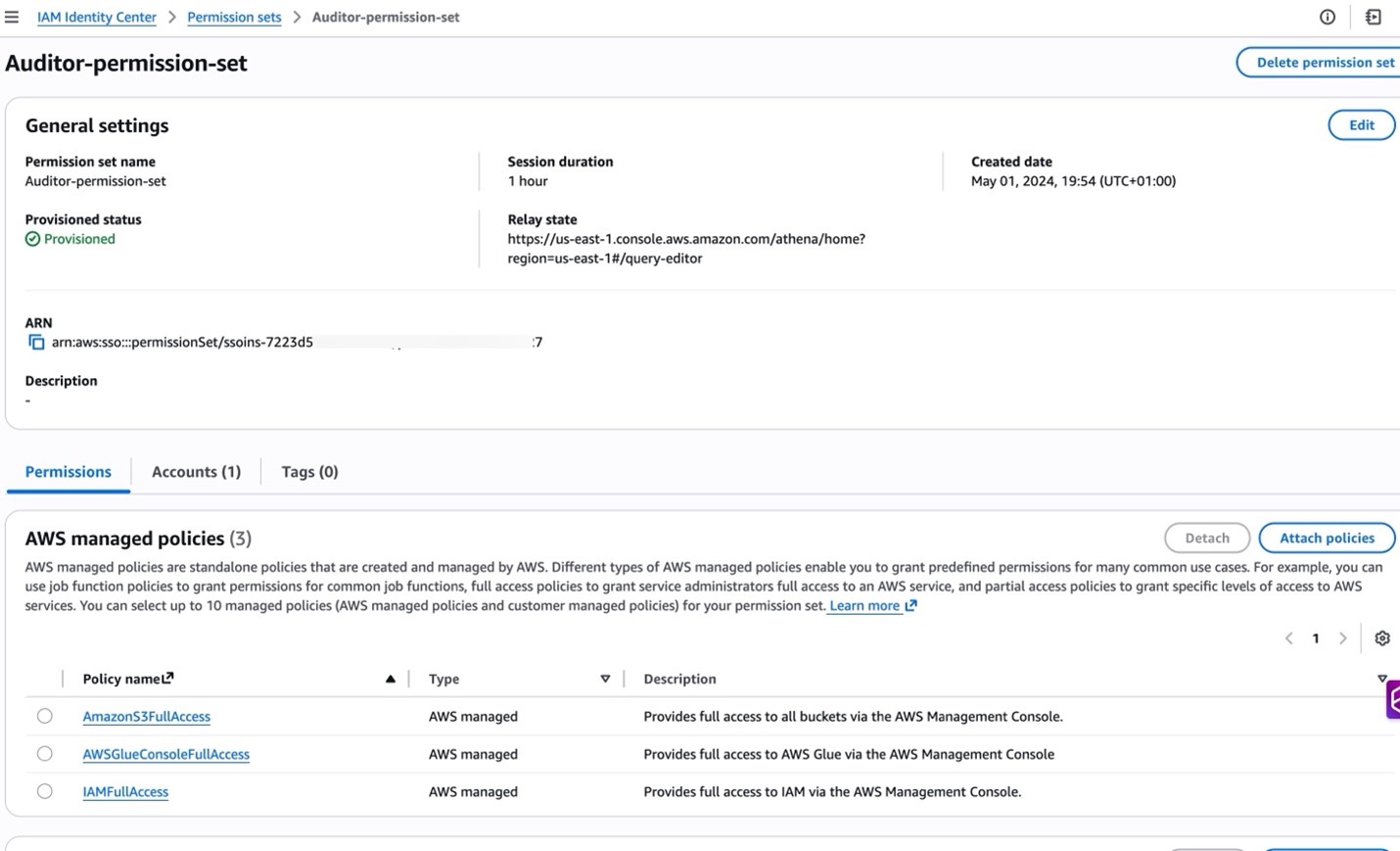
Figure 4: Auditor permission set and associated Policies
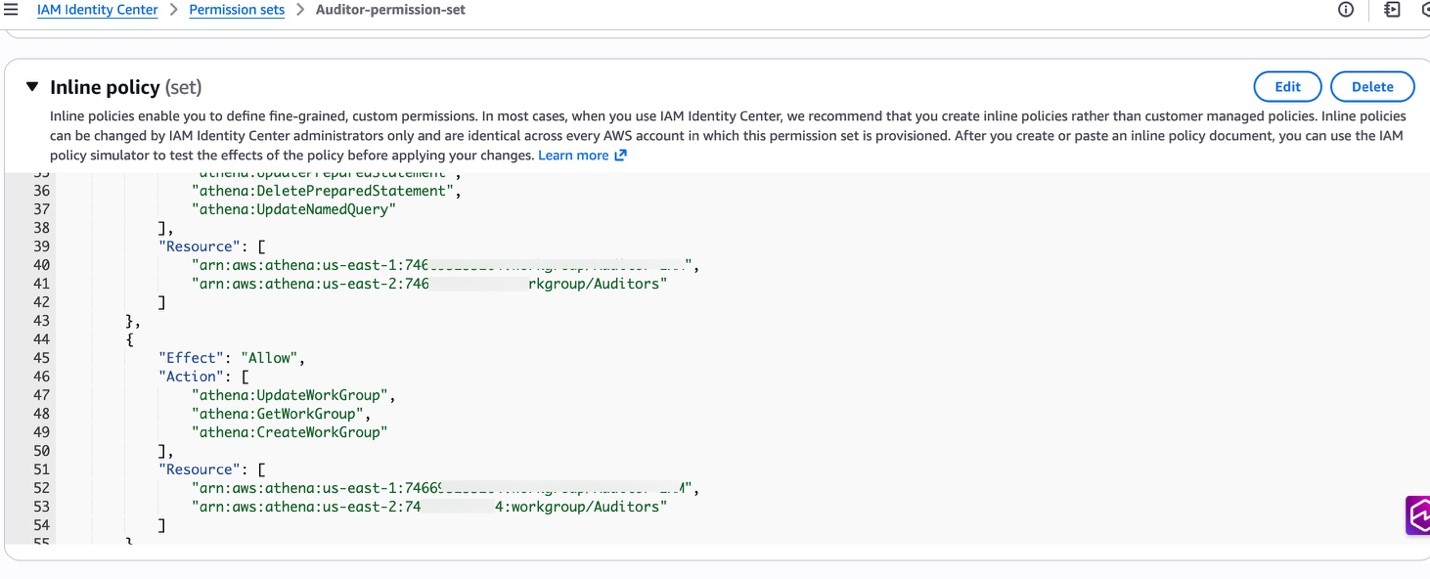 Figure 5: Inline Policy to restrict access to Auditor group.
Figure 5: Inline Policy to restrict access to Auditor group.
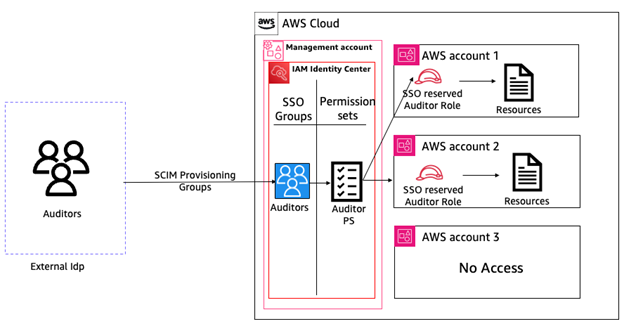
Figure 6: Relationship between External IdP, AWS IAM Identity Center and SSO Role
By leveraging IAM Identity Center, organizations can effectively manage access requirements at scale, ensuring secure and efficient management of user permissions across their multi-account AWS environment while maintaining integration with their existing identity infrastructure.
2. Data ingestion and processing
Data ingestion and processing present major hurdles for organizations, as the transfer of data between platforms is often a complex and repetitive process.
To address these challenges, there’s a pressing need for an advanced solution that offers the following capabilities:
- Compatibility with diverse database systems.
- Simplification of server-related intricacies like configuration management, maintenance, load balancing, security, interoperability
- Automatic optimization of capacity requirements.
- Autonomous schema detection and catalog generation.
AWS offers a comprehensive suite of services that directly address these challenges, providing a robust and efficient solution for data ingestion and processing.
At the heart of this solution is Amazon Simple Storage Service (Amazon S3), an ideal destination for your data. Amazon S3 offers highly scalable, durable, and secure object storage, capable of handling large amounts of data. You have the flexibility to store your data in Apache Parquet format. Alternatively, for tables that need frequent modifications, Apache Iceberg format is recommended. With the release of S3 tables, you can now leverage the full capabilities of Amazon S3 for even more efficient data management.
AWS offers a powerful tool called AWS Database Migration Service (AWS DMS) to migrate data from and to AWS. This managed service excels in both migration and replication tasks, providing a swift and secure method for relocating databases and analytics workloads to the AWS ecosystem.
A standout feature of AWS DMS is its ability to maintain full functionality of the source database throughout the migration process. This crucial aspect significantly reduces application downtime, allowing businesses to continue their operations with minimal disruption while their data is being transferred.
By leveraging AWS DMS, organizations efficiently move their data infrastructure to the cloud, benefiting from improved scalability, performance, and cost-effectiveness, all while ensuring business continuity during the migration phase.
AWS DMS Serverless: Optimizing Capacity Automatically
To abstract some nuances in using AWS DMS provisioned instances, we are specifically using AWS DMS Serverless for this solution. DMS Serverless eliminates the need for manual resource estimation and manages the operational complexities required for high-performance and continuous migration.
By automatically provisioning, scaling, and optimizing capacity, AWS DMS Serverless enables rapid data transfer initiation with minimal supervision.
Streamlined schema discovery and catalog creation
The solution combines the power of AWS DMS with AWS Glue for efficient schema discovery and catalog creation. When configuring the target endpoint for Amazon S3 in AWS DMS, you can enable a parameter that prompts AWS Glue to detect schemas and generate a corresponding catalog automatically.
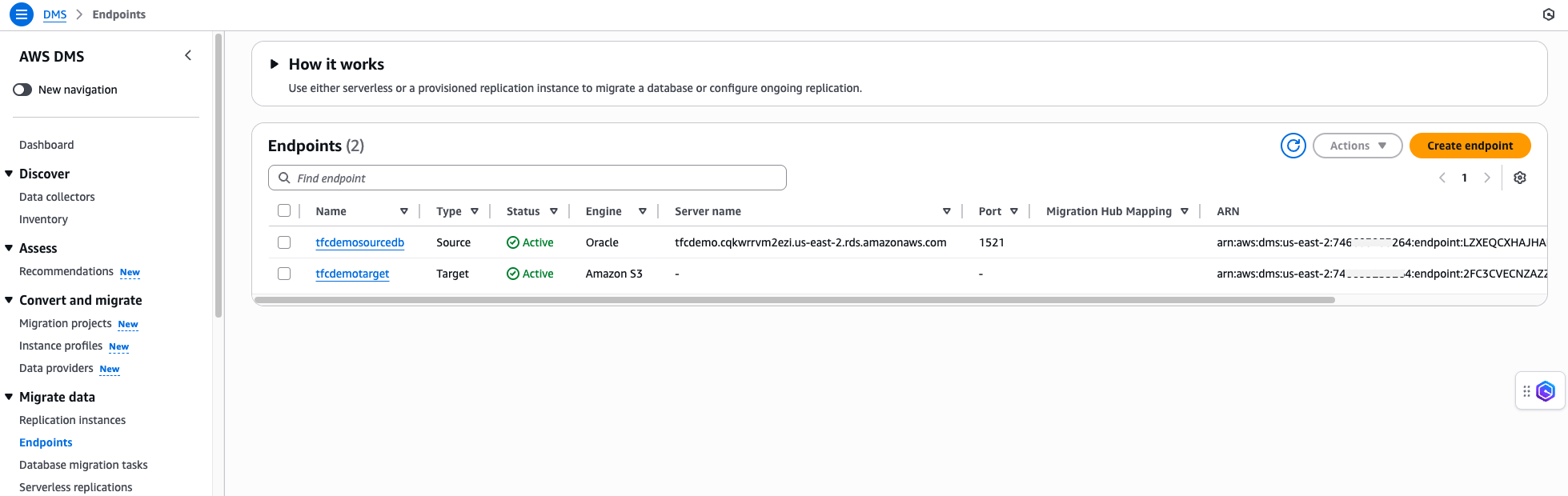
Figure 7: Configure DMS with source and target endpoints.
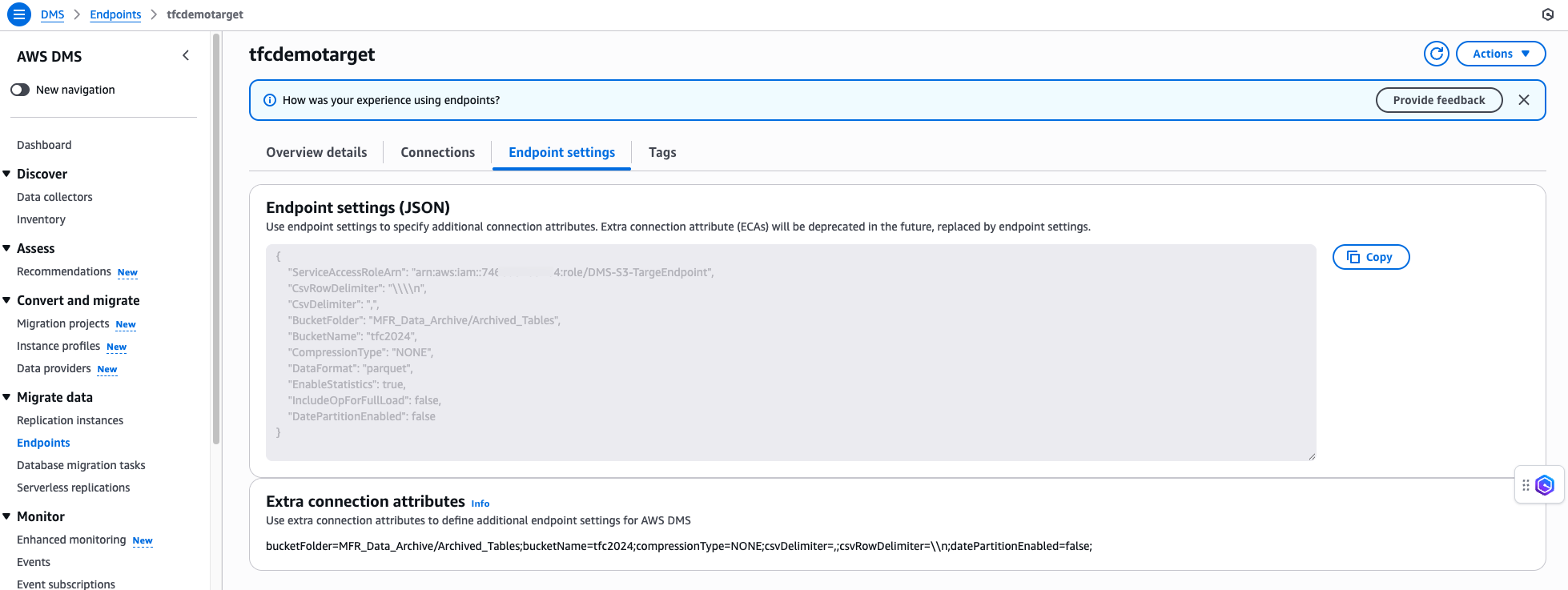
Figure 8: Settings for AWS DMS Target Endpoints
As a fully managed ETL service, AWS Glue simplifies data processing tasks while reducing associated costs.
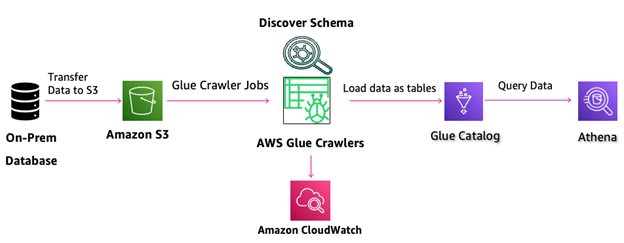 Figure 9: Schema Discovery using AWS Glue
Figure 9: Schema Discovery using AWS Glue
Comprehensive coverage for Apache Iceberg format
For data stored in Apache Iceberg table format, the solution allows for the creation of dedicated AWS Glue jobs. These jobs ensure thorough cataloging of your data assets, providing a complete overview of your data landscape.
By integrating these advanced features, the solution offers a comprehensive approach to data migration. It addresses key challenges in capacity optimization, schema discovery, and catalog creation across various data formats and storage systems.
3. Enforcing data access control at scale
As organizations migrate their data to AWS, a critical concern emerges: maintaining the integrity of existing access controls.
Enterprises face significant challenges in translating their current entitlement structures to new cloud-based data stores, particularly when dealing with multiple data sources, diverse user groups, and intricate permission hierarchies. The complexity intensifies when considering the need for fine-grained access control, scalability, and efficient permission management in the cloud environment.
This solution addresses these challenges by introducing a powerful capability: enabling users to access only the data they’re allowed to, based on their pre-existing permissions. By seamlessly transferring and enforcing current access rights, the solution ensures continuity in data governance practices while facilitating smooth data accessibility in the new environment.
Balancing storage needs with compliance and governance
The selective access feature offers a strategic advantage in balancing organizational storage requirements with data compliance mandates. It lets companies centralize data storage without compromising the integrity of different operational environments or exposing sensitive information. This approach is valuable for regulated industries and businesses committed to responsible data management.
AWS Lake Formation offers a powerful solution to address these data governance challenges. By using AWS Lake Formation, organizations create a secure, centralized data lake that provides fine-grained access control and simplifies permission management at scale.
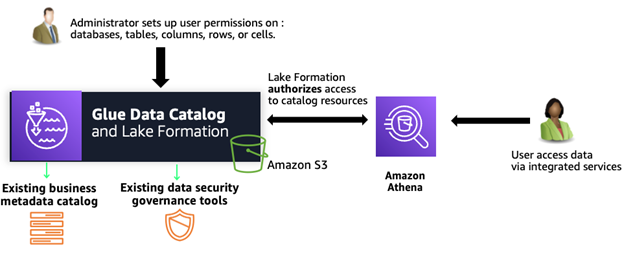
Figure 10: Capabilities of AWS Lake Formation
AWS Lake Formation offers several critical features to solve data access and governance challenges:
- Granular access control enables table and column-level permissions for precise data access management.
- Tag-based access control allows defining access policies based on metadata tags associated with data lake resources.
- Identity provider integration maps SSO roles to data tags, leveraging existing workforce entitlements.
- Centralized management provides a single platform for creating and managing data lakes, including access policies and security controls.
- Scalability facilitates managing access entitlements at scale using tag-based policies.
- Dynamic access control automatically applies appropriate access controls to new data based on associated tags.
- Auditing and compliance offer a centralized view of access permissions, simplifying auditing and compliance processes.
These features collectively enable organizations to maintain granular control over data access, integrate with existing identity systems, and ensure scalable, compliant data governance in their AWS data lake environment.
The ability to maintain granular access control within cloud data stores represents a significant advancement in data governance. It provides organizations with the tools to:
- Enforce consistent access policies across on-premises and cloud environments.
- Minimize the risk of unauthorized data access.
- Simplify compliance with industry regulations and internal policies.
- Enhance data security without sacrificing operational efficiency.
This solution empowers organizations to embrace cloud storage while maintaining strict control over data access, setting a new standard for efficient data management in the cloud era.
4. Low-code analytics
In today’s data-driven landscape, large organizations seek seamless data access without the burden of modifying queries or constantly adjusting access controls. This desire for simplicity and efficiency has led to a growing demand for sophisticated yet user-friendly analytics solutions.
Low-code analytics platforms are emerging as a crucial tool for organizations aiming to democratize data insights across their workforce. These platforms promise to empower employees at various levels with the ability to derive meaningful insights from complex datasets. However, implementing such solutions present its own set of challenges.
An ideal low-code analytics platform will encompass several essential features:
- Complexity abstraction. The platform must shield users from underlying technical intricacies, allowing them to focus on data analysis rather than system mechanics.
- Intuitive query interface. It will provide a user-friendly interface that facilitates the construction and execution of queries, even for those with limited technical expertise.
- Isolation and security. The platform must support robust isolation boundaries, ensuring users, teams, or groups will only access data relevant to their roles and responsibilities.
- Compliance Integration. With increasing regulatory scrutiny, the platform must address compliance requirements such as the “right to be forgotten” stipulated by GDPR.
AWS provides Amazon Athena, a serverless query service, as a comprehensive solution to these challenges. Amazon Athena allows users to analyze data stored in Amazon S3 using standard SQL queries, making it accessible to users with varying levels of technical expertise.
It abstracts the underlying complexities of data processing and provides a user-friendly interface for running queries, meeting the first two requirements of an ideal low-code analytics solution.
Amazon Athena’s workgroup feature addresses the third requirement by separating users and teams. Administrators set limits on the amount of data each query or entire workgroup will process, track costs, and apply identity-based policies to control access to specific workgroups.
For example, administrators restrict users to accessing only the Auditor workgroup in Amazon Athena.
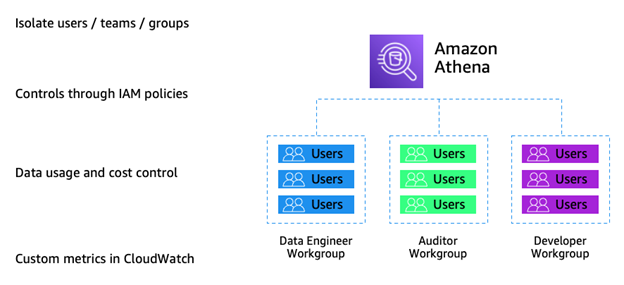
Figure 11: Example workgroups in Amazon Athena
Enterprises also use Amazon Athena to address the “right to be forgotten” use case, which requires organizations to add, modify, and delete records from their databases and data lakes. Organizations can create a logical pipeline by integrating Amazon Athena with AWS Glue and Apache Iceberg that not only deletes data from tables but also purges underlying data files.
Apache Iceberg, an open-source table format supported by various AWS services including Amazon Athena, provides features like snapshot and snapshot lifecycle management. This creates an efficient implementation of data deletion processes. Using Iceberg tables, organizations can run delete queries in Amazon Athena, creating new snapshots and deleting files. Subsequent optimization and vacuuming processes ensure purging older versions of snapshots and their associated data files, effectively implementing the “right to be forgotten.”
Amazon Athena, combined with AWS Glue and Apache Iceberg, provides a powerful, low-code analytics solution that addresses the challenges of data accessibility, user isolation, and compliance with data protection regulations. This comprehensive approach enables organizations to democratize data analytics while maintaining control and meeting regulatory requirements.
Conclusion
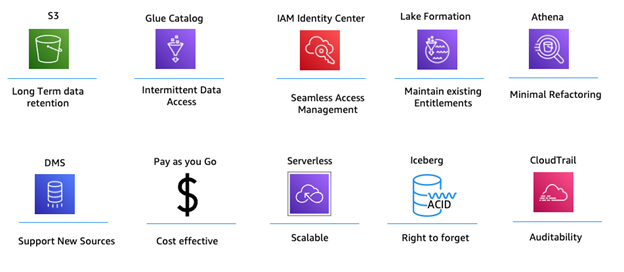
Figure 12: 10 key success factors of the solution.
In the ever-evolving financial services industry, where regulatory compliance and data governance are of paramount importance, the AWS-powered solution offers significant advantages. By harnessing the power of AWS IAM Identity Center, AWS Data Migration Service, AWS Glue, AWS Lake Formation, and Amazon Athena, this comprehensive approach addresses the critical challenges of user management, data ingestion, controlled access, and long-term data retention.
Tailored to meet the stringent regulatory retention requirements spanning 10 to 30 years, this solution enables financial institutions to transition to a centralized data lake environment while preserving existing entitlements and privileges. The centralized identity repository empowers administrators to assign granular permissions, ensuring fine-grained control over access rights and minimizing the risk of unauthorized access.
The solution’s scalability and adaptability empower financial institutions to accommodate evolving regulatory demands, such as the deletion of data upon request, fostering transparency and accountability throughout the data lifecycle. They can confidently embrace the challenges of data preservation, analysis, and modification, ensuring a seamless and secure journey towards regulatory excellence.
If your organization face challenges with respect to regulatory data management, we encourage you to evaluate how above AWS services and architectural patterns could address your specific requirements.
To learn more about S3 tables and its features visit Amazon S3 Tables.