AWS for Industries
How financial institutions modernize record retention on AWS
The regulatory landscape
Compliant record retention is a regulatory expectation for certain financial services institutions. The US Securities and Exchange Commission (SEC), Commodities Futures Trading Commission (CFTC) and the Financial Industry Regulatory Authority (FINRA) have recordkeeping rules that establish the types of records that regulated broker-dealers (BDs) must maintain. SEC and FINRA rules outline specific requirements that BDs must meet if they store these records on electronic storage media, such as Amazon Simple Storage Service (Amazon S3) or Amazon S3 Glacier. AWS customers often ask how to modernize their record retention programs while maintaining compliance with these recordkeeping rules. They have told us they are looking for better way to ingest, process, store, and retrieve records while pursuing compliance with regulations such as SEC Rule 17a-4(f), FINRA Rule 4511(c), and CFTC Regulation 1.31(c)-(d).
In this post, we explore how financial institutions can use a range of AWS services to build a secure, scalable, and cost-effective record retention solution to assist them in pursuing their regulatory objectives. Within the capital markets segment, BDs determine, based on regulatory guidance, the records to retain for regulatory purposes. These can include account statements, trade confirmations, broker communications, and other documents.
Generally speaking, records can take the form of structured, semi-structured, or unstructured data. This may include relational data, transactional records, voice, video, social media, documents, or other formats. You may wish to lower costs associated with storing records, retire end-of-life storage appliances, handle disparate record formats, and add capacity based on expanded business demands. Leveraging AWS to modernize record retention solutions can enable you to pay for what you consume, scale to meet demand, maintain flexibility, and adapt to evolving business and regulatory requirements.
Addressing regulatory considerations
AWS has a number of solutions that can be helpful for customers pursuing compliance with SEC regulations. Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance, and Amazon S3 Glacier is a secure, durable, and low-cost Amazon S3 cloud storage class for data archiving and long-term backup. Customers can use S3 Object Lock and Amazon S3 Glacier Vault Lock to assist them in pursuing their technical data storage requirements of the SEC rules outlined in 17a-4(f). Cohasset Associates, a consulting firm specializing in records management and information governance, has determined that S3 Object Lock and S3 Glacier Vault Lock, when configured as described in the Cohasset Associates Report, meet the relevant storage requirements set forth in SEC Rule 17a-4(f), FINRA Rule 4511(c), and CFTC Regulation 1.31(c)-(d). These services provide immutability features for BDs who must retain records in a non-erasable and non-rewritable (also known as write-once, read-many or WORM) format. This helps give customers assurance, for example, that they can use these services to store immutable record objects and metadata.
Please note that if a BD uses electronic storage media exclusively to store required books and records, then it must appoint a “designated third party” (D3P), as defined in 17a-4(f), who can access the books and records. BDs should seek their own professional advice on applicable regulatory requirements for appointing their D3P. While AWS services can assist customers with storage and retention solutions, AWS does not act as a D3P.
Solution overview
To help explain how financial institutions modernize record retention, we will start with the record retention lifecycle, as depicted in Figure 1. We define the record retention lifecycle as data ingestion, processing, storage, and retrieval. Modernizing record retention has benefits along each stage of this lifecycle.

Figure 1: Record Retention Lifecycle
- Ingest – The ingestion layer is responsible for data movement from business applications to the record retention solution. Simplifying ingestion with API-driven storage and configuration to integrate with existing, disparate systems supports customers’ agility in responding to their changing requirements.
- Process – Includes data quality checks and conversion to optimized query formats. You can automate data quality checks and processing to drive consistency in your retained data.
- Store – This phase includes storing the records in a properly configured, immutable format. You no longer have to over-provision storage to ensure that you have enough capacity to handle your peak record retention needs. Now, you simply store your data as needed and pay only for what you are using.
- Retrieve – This phase includes querying and retrieving stored records. Rather than sending records off-premises, you can retain them in AWS for faster and simpler retrieval.
Throughout the record retention lifecycle, financial services institutions must satisfy security and audit expectations from their internal auditors as well as regulators. This may include proving records were not accessed by unauthorized individuals or processes, and that records were not modified or deleted. Any movement of the data can be logged and be searchable to allow auditors to verify chain of custody, if required.
Architecture
AWS Services support each phase of the record retention lifecycle, as outlined in Figure 2. We explore each of these in the following section.
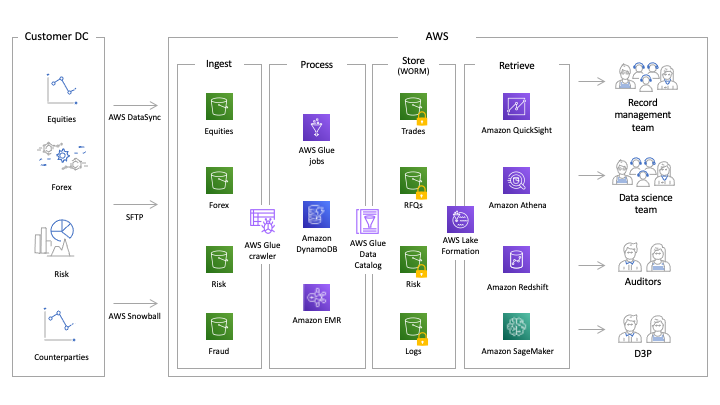
Figure 2: Architecture components
Ingestion
The ingestion layer is responsible for data movement from business applications to the record retention solution. Records targeted for regulatory retention are commonly ingested at the end of each business day, although the BD customer decides the appropriate cadence of ingestion. In addition, existing archives can also be migrated to this record retention solution, but special care has to be taken to ensure that retention periods for existing objects can be maintained in the new system. Common formats for exporting transactional data include both structured data formats (csv, parquet, avro) and semi-structured data formats (xml, json). Unstructured data such as voice recordings, scanned documents, and other formats may also be ingested for archiving.
AWS offers a number of services and capabilities to securely and efficiently move data to the cloud. Common services for online transfers include AWS DataSync, AWS Transfer Family, AWS Snowball as well as the ability to move data over private networks by making use of S3 Private Link and S3 VPC Endpoint over Direct Connect dedicated links or VPN.
AWS DataSync is an online data transfer service that simplifies, automates, and accelerates copying large amounts of data between on-premises storage systems and AWS Storage services, as well as between AWS Storage services. DataSync can copy data between file systems including: Network File System (NFS), Server Message Block (SMB) file servers, self-managed object storage, AWS Snowcone, Amazon Simple Storage Service (Amazon S3) buckets, Amazon Elastic File System (Amazon EFS), and Amazon FSx for Windows File Server.
The AWS Transfer Family provides fully managed support for file transfers directly into and out of Amazon S3 or Amazon EFS, with support for Secure File Transfer Protocol (SFTP), File Transfer Protocol over SSL (FTPS), and File Transfer Protocol (FTP).
AWS Snowball is a service that provides secure, rugged devices, so you can bring AWS computing and storage capabilities to your data center, and transfer data into and out of AWS. These rugged devices are commonly referred to as AWS Snowball or AWS Snowball Edge devices. The AWS Snowball service operates with Snowball Edge devices, which include on-board computing capabilities as well as storage.
Processing
Once the records are uploaded from a line of business application to S3, customers often perform a number of data quality checks to ensure that all the required data and attributes have been provided as part of the application archive generation process. These checks can include schema verification, duplicate data detection, data integrity and other content checks. Then users proceed with remediation activities. After incoming data is validated and any issues are corrected, further processing of the data can include conversion to optimized query formats like parquet and Hive style partitioning based on time/date prior to being stored in the write-once-read-many (WORM) archive.
To help with data checks and optimizations, customers can consider leveraging AWS Glue. Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue consists of:
- A Data Catalog which is a central metadata repository
- An ETL engine that can automatically generate Scala or Python code
- A flexible scheduler that handles dependency resolution, job monitoring, and retries
- AWS Glue DataBrew for cleaning and normalizing data with a visual interface
- AWS Glue Elastic Views, for combining and replicating data across multiple data stores
Together, these automate much of the undifferentiated heavy lifting involved with discovering, categorizing, cleaning, enriching, and moving data, so you can spend more time analyzing your data.
In addition to the metadata related to the content and structure of archive records stored in Glue, a regulatory archive may also contain a custom metadata store related to retention/disposition of records, such as legal hold or bespoke retention for unique records.
Storage
Amazon S3 forms the storage layer for both the raw data as well as the processed data in the record retention system. BDs may need to retain records in the record retention system for long periods of around 7-10 years, and need the system to be highly durable and scalable. Amazon S3 is designed for 99.999999999% (11 9’s) of durability and the total volume of data and number of objects that can be stored in Amazon S3 is unlimited. Amazon S3 is a simple key-based object store whose scalability and low cost make it ideal for storing large datasets.
Individual Amazon S3 objects can range in size from a minimum of 0 bytes to a maximum of 5 terabytes. The largest object that can be uploaded in a single PUT (operation used to send data to a server to create/update a resource) is 5 gigabytes. This allows you to store virtually any kind of data in any format in Amazon S3 including Word, Excel, PDF, CSV, Parquet, audio (call recordings, voicemail) and video files, to just name a few.
Amazon S3 offers a range of storage classes designed for different use cases. S3 Standard-IA is recommended for the record retention use case, as the data is accessed less frequently. S3 Standard-IA provides rapid access when needed and offers high durability, high throughput, and low latency of S3 Standard, with a low per GB storage price and per GB retrieval fee.
To further reduce costs for the record retention system, Amazon S3 Glacier can be used to archive records older than a certain time period (e.g., 3 years). Amazon S3 Glacier and S3 Glacier Deep Archive are secure, durable, and low-cost Amazon S3 cloud storage classes for data archiving and long-term backup. Customers can store data for as little as $1 per terabyte per month, a significant savings compared to on-premises solutions.
In the record retention solution, the raw and processed data can be initially saved in S3 Standard-IA. The data can then have lifecycle policies to automatically migrate objects to S3 Glacier and S3 Glacier Deep Archive using the S3 lifecycle management. This helps in lowering the overall cost of storage.
Customers may have different requirements on retention and retrieval policies based on a record’s legal, administrative, or historical value. Amazon S3 Object Lock allows objects to be stored using a WORM model. It can be used to prevent an object from being deleted or overwritten for a fixed amount of time known as the retention period. Amazon S3 Object Lock can help you meet regulatory requirements of records retention systems that require WORM storage, and adds another layer of protection against object changes and deletion.
Amazon S3 Object Lock blocks deletion of an object for the duration of a specified retention period. Coupled with S3 Versioning, which protects objects from being overwritten, you’re able to ensure that objects remain immutable for as long as WORM protection is applied. You can apply WORM protection by either assigning a Retain Until Date or a Legal Hold.
- A retention period specifies a fixed period of time during which an object remains locked. During this period, your object is WORM-protected and can’t be overwritten or deleted. The records retention system can assign retention rules based on the contents of the records.
- A legal hold provides the same protection as a retention period, but it has no expiration date. Instead, a legal hold remains in place until you explicitly remove the legal hold. Legal holds are independent from retention periods. When a customer places a record on legal hold, the hold overrides all existing retention policies.
To get a listing of the S3 objects and their corresponding metadata within the record retention system, the Amazon S3 inventory tool can be used. The tool provides CSV, ORC, or Parquet output files on a daily or weekly basis. It can be used to get a listing of objects with details on the object lock, retain until date, and legal hold status.
At the end of the record’s lifecycle, records that meet the disposition rules and those that are not retained for legal hold may be deleted from the repository by the customer. Deletion can also be achieved by setting S3 Lifecycle configurations on the object. These objects are then automatically disposed from the record repository based on their age. S3 Lifecycle configurations do not impact an object that has an active S3 Object Lock. For additional information on securing data with S3 Object Lock, please see Protecting Data with Amazon S3 Object Lock.
Retrieval
You can implement different retrieval processes in the record retention system based on the record type (structured/unstructured) and storage tier in which the record exists. The approach to retrieval can vary depending on whether you are retrieving structured or unstructured data.
Structured data
Amazon Athena is the recommended service for retrieving structured data in Amazon S3 (Standard, Standard-IA and Intelligent-Tiering). Amazon Athena is a serverless interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL and it uses Presto with full standard SQL support. Users can log into the Athena Management Console, define the schema, and start querying the data in S3. Alternatively users can leverage the schema that is available in AWS Glue Data Catalog.
BDs may have to save millions of structured data records (like transactional records) per day and need a way to query these records to respond to legal inquires. When saving these transactional records in the record retention system, hundreds or thousands of these transactional records can be grouped and saved in a single file. Grouping the records will lower the number of put requests needed for the record retention system and may also lower overall retention costs. The file formats can be CSV, TSV, JSON, or Text files and also open-source columnar formats such as Apache ORC and Apache Parquet. Amazon Athena supports these file formats.
The Apache Parquet format is specifically recommended in this scenario as it can lower the file size by 87%. The queries can also be up to 34 times faster and the overall cost of running the query in Athena can be lowered by 99.7% by using Apache Parquet versus regular text file. Athena also supports compressed data in Snappy, Zlib, LZO, and GZIP formats. By compressing, partitioning, and using columnar formats, you can improve performance and reduce your costs. There is no need to save a separate index for these transactional records as they are ready to query with Athena. It can be very expensive if a designated index has to be maintained for the transactional records, as millions of records per day can grow very quickly to hundreds of billions of records in a year.
For querying data within S3 Glacier and S3 Glacier Deep Archive you can retrieve the data from S3 Glacier to S3 and then query the data using Athena. You can choose from three options to restore the data: expedited retrieval (1-5 mins), standard retrieval (3-5 hours), and bulk retrieval (5-12 hours). Retrieval from S3 Glacier Deep Archive can be achieved via standard (12 hours) or bulk (within 48 hours) options.
Unstructured data
Financial institutions may also save data in unstructured formats, including PDF, Word, Excel, images, text files, audio and video files. The metadata index along with the path to the Amazon S3 location for the file can be maintained in an Amazon DynamoDB. The records can be searched by querying the metadata in the DynamoDB table and the associated files can be downloaded using the S3 path location.
Text-based unstructured data like PDF, Word, EXCEL and text files can further be indexed by Amazon OpenSearch Service (September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service) along with their metadata, and this will enable searching the raw text along with the metadata. Amazon OpenSearch Service makes it easy for you to perform interactive log analytics, real-time application monitoring, website search, and more.
Security
Security is key for a record retention system, which needs to have the right access controls, data protection and auditing capabilities. In the following section, we explore how these can be enforced using different AWS Services.
Access controls
As an authorized user, you will be able to access, retrieve, and read the record in the record retention system, but not be able to make changes to it or delete it when S3 Object Lock is set to “Compliance” mode. Changes to the metadata can be authorized to optimize the implementation design.
Amazon S3 is secure by default. Upon creation, only the resource owners have access to Amazon S3 resources they create. Different access control measures can be applied to structured, semi-structured and unstructured data.
Structured and semi-structured data
AWS Lake Formation is an integrated data lake service that makes it easy for you to ingest, clean, catalog, transform, and secure your data and make it available for analysis and machine learning.
For structured and semi-structured data in Amazon S3, you can use Lake Formation to centrally define security, governance, and auditing policies in one place, versus doing these tasks per service, and then enforce those policies for your users across their analytics applications. Your policies are consistently implemented, eliminating the need to manually configure them across security services like AWS Identity and Access Management and AWS Key Management Service, storage services like S3, and analytics and machine learning services like Amazon Redshift, Amazon Athena, and Amazon EMR for Apache Spark. Lake Formation is designed to reduce the effort in configuring policies across services and provide consistent enforcement and compliance.
Unstructured data
For unstructured data, you can grant access to users by using one or a combination of the following access management features: AWS Identity and Access Management (IAM) to create users and manage their respective access; Access Control Lists (ACLs) to make individual objects accessible to authorized users; bucket policies to configure permissions for all objects within a single S3 bucket; S3 Access Points to simplify managing data access to shared data sets by creating access points with names and permissions specific to each application or sets of applications; and, Query String Authentication to grant time-limited access to others with temporary URLs.
Data Protection
Security in transit
You can securely upload/download your data to Amazon S3 via TLS endpoints using the HTTPS protocol. With AWS PrivateLink for Amazon S3, you can provision interface virtual private cloud (VPC) endpoints in your VPC instead of connecting to S3 over the internet. Requests that are made to interface endpoints for Amazon S3 are automatically routed to Amazon S3 on the Amazon network. When accessing Amazon S3 from on-premises, it is recommended that you access S3 via interface endpoints in your VPC through AWS Direct Connect or AWS Virtual Private Network (AWS VPN).
Security at rest
Amazon S3 objects be encrypted at rest with server-side encryption with customer created Customer Managed Keys (CMKs) stored in AWS Key Management Service (SSE-KMS). There are separate permissions for the use of a CMK that provides added protection against unauthorized access to your objects in Amazon S3. SSE-KMS also provides you with an audit trail that shows when your CMK was used and by whom. You can configure your Amazon S3 buckets to automatically encrypt objects before storing them if the incoming storage requests do not have any encryption information. Alternatively, you can use your own encryption libraries or AWS Encryption SDK to encrypt data before storing it in Amazon S3.
You can use Amazon Macie to protect against security threats by continuously monitoring your data. Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in AWS.
Auditing
An audit trail is the complete history or log of any activity being performed on a record. It demonstrates the chain of custody for a record and its management from declaration to disposition. Auditors or regulators may expect this trail of events to be retained in an immutable format, to evidence that data has not been modified.
AWS CloudTrail is a service you can utilize to gain visibility into user activity by recording actions taken on your account. You can configure CloudTrail to record important information about each action, including who made the request, the services used, the actions performed, parameters for the actions, and the response elements returned by the AWS service. This information helps you to track changes made to your AWS resources and to troubleshoot operational issues. CloudTrail can make it easier to ensure compliance with internal policies and regulatory standards.
Amazon S3 server access logs and object-level logging provide detailed records for the requests that are made to an S3 bucket. You can use AWS CloudTrail logs together with server access logs for Amazon S3. CloudTrail logs provide you with detailed API tracking for Amazon S3 bucket-level and object-level operations. Server access logs for Amazon S3 provide you visibility into object-level operations on your data in Amazon S3. You can list the requests made against your S3 resources for complete visibility into who is accessing what data.
Conclusion
By modernizing record retention solutions, you are able to pay for what you consume, maintain flexibility, and adapt and easily grow in response to evolving business and regulatory requirements. Interested in modernizing your record retention systems on AWS? Get in touch!