Artificial Intelligence

Author: Yahav Biran
Yahav Biran is a Principal Architect at AWS, specializing in AI workloads at scale. Yahav actively contributes to open-source projects and regularly publishes in AWS blogs and academic journals. He holds a Ph.D. in Systems Engineering from Colorado State University.

Accelerating decode-heavy LLM inference with speculative decoding on AWS Trainium and vLLM
In this post, you will learn how speculative decoding works and why it helps reduce cost per generated token on AWS Trainium2.
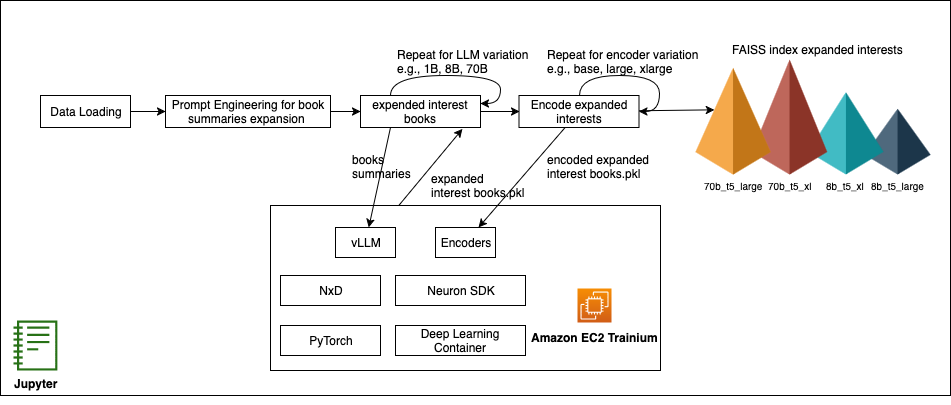
Boost cold-start recommendations with vLLM on AWS Trainium
In this post, we demonstrate how to use vLLM for scalable inference and use AWS Deep Learning Containers (DLC) to streamline model packaging and deployment. We’ll generate interest expansions through structured prompts, encode them into embeddings, retrieve candidates with FAISS, apply validation to keep results grounded, and frame the cold-start challenge as a scientific experiment—benchmarking LLM and encoder pairings, iterating rapidly on recommendation metrics, and showing clear ROI for each configuration