AWS for M&E Blog
Unlocking next generation audio production with MPEG-H on AWS
Most people today experience audio in fixed formats, where dialogue levels, commentary, and accessibility features are set in advance. But what if you could take full control over how you hear a show or sports game? Next Generation Audio (NGA) technologies like MPEG-H Audio make this possible, allowing viewers to adjust dialogue clarity, choose alternate commentary, or enable audio descriptions, seamlessly and interactively within a single stream.
In this post, we examine how you can implement NGA workflows in the cloud using MPEG-H Audio to deliver immersive, interactive audio at scale.
The standard MPEG-H production workflow using on-premises servers is widely used today. However, because more broadcasters are moving parts of their production workflows to the cloud, we need to rethink and adapt the current approach where source video and audio—including metadata—must be transferred and processed differently (for example in compressed formats instead of baseband or ST 2110).
This effort was developed in collaboration with AWS Partners and technology leaders to build and enable a complete MPEG-H production workflow in the cloud resulting in the final delivery of Adaptive Bit Rate (ABR) content with NGA to the consumer.
- Jünger Audio provides flexAI for real-time audio processing, metadata authoring, and rendering.
- MainConcept deploys their Live Encoder software for both contribution and distribution encoding.
- Techex contributes darwin for stream processing and multiplexing.
- Fraunhofer IIS supplies the MPEG-H metadata creation, encoding, and decoding libraries that power the entire workflow.
What is NGA?
For decades, audio in broadcast and streaming has been delivered as fixed mixes—left and right in stereo, or predefined speaker layouts in surround sound. While this approach faithfully reproduced creative intent in traditional systems, it limited how audiences could interact with content.
NGA transforms this paradigm. Broadcasters and streaming providers can differentiate their hybrid and cloud-based productions through object-based audio capabilities, while next-generation TV standards—ATSC 3.0 in the US and DTV+ in Brazil—mandate NGA codecs alongside efficient video compression (HEVC, VVC) to deliver superior quality at lower bandwidths, with European DVB and Japanese ARIB exploring similar paths. For large live sports events, broadcasters can launch cloud-based NGA production workflows on-demand and shut them down afterward, avoiding costly on-premises hardware investments.
Through its extensive metadata framework, NGA enables each consumer device to generate reproduction signals optimized for the specific characteristics of the playback device and its listening environment. A multi-speaker audio-video (AV) receiver can render audio for 12 or more loudspeakers, while the same NGA bitstream can be rendered on a mobile device for binaural headphone playback—each with individually optimized dynamic range and spatial presentation.
Object-based audio and metadata as enablers for NGA
Object-based audio is the fundamental paradigm underlying NGA systems. Instead of delivering a fixed stereo or surround mix, object-based audio preserves individual sound elements—such as dialogue, commentary, music, and sound effects—as separate audio objects. Each object is accompanied by metadata that describes:
- What the audio element represents (for example, dialogue, ambience, music)
- Where it should be positioned within a three-dimensional sound field
- When it’s active over time
- How it should be rendered or presented on different playback systems
- What type and degree of user interactivity is permitted
- The loudness characteristics of each audio object
This separation enables both personalization—such as selecting preferred languages or adjusting dialogue levels—and immersive audio, allowing sounds to be positioned dynamically around the listener in three-dimensional space.
Understanding MPEG-H Audio
MPEG-H Audio is an international audio standard developed by ISO/IEC MPEG, with key technologies contributed by Fraunhofer IIS. It’s specifically designed to enable NGA services for broadcast and streaming applications.
Key capabilities of MPEG-H Audio include:
- Multi-format audio support: Supports channel-based audio (stereo and traditional surround), object-based audio, and Higher-Order Ambisonics (HOA) for advanced spatial audio reproduction—including any combination of these formats within a single stream
- Interactive audio capabilities: Enables user control over audio elements such as language selection, dialogue enhancement, alternative commentary tracks, and personalized mixes within boundaries defined by the content creator
- Immersive sound reproduction: Supports three-dimensional audio formats with height channels, including common immersive configurations such as 5.1+4H and 7.1+4H
- Adaptive rendering: Automatically optimizes audio playback for devices ranging from high-end home theater systems to soundbars, TVs, and mobile devices using binaural rendering
- Accessibility features: Natively supports dialogue enhancement, the addition of audio description, and other assisted listening features
Partner collaboration: Building the cloud NGA workflow
This cloud-based NGA production workflow brings together specialized expertise from multiple AWS Partners and technology organizations, each contributing critical capabilities:
- Jünger Audio brings deep expertise in audio processing with their flexAI platform, which performs the complex task of real-time metadata authoring and rendering. flexAI enables broadcasters to create and manage NGA audio and metadata streams in live production environments, supporting both S-ADM and MPEG-H Control Track workflows.
- MainConcept provides Live Encoder, a professional-grade encoding solution that manages broadcast-grade contribution (bringing SDI feeds into the cloud) and distribution encoding (generating AVC, HEVC, or VVC content in HLS, CMAF, and DASH outputs).
- Techex contributes darwin, a sophisticated stream processing platform that demultiplexes incoming feeds, routes audio to processing systems, and remultiplexes the processed streams while maintaining frame-accurate time alignment—critical for professional broadcast applications.
- Fraunhofer IIS, the research organization behind the MPEG-H Audio technology, provides the encoding, decoding, and player libraries that enable the entire NGA experience from production through playback.
Together, these partners enable a complete cloud-based NGA production workflow that maintains broadcast quality while leveraging cloud scalability and flexibility.
The role of metadata in NGA production
Object-based audio is the fundamental paradigm underlying NGA systems. Instead of delivering a fixed stereo or surround mix, object-based audio preserves individual sound elements—such as dialogue, commentary, music, and sound effects—as separate audio objects. Each object is accompanied by metadata that describes what the audio element represents, where it should be positioned within a three-dimensional sound field, when it’s active over time, how it should be rendered on different playback systems, what type and degree of user interactivity is permitted, and the loudness characteristics of each audio object.
In NGA productions, all user interactivity features are defined by producers through metadata. The process of creating and managing this metadata is referred to as authoring. During authoring, the content provider specifies which audio elements are available to the user, how they can be interacted with, and how they’re rendered during playback.
MPEG-H production formats
An MPEG-H Master contains all uncompressed audio elements and the complete set of production and authoring metadata that define an MPEG-H Audio scene. For live production workflows relying on SDI-based infrastructure, MPEG-H uses a Control Track method to deliver metadata. The Control Track is a PCM audio signal that carries all MPEG-H metadata and is fully aligned with the corresponding audio and video data. Because it’s carried and edited like any other audio signal, it’s robust against sample rate conversions or level changes, making it ideal for live production environments.
Bringing NGA production to AWS
As audio experiences evolve toward greater immersion and personalization, production workflows must also evolve. Traditional media production has relied on on-premises infrastructure—outside broadcasting (OB) vans, studios, and dedicated hardware—to manage uncompressed media, real-time metadata authoring, and distribution. As live production increasingly moves to the cloud, NGA workflows benefit from bringing tools to content rather than content to tools. The cloud’s scalability enables multiple audio studios globally to simultaneously deliver immersive mixes into a centralized publishing chain. This distributed model allows broadcasters to dynamically allocate resources during peak events and scale down afterward, paying only for what they use while maintaining broadcast-grade quality.
Solution architecture
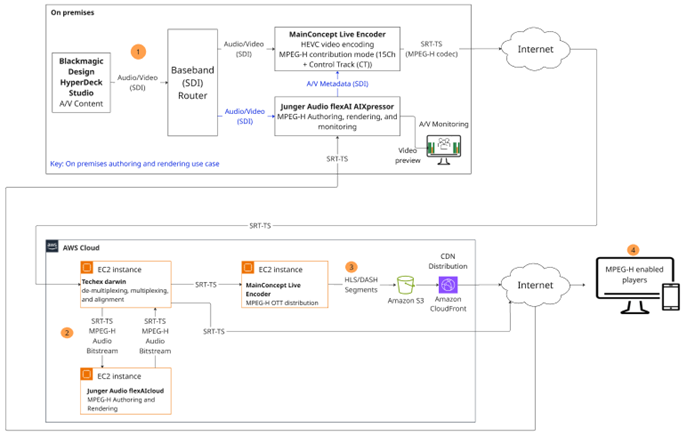
Figure 1: Solution architecture and signal workflow
1. Audio capture: Individual audio sources—such as commentary, ambient sounds, and effects—are captured separately as discrete PCM audio signals. This separation enables interactivity and immersive rendering on the consumer side (devices such as TVs and handhelds). The MainConcept Live Encoder (in contribution mode) receives a video stream with 16 channels of embedded PCM audio over baseband (SDI). Having 16 channels enables the use of more objects to enrich the user experience downstream. Live Encoder—which has integrated the Fraunhofer’s MPEG-H encoding technology —outputs the stream as MPEG-H contribution bitstream plus video as Transport Stream (TS) over SRT. The SRT feed is then contributed to the AWS Cloud for processing.
The Jünger Audio AIXpressor is used for monitoring of the return feed from the cloud.
Optionally, authoring can take place on premises, providing additional flexibility for customers who are using local AIXpressor units. In this case, it receives the AV feed, de-embeds audio, and then authors and renders the feed for monitoring. It then sends the authored audio and metadata to the contribution encoder.
2. Metadata creation: Jünger Audio flexAI processes the audio elements and creates the metadata for defining:
- Channel-based beds: For example, 5.1+4H and 7.1+4H immersive mix
- Audio objects: For example, commentators in multiple languages
- Presets and presentations: Combinations of beds and objects tailored for different user selections
Techex darwin (running on AWS) receives the SRT-TS (or NDI streams based on system requirements), which demultiplexes the incoming feed to its elementary audio and video streams. The audio bitstream is forwarded using SRT to the Jünger Audio flexAI cloud instance. In flexAI, the MPEG-H Audio bitstream is decoded to PCM audio to reconstruct the metadata and modulate it into a PCM audio track (the Control Track). Depending on the workflow, the incoming metadata can be edited or created from scratch. After the authoring and rendering is completed in flexAI, the audio and metadata are sent back to darwin as MPEG-H Audio bitstream over SRT. Darwin then multiplexes the processed audio, including the metadata, with the video stream while maintaining time alignment.
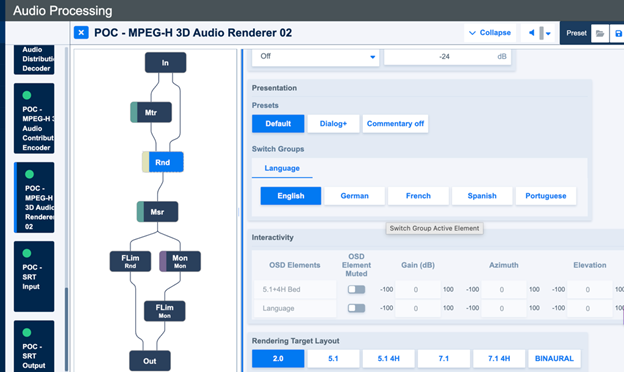
Figure 2: Jünger Audio’s flexAI MPEG-H Rendering module
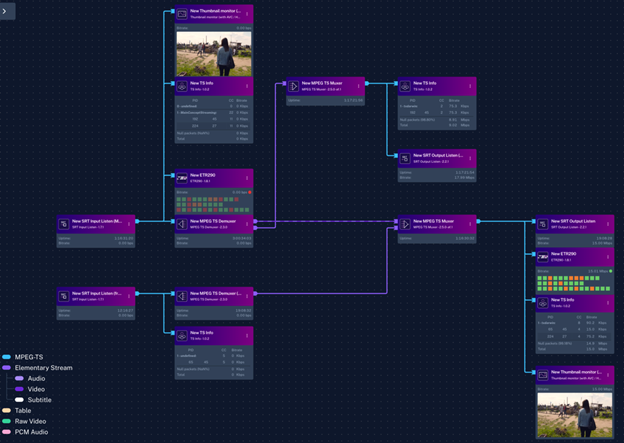
Figure 3: Techex darwin screenshot for SRT routing, (de-)multiplexing and frame alignment
3. Distribution:
The output from darwin is then sent using SRT-TS to the MainConcept Live Encoder operating in distribution mode. The Live Encoder receives the SRT-TS and encodes it into complete HLS, DASH, or CMAF streams including MPEG-H audio and AVC, HEVC or VVC video segments, and corresponding manifest that are then stored in Amazon Simple Storage Service (Amazon S3) completing the MPEG-H production workflow in a cloud environment. Amazon CloudFront is the CDN for OTT delivery with Amazon S3 as its origin.
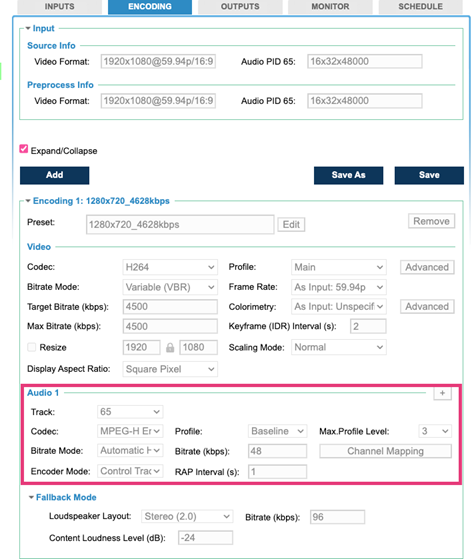
Figure 4: User Interface of MainConcept’s Live Encoder for AVC and MPEG-H Audio emission encoding
4. Rendering at the playback device:
- The decoder receives the MPEG-H Audio bitstream containing audio and matching metadata and decodes the bitstream into PCM Audio
- The renderer inside the decoder adapts the mix to the available playback setup (soundbar, headphones, or full surround system) using the metadata
- User interactivity is enabled, allowing selection of language, dialogue level, commentary tracks, and other personalized options using an on-screen display
The MPEG-H libraries for encoding, decoding, and players are provided by Fraunhofer IIS.
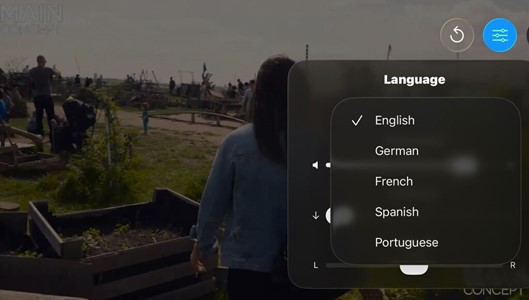
Fig. 5: MPEG-H Audio on-screen display on iOS mobile player for audio object selection and user personalization
Conclusion
In this post, we discussed the implementation of cloud-based NGA production workflows using MPEG-H Audio on AWS. By combining Jünger Audio’s audio processing expertise, MainConcept’s encoding capabilities, Techex’s stream processing platform, and Fraunhofer IIS’s MPEG-H technology, broadcasters can implement professional-grade NGA workflows in the cloud without compromising on quality or functionality.
The cloud-based approach provides flexibility and efficiency enabling the scale to millions of concurrent viewers.
Contact an AWS Representative to learn more about this workflow, or learn how we can help accelerate your business.