AWS Open Source Blog
How Onehouse Makes it Easy to Leverage Open Source Data Services on AWS
Apache Hudi is an open source technology that many organizations on AWS use to build a high performance low-latency data lakehouse. For anyone new to this space, a lakehouse is a popular new data architecture that brings the capabilities of a data warehouse to a data lake, offering dramatic cost reductions and flexibility of data tools. Hudi was the first lakehouse technology created in 2016. It provides an innovative incremental processing framework that enables developers to realize large cost savings when designing their data architecture. Since Hudi is natively preinstalled and supported on AWS analytics services like Amazon Simple Storage Service (Amazon S3), Amazon EMR, Amazon Athena, AWS Glue, and Amazon Redshift, it is ready to use out of the box on AWS.
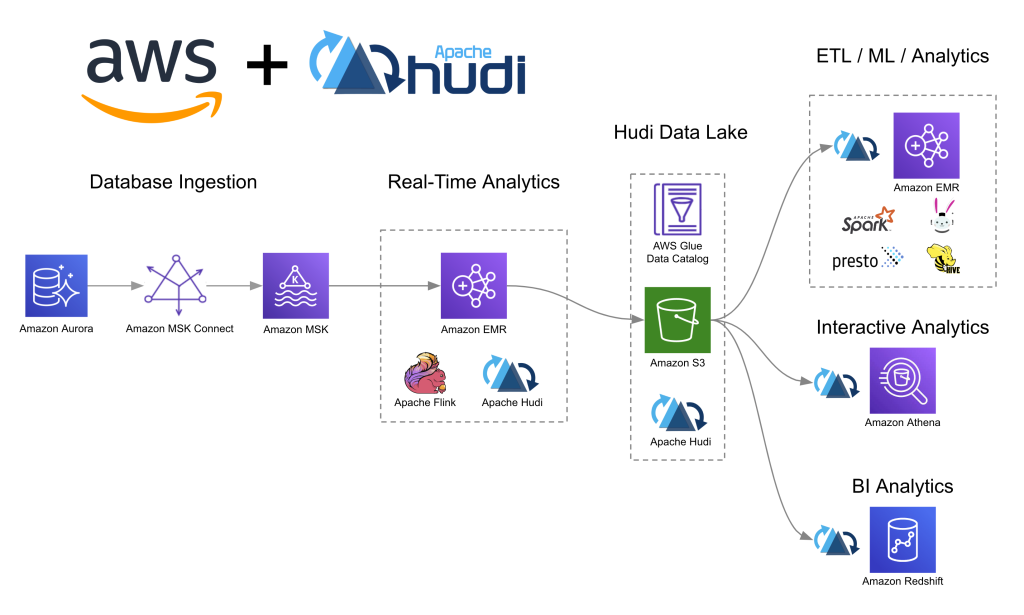
Whether an organization wants to build near-real-time event analytics like Amazon’s own global package delivery system or wants to implement streaming log ingestion like Zoom, there is a rich and fast growing community of developers and vendors that contribute to and collaborate on the open source Hudi project alongside AWS.
Introducing Onehouse Lakehouse on the AWS Marketplace
To help accelerate adoption of this emerging architectural pattern a new AWS Partner, Onehouse.ai, recently launched its managed lakehouse product on the AWS Marketplace. Onehouse, founded by the original creator of Hudi, Vinoth Chandar, automates the foundation of the data lakehouse and can save organizations the months of extensive engineering efforts which it can take to DIY build these enterprise grade data platforms.
One of the most overlooked parts in building a lakehouse is creating the foundation to ingest and manage data in storage. Onehouse delivers continuous data ingestion from RDBMS databases like Amazon Relational Database Service (Amazon RDS) backed PostgreSQL/MySQL, Event Streams like Amazon Managed Streaming for Apache Kafka (Amazon MSK), or even from cloud storage itself like Amazon S3. Onehouse eliminates tedious data chores by automating all the table services necessary for high performance analytics such as file-sizing, partitioning, cleaning, clustering, and more. Onehouse helps engineers quickly develop low-code incremental pipelines and the product will sync all data to a metastore catalog of choice like AWS Glue, for example.

Onehouse is a universal lakehouse that unlocks integration of multiple query engines to a common, well-managed cloud storage system. By decoupling query engines from standard services like ingestion, clustering, indexing, and GDPR deletions, these can now be performed once and leveraged across multiple engines. Data is optimized and analytics ready for any of the analytics services on AWS like Amazon EMR, Amazon Athena, and Amazon Redshift.
As momentum for the lakehouse architecture has grown over the last few years, three open source projects have emerged as leaders. Apache Hudi, Apache Iceberg, and Delta Lake each offer a powerful set of primitives that provide transaction and metadata layers in cloud storage, around open file formats like Apache Parquet. While Onehouse is born from Hudi roots, interoperability is also one of its core missions. To this end Onehouse recently launched Onetable, a new feature that translates and publishes the metadata layers of all three projects. With zero copying of data, the same table can be queried and accessed as if it was a native Hudi, Delta, or an Iceberg table. Onetable eliminates the burden of choice between the projects and enables data to take advantage of any proprietary accelerations that are built in to query engine layers. This includes Delta Lake and the Databricks Photon execution engine. Onehouse just released Onetable to open source and anyone from the community is invited to participate.
How to Get Started with Onehouse on AWS
With Onehouse now available in the AWS Marketplace, it has never been easier to build a lakehouse. In this overview we will use Onehouse to connect to Amazon RDS for PostgreSQL, stream data into Amazon S3, sync the tables to AWS Glue Data Catalog, and query the data with Amazon Athena.
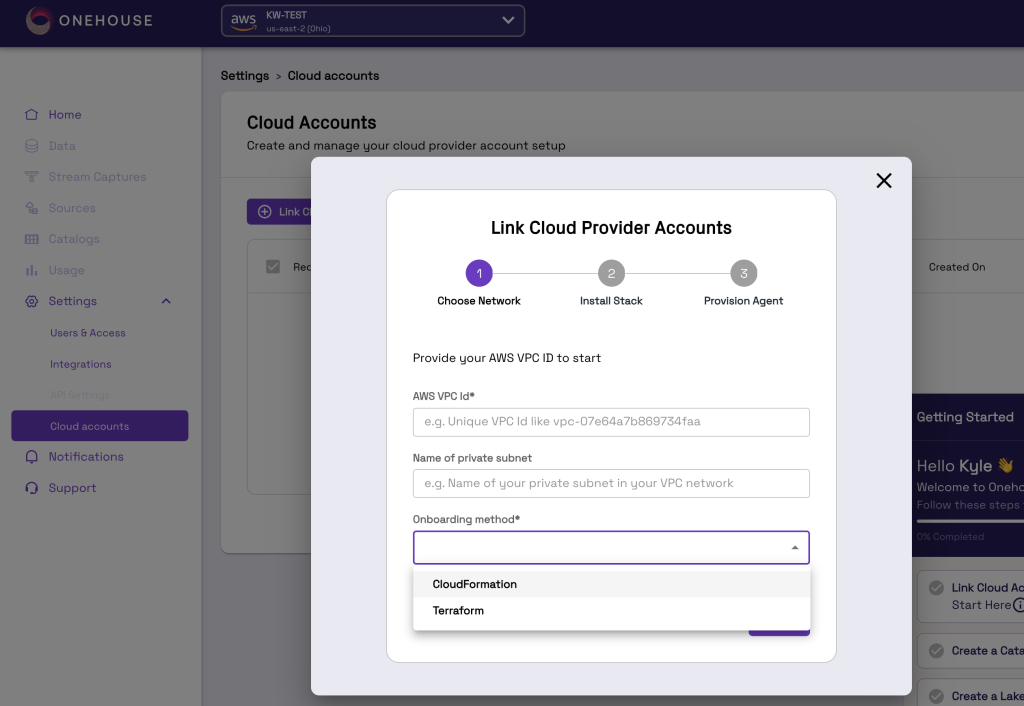
To start, first deploy the Onehouse services into an Amazon Virtual Private Cloud (Amazon VPC) leveraging AWS CloudFormation or a Terraform template as depicted in this screenshot. Copy and paste your Amazon VPC ID, select your onboarding method as CloudFormation and click Next.
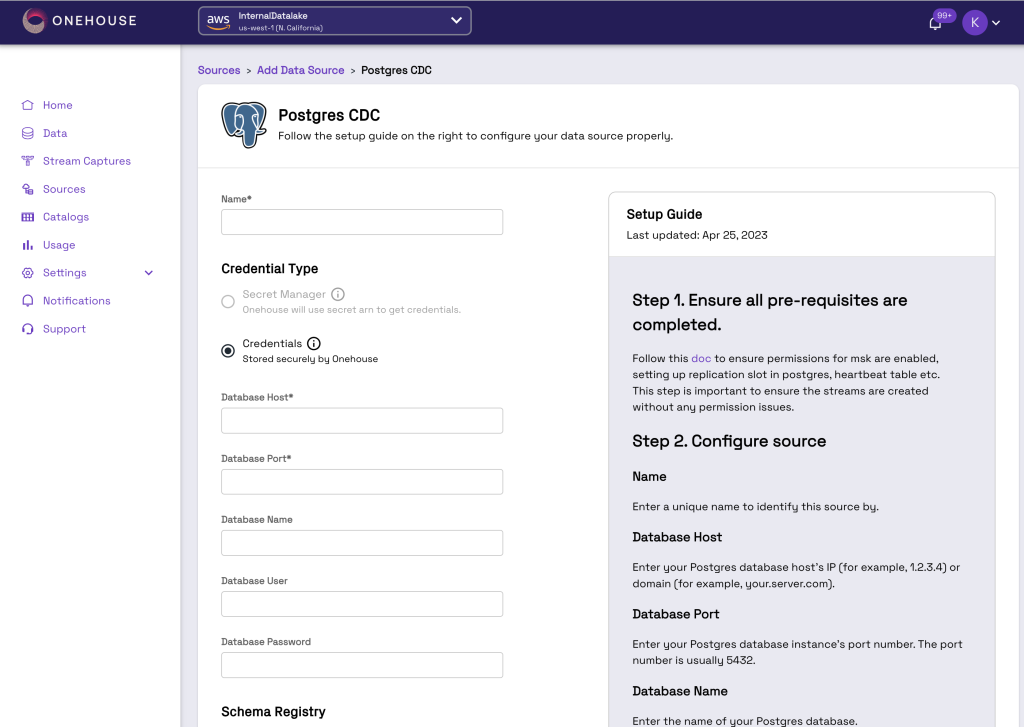
Once the deployment is complete you can establish a connection to the data sources. In the next screenshot, you can configure an Amazon RDS for PostgreSQL source by providing the database host and port name. Once filled in, click Create Source.
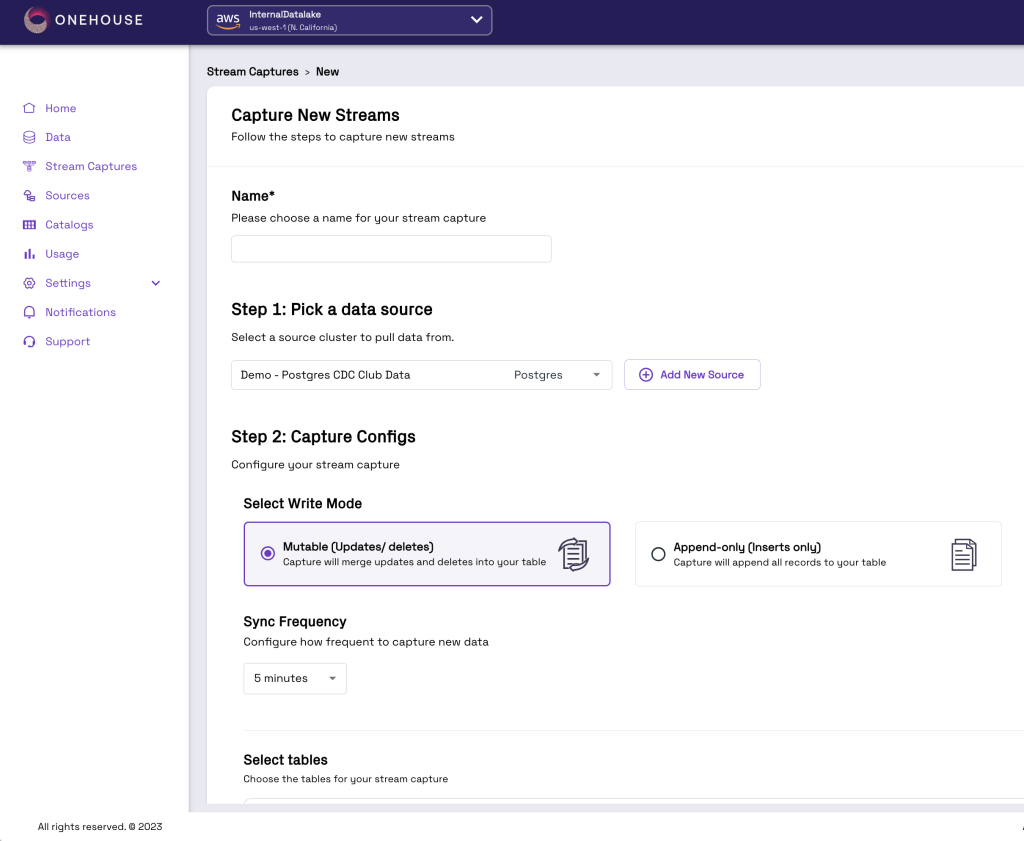
With sources configured, you can now define a stream capture pipeline that will continuously ingest data into analytics-ready lakehouse tables. With Onetable the data can be represented as Hudi, Delta, and/or Iceberg, and any or all of these tables and their metadata can be synced to any catalog.
In the next screenshot, you can choose a name for your pipeline, pick the source you previously configured, and then you can optionally provide a wide array of advanced configurations. Onehouse allows you to set data quality quarantine monitors, setup low-code transformations, and more.
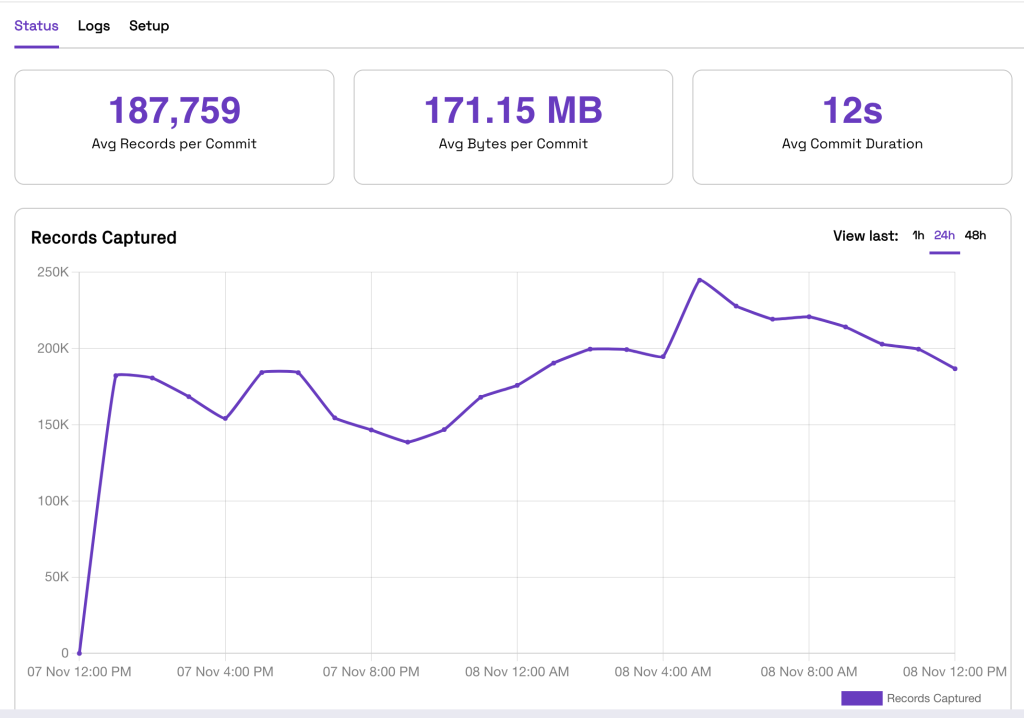
After creating a stream capture, the performance of the pipelines can now be monitored as they run. This screenshot visualizes the average records per commit, how many bytes are being written, and how long the pipeline takes to run per commit.
The data is now performance tuned and readily available for analytics in Amazon Athena. Take a look at the tables that were automatically registered in AWS Glue. The next screenshot shows a list of the tables, for this demo these are called orders_demo_ro, and orders_demo_rt:

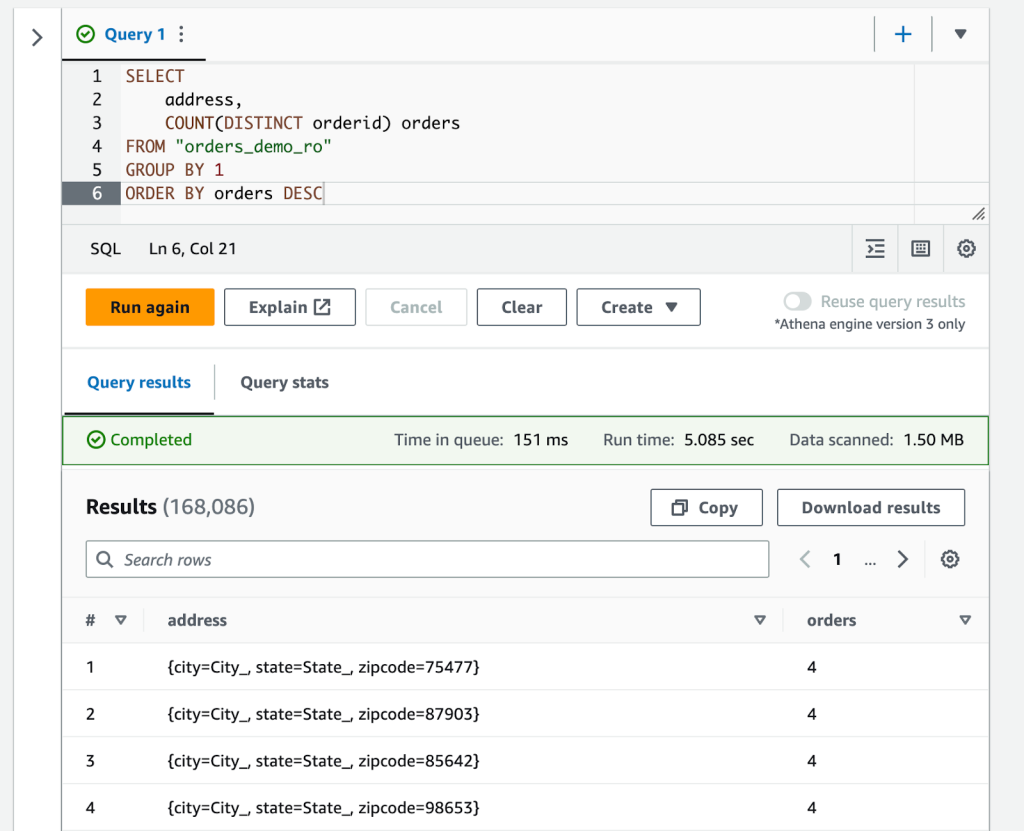
If you are ready to run your own queries, you can open up Amazon Athena in the AWS Console and the tables will be available to start writing SQL queries. In the next screenshot, we’ve provided a simple SELECT query that counts the distinct orders in the table that Onehouse created:
Beyond this, the data is also ready for deeper ETL in Amazon EMR, machine learning model training with Amazon SageMaker, or further business intelligence (BI) data modeling with Amazon Redshift and Amazon Quicksight. Because the data is written in open formats, it is future proof and interoperable with a wide array of open source frameworks supported by AWS.
Conclusion
When planning to build a data lakehouse, or expand a lakehouse to a wider variety of sources, Apache Hudi and Onehouse on AWS cloud should be a top consideration. With Onehouse the tedious chores of operating data lakes can be forgotten and a near-real-time lakehouse can be built in hours vs months. Onehouse has a team of world class talent and decades of experience building data lakes, data warehouses, and modern architectures like the Lakehouse. If you want to learn more or try it yourself for free, take a look at the listing on the AWS Marketplace or reach out directly to the team at gtm@onehouse.ai. If you want to connect with more open source data communities, Onehouse is proud to co-chair the inaugural Open Source Data Summit happening virtually on Nov. 15, 2023. Reserve your seat here: https://opensourcedatasummit.com/