AWS Big Data Blog
How Amazon Transportation Service enabled near-real-time event analytics at petabyte scale using AWS Glue with Apache Hudi
This post is co-written with Madhavan Sriram and Diego Menin from Amazon Transportation Services (ATS).
The transportation and logistics industry covers a wide range of services, such as multi-modal transportation, warehousing, fulfillment, freight forwarding, and delivery. At Amazon Transportation Service (ATS), the lifecycle of the shipment is digitally tracked and appended to tens of tracking updates on average. Those tracking updates are vital to kick off events through the shipment operational and billing lifecycle, including delay identification and route optimization. They are also the base for the customer and consumer tracking experience through the different touchpoints.
In this post, we discuss how ATS enabled near-real-time event analytics at petabyte scale using Apache Hudi tables created by AWS Glue Spark jobs.
ATS was looking for ways to securely and cost-efficiently manage and derive analytical insights over petabyte-sized datasets, with data coming in from different sources at different paces, and stored over different storage solutions. You can gain deeper and richer insights when you bring together all your relevant data of all structures and types, from all sources, to analyze.
One of the main challenges that our data engineering team at ATS faced was bringing together all the data arriving in real time, and building a holistic view for our customers and partners. The majority of the orders placed through Amazon, one of the world’s largest online retailers, are operationalized by ATS for the transportation and logistics. ATS provides the business accurate and timely package delivery. ATS operations generate data at petabyte scale, so having the data available at their fingertips provides innumerable opportunities to improve operations through data-driven decision-making.
Apache Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development. This framework more efficiently manages business requirements like data lifecycles and improves data quality. Hudi enables you to manage data at the record level in Amazon Simple Storage Service (Amazon S3) data lakes to simplify change data capture (CDC) and streaming data ingestion at petabyte scale, and helps handle data privacy use cases requiring record-level updates and deletes.
Solution overview
One of the biggest challenges ATS faced was handling data at petabyte scale with the need for constant inserts, updates, and deletes with minimal time delay, which reflects real business scenarios and package movement to downstream data consumers.
Their traditional data warehouses couldn’t scale to the size of the data nor the frequency of data ingestion. They needed to scale to hundreds of GBs of data across multiple data ingestion sources in order to derive near-real-time data for downstream consumers to use for data analytics that powered business-critical reports, dashboards, and visualizations. The data is also used for training machine learning models with overall service level agreements (SLAs) of 15 minutes for data ingestion and processing.
In this post, we show how we ingest data in real time in the order of hundreds of GBs per hour and run inserts, updates, and deletes on a petabyte-scale data lake using Apache Hudi tables loaded using AWS Glue Spark jobs and other AWS server-less services including AWS Lambda, Amazon Kinesis Data Firehose, and Amazon DynamoDB. AWS ProServe, working closely with ATS, built a data lake comprising of Apache Hudi tables on Amazon S3 created and populated using AWS Glue. A data pipeline was created that supports inserts, updates, and deletes at petabyte scale on the Apache Hudi tables using AWS Glue. To support real-time time ingestion, ATS also implemented a real-time data ingestion pipeline based on Kinesis Data Firehose, DynamoDB, and Amazon DynamoDB Streams.
To tackle the challenges we discussed, we decided to follow the “Divide et Impera” approach, and define two separate workstreams:
- Stream-based – We ingested data from four different data sources and 11 datasets, and performed some initial data transformation and joins steps, honoring a time window that may vary from 3 hours to 2 weeks across all workloads. The event rate might go up to thousands of events per second, and events might have duplicates, arrive late, or not be in the correct order. Our objective was to understand in real time the transit status of a given package or truck, capture the current status of ATS operations in real time, and extend the current stream-based solution to offload and supplement the current extract, transform, and load (ETL) solution, based on Amazon Redshift.
- Data lake – We wanted the ability to store petabytes of data and allow for merges between historical data (petabytes) with newly ingested data. The data retention policy extends to up to 5 years, which brings increased costs and reduces performance significantly. Our team requires access to near-real-time data (less than 15 minutes) from stream-based ingestion, with full GDPR compliance. Our objective was to merge stream-based ingested data files to derive a holistic view of the dataset at a certain point in time, with an SLA of under 15 minutes. Data lineage capabilities would also be nice to have.
Stream-based solution
The following diagram illustrates the architecture of our stream-based solution.
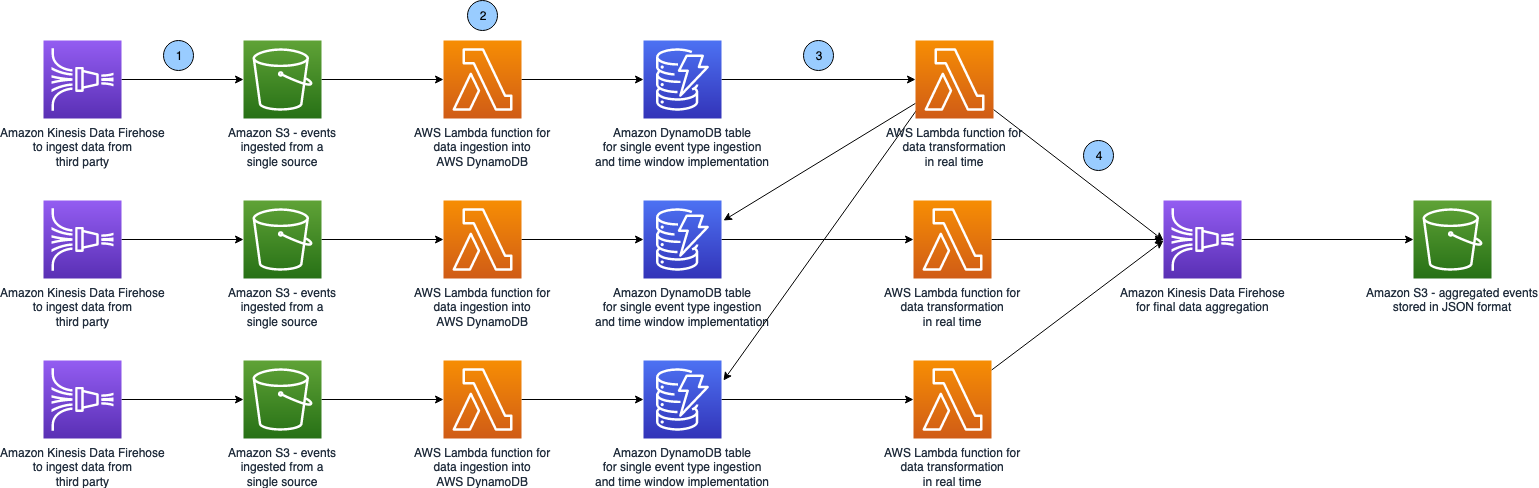
The flow of the solution is as follows:
- Data is ingested from various sources in separate Firehose data streams, collected for up to 15 minutes and stored in S3 buckets.
- Upon the arrival of every new file in Amazon S3, a Lambda function is triggered to insert data into a DynamoDB table associated with a specific data source or datasets.
- With DynamoDB Streams, we trigger a second Lambda function that aggregates data in real time across the different DynamoDB tables by performing real-time DynamoDB table lookups. The ETL window is enforced using DynamoDB item TTL, so data is automatically deleted from the table after the TTL period expires.
- After it’s transformed, data is collected in Amazon S3 passing through a Firehose delivery stream and is ready to be ingested into our data lake.
The solution allows us to do the following:
- Ingest data in parallel, in real time, and at the desired scale from all the data sources
- Scale on demand, and with minimal human operational overhead; this is achieved using an AWS Serverless technology stack
- Implement our desired time window on a per-item base, reducing costs and the total amount of data stored
- Implement ETL using Lambda functions in Python, thereby providing a tighter grasp over expressing the business logic
- Access data on Amazon S3 before it’s ingested into our data lake, and allow customers and partners to consume data in raw format if needed
The data present in Amazon S3 represents the starting point for a seamless data lake integration.
Data lake ingestion
Moving into our data lake, the following diagram illustrates our architecture for data lake ingestion.

The core implementation in this architecture is the AWS Glue Spark ingestion job for the Hudi table; it represents the entry point for the incremental data processing pipeline.
AWS Glue Spark job runs with a concurrency of 1 and contains the logic for upsert and delete sequentially applied on the Hudi table. The sequencing of delete after upsert in the AWS Glue Spark job ensures, deletes are applied after upsert and the data consistency is maintained even in case of job reruns.
To use Apache Hudi v0.7 on AWS Glue jobs using PySpark, we imported the following libraries in the AWS Glue jobs, extracted locally from the master node of Amazon EMR:
hudi-spark-bundle_2.11-0.7.0-amzn-1.jarspark-avro_2.11-2.4.7-amzn-1.jar
We recommend using Glue 3.0 with Hudi 0.9.0 connector rather than importing Hudi v0.7 jar files from EMR, for seamless integration and have more capabilities and features.
Before we insert data the Hudi table, we prepare it for push. To optimize for incremental merge, we take a fixed lookup window based on business use case considerations. We start by reading historical data in a given time window. See the following code:
In the preceding code, config is a dictionary that includes all the Apache Hudi configurations. The AWS Glue Data Catalog is automatically synched after Hudi table creation, as part of the Glue job, reflecting the Amazon S3 partition structure. We can now query the data using Amazon Athena or Amazon Redshift Spectrum.
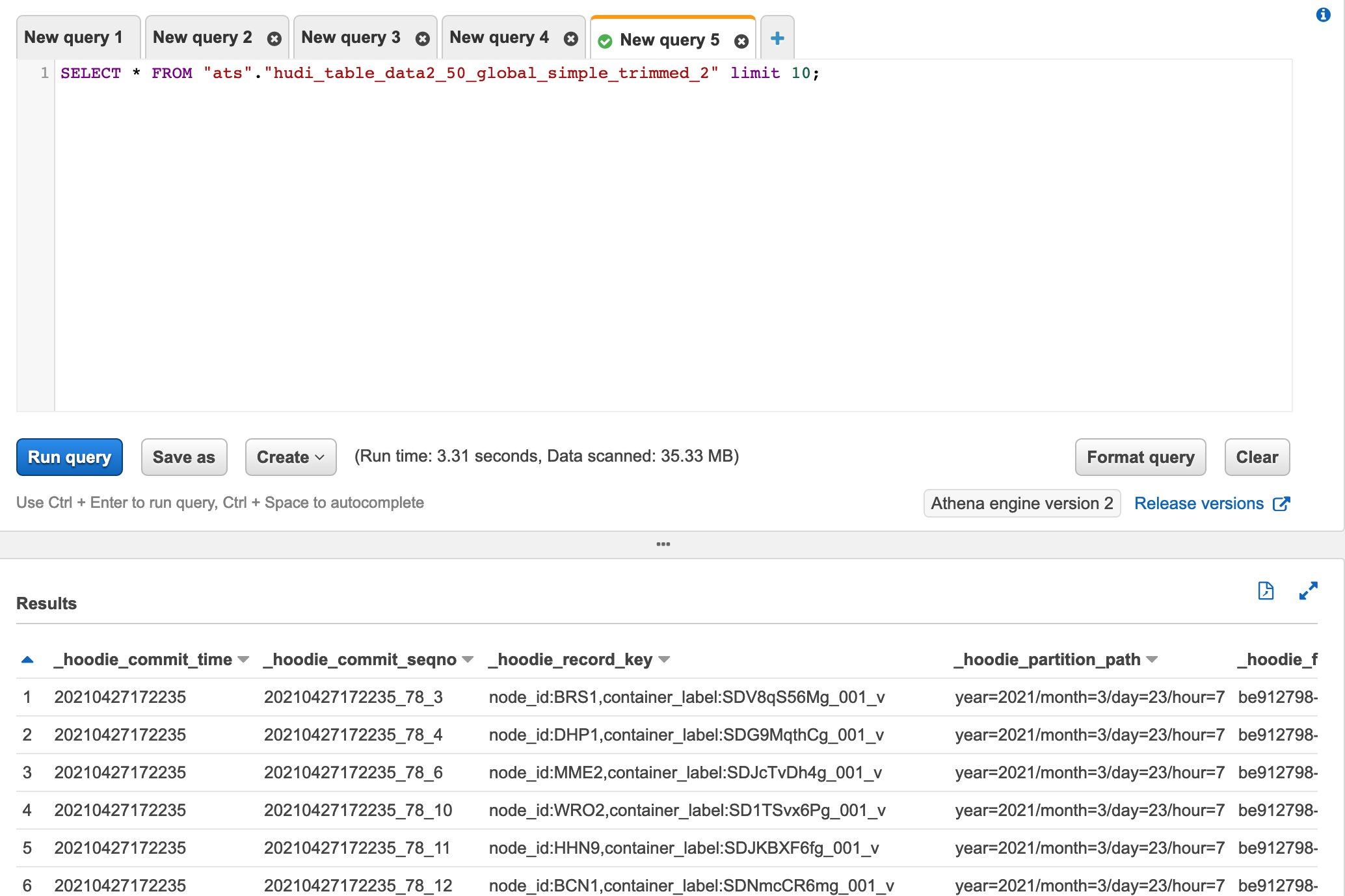
To comply with our strict internal ingestion SLA, we had to dedicate special attention to employing the right Hudi indexes and defining the right table type. For the latter, we analyzed the type of workload. Due to the analytic nature of the datasets and use case, we identified that the right configuration would be to use a COPY_ON_WRITE table, even if that was a compromise on the write performances but enhanced read performance.
For the former, we went through an experimentation phase. We started with a GLOBAL_BLOOM index, identifying an initial non-linear pattern for data writing performances.
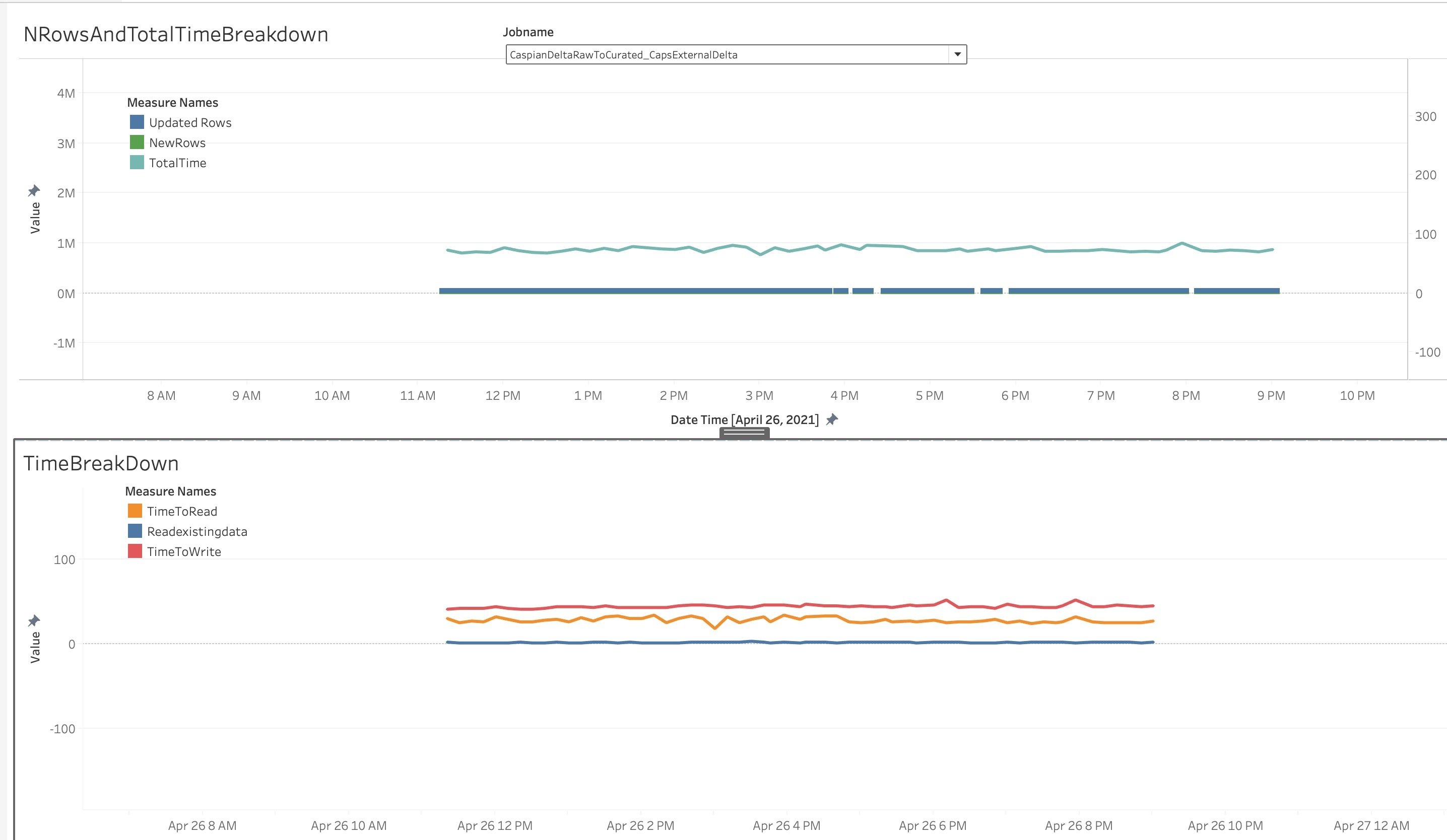
Given the randomness and the time window specified for the input data, we have encountered a significant number of false positives, leading to reading the entire dataset back for comparison. Moreover, GLOBAL_BLOOM keeps increasing linearly corresponding to the data size, whereas GLOBAL_SIMPLE doesn’t bring this overhead (with a fixed lookup window) as can be observed in the diagram.
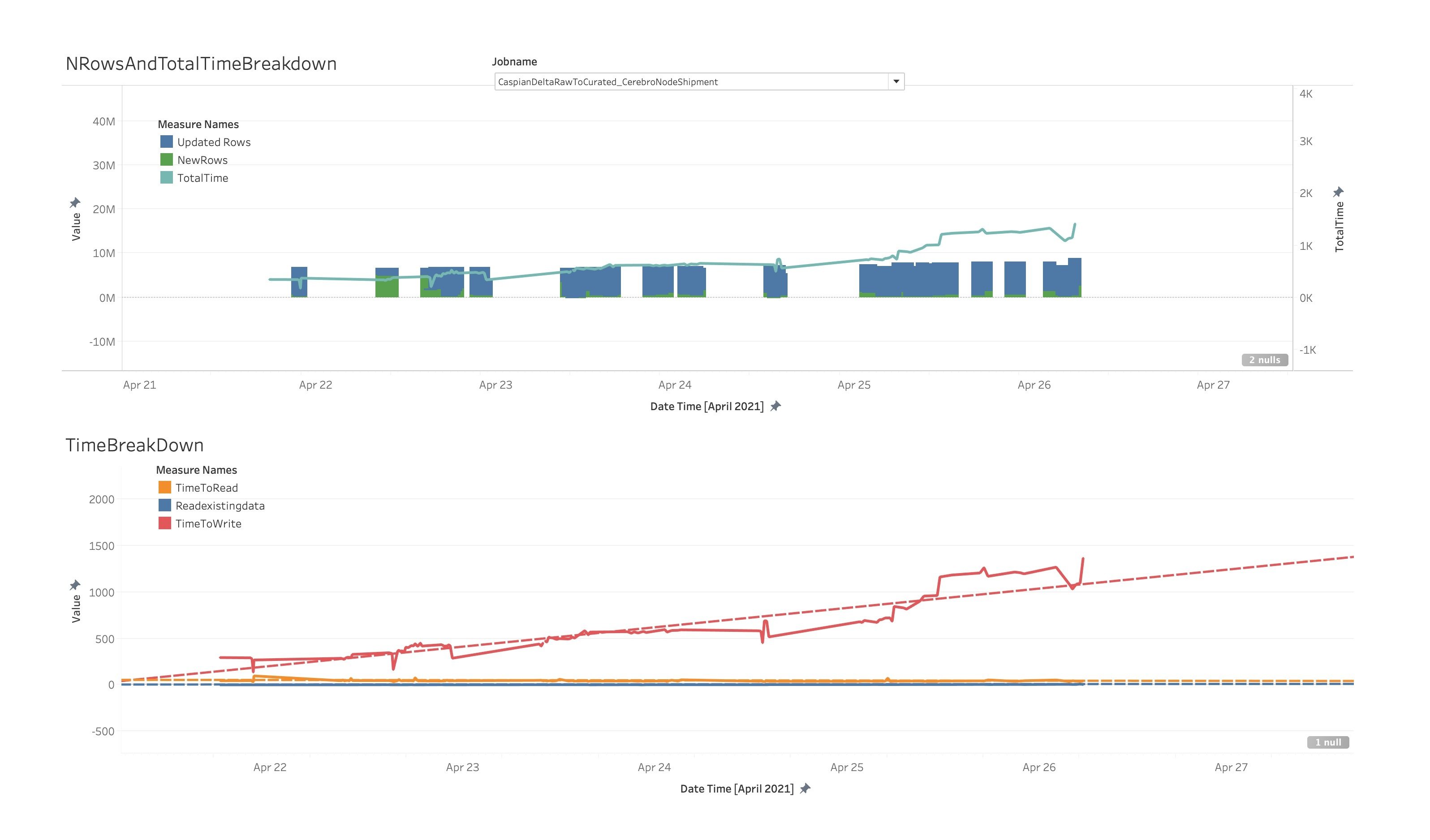
The graph represents the Total Time taken by Glue Hudi job(X-axis) over days (Y axis) as incoming data is merged with the historical data. leveraging GLOBAL_BLOOM. The graph in upper half, shows when same data was merged consecutively over days, non-linear time increase was observed. Lower half graph indicates Linear increase with a steep slope when new incoming data was merged with historical data.
GLOBAL_BLOOM wasn’t appropriate for our use case as the historical data spanned back to 5 years, and Glue job will not be able to meet the SLA demands. At this point, we investigated GLOBAL_SIMPLE indexes, reaching the expected performance patterns.
Our data lake solution allows us to do the following:
- Ingest data files in a petabyte-scale data lake, with a 15-minute ingestion SLA from the moment we receive the data
- Read the data at Peta Byte scale by leveraging Amazon S3 partitions (created by Glue jobs and mapped to Hudi partition logic) and faster lookups by using Hudi indexes
- Use Hudi data lineage capabilities
- Reduce costs for data storage, infrastructure maintenance, and development
- Manage data governance using AWS Lake Formation, which allows partners and customers to query the data using their own tools, while allowing ATS to retain control over our data
Conclusion
In this post, we highlighted how ATS built a real-time fully serverless data ingestion platform, scaling up to thousands of events per second and merging with petabyte- sized historical data stored in a data lake in near-real time.
We built a petabyte-scale data lake solution based on Apache Hudi and AWS Glue that allows us to share our data within 15 minutes from ingestion with our partners and consumers, while retaining complete control over our data and automatically offloading costs for data consumption. This provides linear performance as data grows over time.
About Amazon Transportation Service
Amazon Transportation Service (ATS) is the middle mile of the transportation network of Amazon, connecting the fulfillment centers at one end and the delivery stations and post offices at the other end. We enable packages that are ordered and packaged from fulfillment centers that traverse across the European continent to be delivered in the final delivery station that does the house-to-house delivery.
About the Authors
 Madhavan Sriram is a Manager, Data Science who comes with a wide experience across multiple enterprise organisations in the space of Big Data and Machine Learning technologies. He currently leads the Data Technology and Products team within Amazon Transportation Services (ATS) and builds data-intensive products for the transportation network within Amazon. In his free time, Madhavan enjoys photography and poetry.
Madhavan Sriram is a Manager, Data Science who comes with a wide experience across multiple enterprise organisations in the space of Big Data and Machine Learning technologies. He currently leads the Data Technology and Products team within Amazon Transportation Services (ATS) and builds data-intensive products for the transportation network within Amazon. In his free time, Madhavan enjoys photography and poetry.
 Diego Menin is a Senior Data Engineer within the Data Technology and Products team. He comes with a wide experience across startups and enterprises with deep AWS expertise to develop scalable cloud-based data and analytics products. Within Amazon, he is the architect of Amazon’s transportation data lake and working heavily on streaming data and integration mechanisms with downstream applications through the data lake.
Diego Menin is a Senior Data Engineer within the Data Technology and Products team. He comes with a wide experience across startups and enterprises with deep AWS expertise to develop scalable cloud-based data and analytics products. Within Amazon, he is the architect of Amazon’s transportation data lake and working heavily on streaming data and integration mechanisms with downstream applications through the data lake.
 Gabriele Cacciola is a Senior Data Architect working for the Professional Service team with Amazon Web Services. Coming from a solid Startup experience, he currently helps enterprise customers across EMEA implement their ideas, innovate using the latest tech and build scalable data and analytics solutions to make critical business decisions. In his free time, Gabriele enjoys football and cooking.
Gabriele Cacciola is a Senior Data Architect working for the Professional Service team with Amazon Web Services. Coming from a solid Startup experience, he currently helps enterprise customers across EMEA implement their ideas, innovate using the latest tech and build scalable data and analytics solutions to make critical business decisions. In his free time, Gabriele enjoys football and cooking.
 Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.
Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.