AWS Open Source Blog
Performing canary deployments and metrics-driven rollback with Amazon Managed Service for Prometheus and Flagger
This post was written by Kevin Bell and Stefan Prodan.
Canary deployments are a popular tool to reduce risk when deploying software, by exposing a new version to a small subset of traffic before rolling it out more broadly. Creating the machinery to do this kind of controlled rollout, and monitoring for possible problems and rolling back if necessary, can be difficult. Flagger is a CNCF incubating project that takes care of much of the undifferentiated heavy lifting of canary deployments on Kubernetes. It supports blue/green canary deployments, and even A/B testing for a number of ingress controllers and service meshes. Additionally, Flagger works with CI/CD tools that deploy to Kubernetes, as it kicks off each canary rollout once a deployment resource has been updated in the Kubernetes API Server.
In this post, we explain how to perform canary deployments on Kubernetes using Flagger to orchestrate the rollout, promotion, and rollback of deployments. We take advantage of Flagger’s built-in Prometheus support to use Amazon Managed Service for Prometheus, a Prometheus-compatible monitoring service, to handle metrics. Also, we use its integration with AWS App Mesh for traffic control. Finally, we show how to observe the canary deployment process with Amazon Managed Grafana, a fully managed service for open source Grafana developed in collaboration with Grafana Labs, using the pre-created Grafana dashboards provided by the Flagger project.
Overview
The following diagram demonstrates the high-level interaction between each component discussed in the post. During a deployment, the numbered arrows show how all the components work together to create a feedback cycle to govern the rollout process.
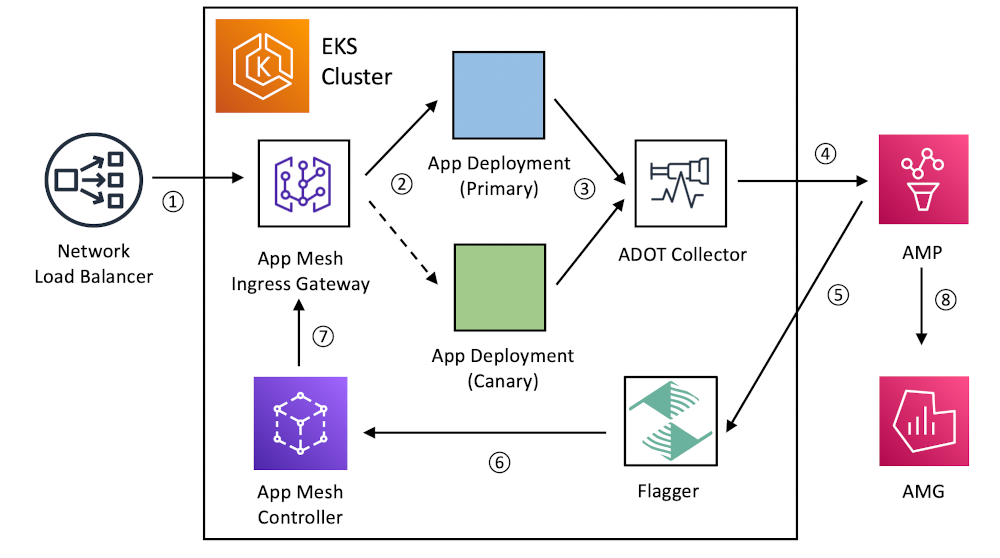
Let’s briefly walk through each step in the process:
- Traffic arrives from the internet at a Network Load Balancer, and is sent to the App Mesh Ingress Gateway, composed of a Kubernetes deployment of Envoy proxies.
- According to the weights configured in App Mesh, traffic is distributed between the primary and canary application versions, starting with a small percentage.
- The AWS Distro for OpenTelemetry Collector, deployed as a DaemonSet, collects metrics about the behavior of both primary and canary versions. In the example, we will use metrics from the Envoy proxy sidecars deployed by App Mesh to monitor basic stats, such as HTTP status codes, but it is possible to use metrics from any Prometheus exporter.
- Metrics are sent to Amazon Managed Service for Prometheus using the Prometheus remote write API.
- Metrics are monitored by Flagger through the Prometheus query API.
- If the metrics are within specified thresholds, Flagger updates App Mesh custom resource definitions (CRDs) in the Kubernetes API server, which the App Mesh Controller will propagate to the service mesh.
- The Envoy proxies in the App Mesh Ingress Gateway will receive updated configuration from App Mesh, causing them to shift more traffic to the canary version.
- Throughout the process, all metrics can be monitored and visualized in Amazon Managed Grafana.
Now that we know what the end state will be like, let’s walk through the steps for setting up a complete example.
Prerequisites
Before beginning, the following must be installed:
We will use a Bash shell, which is available on macOS and Linux, but the specific commands required will be different on Windows.
Walkthrough
Launch an Amazon EKS cluster
For this walkthrough, we will be working in the us-east-1 Region, which is one of many Regions in which all required services are available. First, we will prepare a configuration file for use with eksctl, and then we can launch an Amazon Elastic Kubernetes Service (Amazon EKS) cluster with the necessary AWS infrastructure. We will conclude this step by installing the App Mesh Controller and creating a mesh to enable traffic shifting.
Let’s create an AWS Identity and Access Management (IAM) policy for the AWS Distro for OpenTelemetry Collector to access Amazon Managed Service for Prometheus:
Prepare a configuration file for eksctl:
Launch the cluster, which will take a few minutes. Note that both the Namespaces and ServiceAccounts specified in the configuration file will be precreated in the cluster:
List nodes to make sure that the cluster is accessible:
Once the cluster is available, install the required App Mesh Controller:
Create a mesh:
Confirm that the mesh appears as expected in the App Mesh service. We should see output showing active status:
Set up Amazon Managed Service for Prometheus
Now that the Amazon EKS cluster is ready, we can set up Amazon Managed Service for Prometheus and related tools to enable the canary deployment process. This will include installing the AWS Distro for OpenTelemetry Collector using the OpenTelemetry Operator, enabling the scrape configurations needed to collect metrics for Flagger, and configuring Amazon Managed Service for Prometheus as a remote write endpoint.
Let’s start by creating an Amazon Managed Service for Prometheus workspace:
Now wait for the workspace to have an active status, as shown by this command:
Next we can install the OpenTelemetry Operator and cert-manager, on which it depends:
Check that it was installed correctly:
We should be shown something like the following:
Now that the operator is deployed, we can create the AWS Distro for OpenTelemetry Collector instance. Let’s start by getting the Prometheus endpoint to write to:
Now let’s give the precreated AWS Distro for OpenTelemetry Collector Service Account permission to access various metrics resources:
Then we can create the AWS Distro for OpenTelemetry Collector instance:
Confirm that metrics are being collected by doing a test query with awscurl:
A non-empty result shows that metrics are being collected from the cluster. The result should contain data in the result field:
Set up Amazon Managed Grafana (optional)
Amazon Managed Grafana provides advanced metric visualization and alerting on top of the data stored in Amazon Managed Service for Prometheus, and it will help us observe the canary deployment process. Note that Amazon Managed Grafana requires that either AWS Single Sign-On or another SAML IdP be available for authentication. Setting up Amazon Managed Grafana is not required by Flagger.
Let’s walk through the steps in the documentation for getting started with Amazon Managed Grafana, making sure to select the option to enable Amazon Managed Prometheus as a data source.
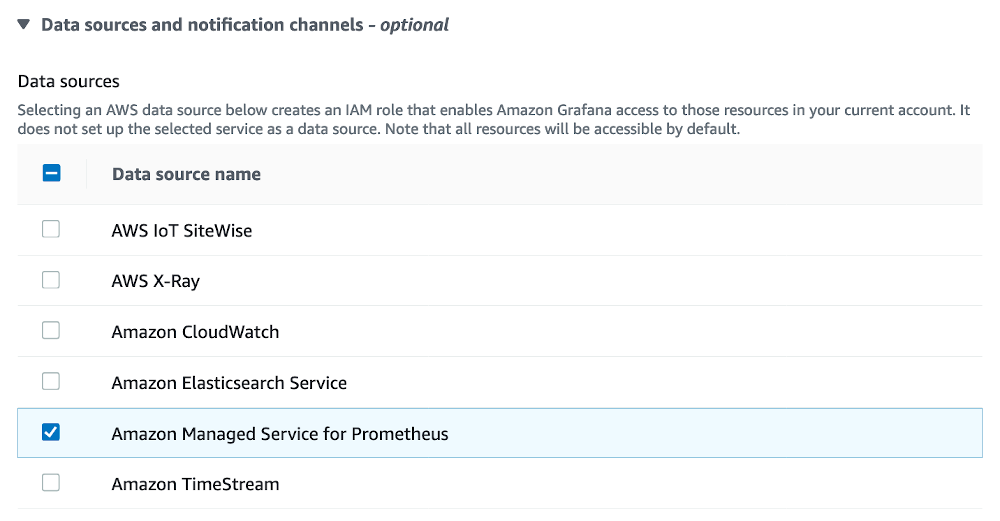
Next we will add Amazon Managed Service for Prometheus as a data source as described in the Amazon Managed Grafana documentation. Let’s select the us-east-1 Region and the same Amazon Managed Service for Prometheus workspace we created previously:
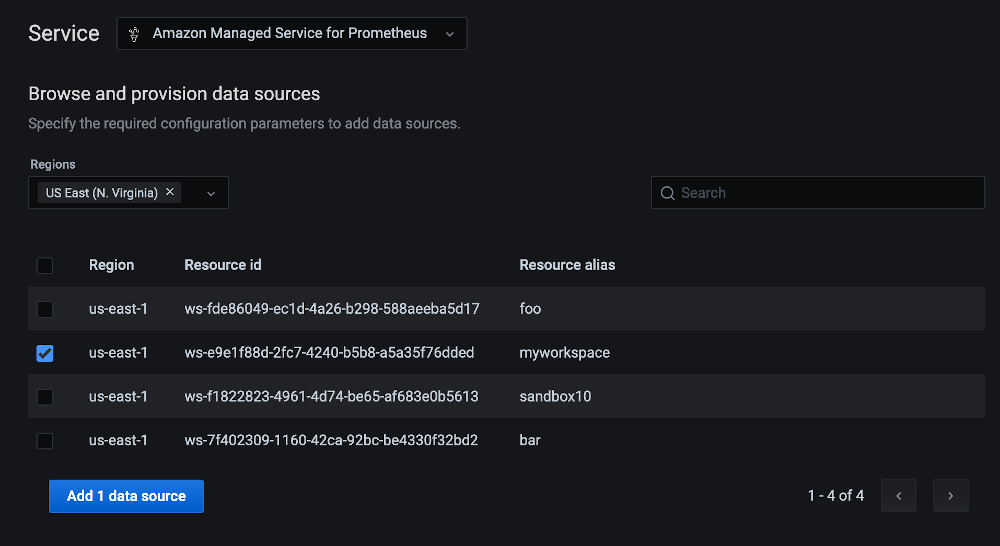
Next, in Settings rename the data source to prometheus. This will help when importing a premade dashboard later:
Finally, let’s import a precreated dashboard from the Flagger project by selecting the + icon and Import:
Then we can add the JSON config from the Flagger project and choose Save. The dashboard won’t show much yet, but we will come back to it soon.
Install Flagger
Now we’re ready to install Flagger. First we must install the AWS SIGv4 Proxy Admission Controller to allow Flagger to authenticate with Amazon Managed Service for Prometheus via IAM.
Install the admission controller:
To simplify Helm configuration, create a values file:
Then install Flagger:
Check that Flagger is installed and running:
We should get output like the following. (Note that there are two containers in the pod—Flagger and the sigv4 proxy sidecar.)
Deploy the sample app
Now that the cluster, metrics infrastructure, and Flagger are installed, we can install the sample application itself. We will use the standard Podinfo application used in the Flagger project and the accompanying loadtester tool. We also will create the Canary API resource that defines the rollout. We will use a minimal canary configuration. Find details on how to configure Flagger Canaries in the Flagger documentation.
First, let’s create a Namespace called test and enable App Mesh in it:
Install the sample application:
Install the loadtester:
Create the Canary resource:
Finally, install the App Mesh Gateway and create a gateway route:
Once the load balancer is provisioned and health checks pass, we can find the sample application at the load balancer’s public address:
It should look something like the following:
Test canary deployment
Now that both Flagger and the sample app are deployed, we can experience how canary rollout (and rollback) works in action.
First, let’s trigger an update to the Podinfo deployment and watch it be promoted successfully. Then, let’s make another change and force the canary checks to fail, causing a rollback.
Start by making a trivial change to the PodSpec:
Then make sure that some load is applied to the Podinfo app, split between canary and primary according to the rollout process. This command will run for a while without producing output while generating traffic:
Then we can watch for new events on the Canary resource in another shell:
We are shown the following as the rollout progresses:
Now if we go back to the AppMesh Canary dashboard we imported into Amazon Managed Grafana, we are shown graphs of the metrics used by Flagger. Note the increasing canary traffic over time. We may need to refresh the page and confirm that the values selected for Namespace/Primary/Canary are “test”/”podinfo-primary”/”podinfo” respectively:
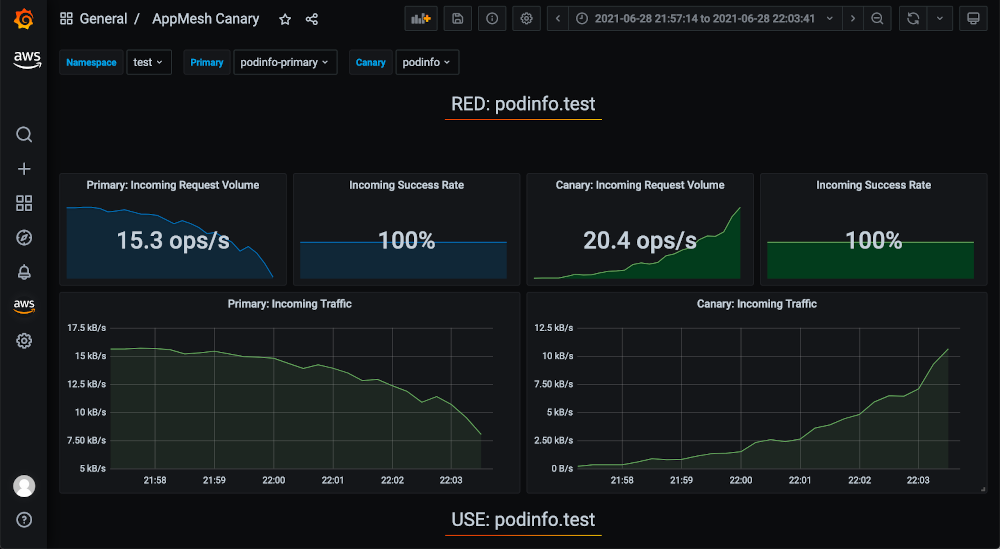
Let’s repeat the process one more time:
Apply load again:
But this time let’s wreak some havoc on the Prometheus metrics for the canary in a separate shell:
When we monitor canary events again, we are shown warnings like the following, and the rollout ultimately fails:
Again, we can view the corresponding metrics in Amazon Managed Grafana, including the decrease in success rate on the canary that caused the rollout to fail:
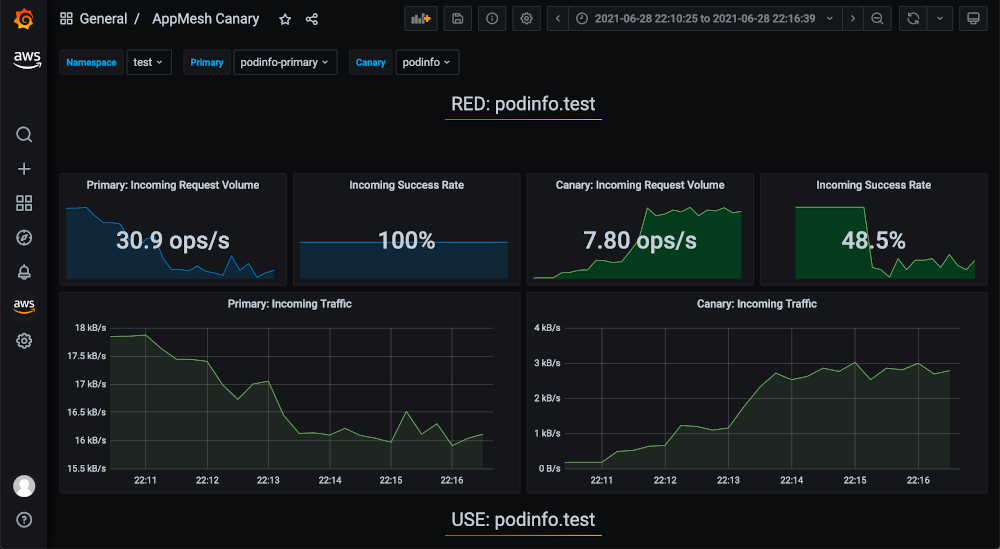
This shows how Flagger can safely roll out healthy new versions and prevent the release of versions containing errors detectable by Prometheus metrics.
Cleanup
Now that we are done trying out everything, let’s walk through deleting all the resources used.
Start with the Kubernetes resources that need to be deleted to clean up associated App Mesh resources:
Then, using eksctl, delete the Amazon EKS cluster:
Clean up the Amazon Managed Service for Prometheus workspace and ingest policy:
Refer to the documentation to delete the Amazon Managed Grafana workspace in the AWS Management Console.
Conclusion
This post explained the process for setting up and using Flagger for canary deployments together with Amazon EKS, Amazon Managed Service for Prometheus, Amazon Managed Grafana, and AWS App Mesh. We only scratched the surface of what’s possible with canary deployment and metrics-driven rollback, but we hope this helps show the value that canary rollouts provide.
Beyond what was covered in this post, you can also consider Flagger’s Slack integration and webhook notifications for failed canary deployments. Amazon Managed Grafana also allows you to alert on a wide variety of metrics data and supports notifying an Amazon Simple Notification Service (Amazon SNS) topic as well as Slack, PagerDuty, and more.
To learn more, read the Amazon Builders’ Library post about automating safe, hands-off deployments, which discusses how we gradually deploy to production at AWS to minimize risk. You can also check out the Flagger hands-on guide that includes additional Weaveworks tools for GitOps.

Stefan Prodan
Stefan Prodan is a Developer Experience engineer at Weaveworks and an open source contributor to cloud-native projects like Flagger, FluxCD, Helm Operator, SMI and others. He worked as a software architect and a DevOps consultant, helping companies embrace DevOps and the SRE movement. Stefan has over 15 years of experience with software development and he enjoys programming in Go and writing about distributed.