AWS Public Sector Blog
Building an editorial AI assistant to support peer review with AWS Generative AI Innovation Center
This post was written with Ian Mulvany and Helen Macdonald from the BMJ (British Medical Journal).
For over 185 years, BMJ Group has advanced its purpose to improve health outcomes by working toward a vision of a healthier world for all. It does this mainly by publishing peer reviewed, evidence-based research across a portfolio of nearly 70 scientific and allied health journals, led by its flagship title, The BMJ.
In partnership with the AWS Generative AI Innovation Center, BMJ Group has developed an AI-powered editorial assistant designed to help journal editors screen submitted research manuscripts to make better decisions about which papers to send for further peer review, which to reject, and why. The tool also aims to improve article capture rates without compromising publication quality.
“Working with the Generative AI Innovation Center has given us the technical foundation to move quickly while maintaining the rigor that healthcare and medical research domains demand. This partnership went beyond technology: the Generative AI Innovation Center team worked closely with us in navigating the complexities of applying AI to scholarly publishing. AI can be a powerful ally in this domain, but only if we approach the opportunity with appropriate humility about the importance of the work.” — Ian Mulvany, Chief Technology Officer, BMJ Group
The challenge of finding quality research in a sea of submissions
BMJ Group’s journal portfolio receives tens of thousands of manuscript submissions annually. The editorial assessment and peer review process of submitted manuscripts lies at the core of the Group’s operations. This process is a rigorous, multistage quality control mechanism, typically spanning 3–6 months, where several independent experts evaluate each manuscript’s methodology, validity, and significance.
Two interconnected challenges define the operational reality:
1. Optimizing peer review through better upstream screening – Currently, around half of submissions are rejected at initial editor screening, but a further significant percentage are rejected after peer review. This high downstream rejection rate signals that issues are passing through early screening undetected, consuming valuable reviewer and editorial time. Where submissions are rejected, editors should also articulate reasons for rejection to authors.
2. Better placement of manuscripts across the portfolio – With a broad portfolio of nearly 70 journals across the Group, BMJ editors also face the challenge of identifying suitable homes for manuscripts that might not fit their journal’s scope. Without a cross-portfolio transfer system with defined criteria, rejected manuscripts often require rescreening by the receiving journal. In all, 16% of manuscripts rejected without a transfer offer go on to be published elsewhere; a proportion of these articles could potentially have found a home within the Group’s portfolio.
A human-centered agentic AI assistant
Peer review remains fundamental to trustworthy research. Today, agentic AI solutions have the potential to help the editor make better informed decisions earlier in the process. From the outset, we established two design principles: the AI assistant should augment the work of editors, not replace their judgment, and editors must retain full autonomy over all screening decisions.
These principles, together with BMJ Group’s embedded subject matter experts and editors, guided our joint proof of concept (POC) collaboration.
The resulting Editorial AI Assistant delivers structured, evidence-backed analysis that would otherwise require substantial manual review. The generated analyses are accompanied by detailed source attribution and reasoning. From a technical perspective, the solution uses a multi-agent architecture comprising eight specialized agents, built on Amazon Bedrock AgentCore:
- Scope and content fit agent – Assesses alignment with the target journal’s themes based on internal editorial guidelines.
- Novelty and impact agent – Contextualizes submissions against existing literature by querying OpenAlex and PubMed to assess originality.
- Methodology reporting agent – Evaluates study design and methodological flaws against EQUATOR (specifically, CONSORT, STROBE, and PRISMA) and CASP guidelines.
- Methodology validation agent – Generates and executes code to verify statistical claims directly from the manuscript.
- Ethics and compliance agent – Verifies basic research ethics and regulatory standards.
- Author integrity agent – Consolidates signals from PubPeer, ORCID, and other databases to flag authorship concerns, such as conflicts of interest.
- Synthesis agent – Combines findings from the evaluation agents to produce recommended actions.
- Writer agent – Provides coherent editorial commentary based on the outputs of the Synthesis agent.
Each agent is powered by Claude by Anthropic in Amazon Bedrock models with tools tailored to its task. AWS Step Functions orchestrates the pipeline, with gatekeeper logic enabling early exit when a manuscript is clearly out of scope, saving compute and editor time. The agents connect to external systems through the Model Context Protocol (MCP), providing a standardized interface for tool use through Amazon Bedrock AgentCore Gateway.
The following diagram illustrates the solution architecture.
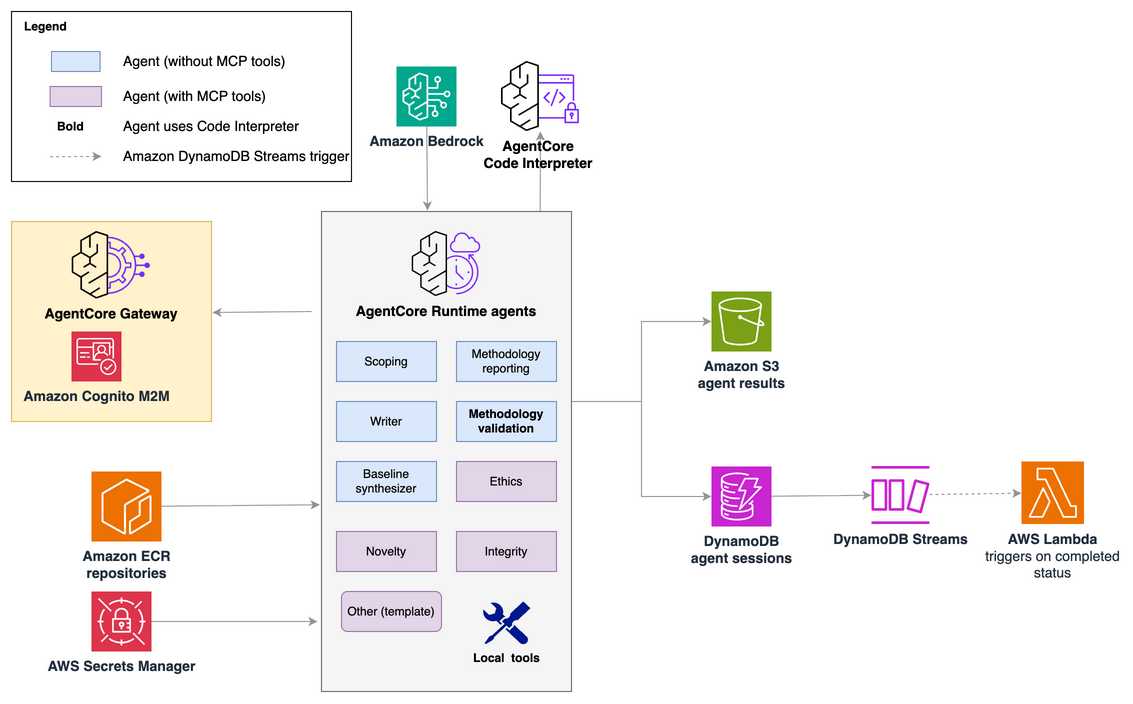
Figure 1: High-level architecture of the Editorial AI Assistant
Early results produced encouraging signs
Initial testing across 21 manuscripts with editors from Emergency Medical Journal (EMJ) and BMJ Open demonstrated encouraging results, with particular strength in methodology review and novelty assessment. Editors validated the practical value of surfaced insights. The solution supported deeper analyses that wouldn’t have been achievable at the editor screening stage due to time constraints. Beyond the POC, further efforts would focus on output focus and succinctness.
The POC solution achieved over 80% success rate across three technical evaluation dimensions: accuracy of flagging known errors, detection of fundamental methodological flaws, and the degree of alignment between AI generated recommendations and actual publishing outcomes.
The following bar graph illustrates the solution evaluation results. It shows mean helpfulness ratings with 95% bootstrap confidence intervals, as rated by practicing editors, for each agent. The methodology agents scored highest (above 3.0), followed by the investigative agents (novelty and integrity), with the gatekeeper agents (scope and ethics) scoring lowest (around 2.0). The methodology and gatekeeper groups have non-overlapping confidence intervals.
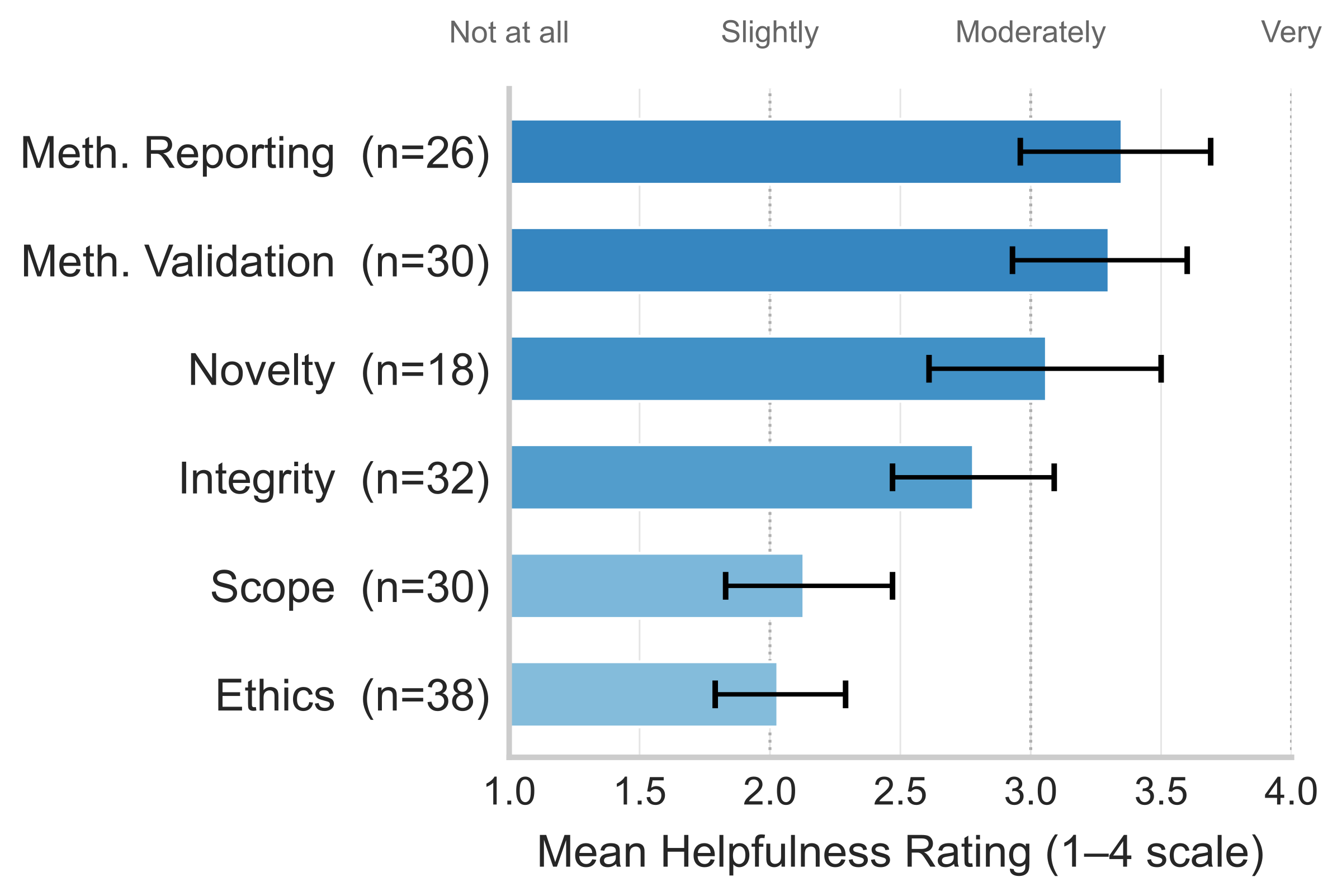
Figure 2: BMJ Editor solution evaluation results
Implications for agentic AI adoption in academic publishing
This work has reinforced that AI in scholarly publishing must be developed with its users, not deployed upon it. Our key learnings are:
1. Cocreate using scholarly best practices – Cross-functional teams of editors and publication integrity specialists worked alongside technologists from the start, jointly defining evaluation criteria, reviewing agent outputs, and providing rapid feedback that guided iterative improvement.
2. Decompose complex workflows into focused tasks – Specialized agents, each responsible for a single evaluation dimension, produced more reliable and actionable outputs than a single broad evaluation.
3. Predictable workflows build editorial trust – A multi-agent workflow pattern, designed to mirror the editor’s workflow, reflected the priorities of the academic publishing domain where consistency, predictability, and auditability are valued more highly than flexibility. This workflow is shown in the following flow diagram.

Figure 3: High-level overview of the workflow multi-agentic pattern powering the Editorial AI Assistant
3. Structure drives quality – Agents performed best when evaluating manuscripts against well-defined standards such as reporting checklists, and editors valued structured outputs with clear reasoning and source attribution most. Where evaluation required nuanced judgment built from years of editorial experience, the agentic AI solution has less reliable outputs. This reinforces that AI solutions should augment editorial expertise, not fully automate it.
4. Presentation shapes trust – Outputs should be structured to let editors scan top-level findings quickly and drill into detailed reasoning and sources where warranted—surfacing complexity on demand rather than all at once.
Scaling from POC into practice
This project has validated that AI might meaningfully support editor screening while respecting scholarly best practices. BMJ Group envisions further development, additional testing, and integration with their ScholarOne manuscript management system. Eventually, this tool might be extended to serve peer reviewers beyond initial editor screening.
For stakeholders considering similar AI initiatives, this collaboration offers clear lessons on thoughtful AI adoption in this domain: start with defined success metrics, maintain human expertise at the center, instill transparency in AI-assisted decision-making, and collaborate with technology providers who are prepared to dive deep to understand your unique requirements.
To learn how AWS can help your organization build AI-powered solutions, contact the AWS Generative AI Innovation Center.