AWS Storage Blog
Data management at scale using Amazon S3 Batch Operations
A challenge for many enterprises with data at the scale of petabytes is managing and taking actions on their data to migrate, improve efficiency, and drive down costs through automation. Amazon S3 buckets can hold billions of objects and exabytes of data, letting you build your applications with the ability to grow and scale as your business grows. With data at that scale, customers need methods to filter through data, organize objects, and take bulk actions, or they may find themselves spending a lot of time and energy trying to meet their business storage requirements. Without organized and easily manageable data, innovation may suffer, as may security, efficiency, and cost optimization.
In a previous blog post, we reviewed using Amazon S3 Inventory and Amazon Athena to manage lists of your objects and sort them by various criteria producing curated lists of objects in a CSV for automation. In this blog post, I walk through using Amazon S3 Batch Operations to restore and cross-Region copy data. This continues the example with a CSV from the previous blog post for a customer doing a sequenced S3 Glacier Deep Archive restore and cross-Region copy, using S3 Batch Operations to target specific files to restore and then copy in sequence. I also review other automation options. With S3 Batch Operations, you can optimize costs and workloads by taking actions at scale to minimize manual work and improve efficiency, allowing you to focus on core competencies rather than data management.
S3 Batch Operations overview
Amazon S3 Batch Operations is an S3 storage management feature that lets you manage billions of objects at scale with just a few clicks in the Amazon S3 management console or a single API request. S3 Batch Operations can perform a single operation on lists of Amazon S3 objects that you specify. A single job can perform a specified operation on billions of objects containing exabytes of data. Amazon S3 tracks progress, sends notifications, and stores a detailed completion report of all actions, providing a fully managed, auditable, and serverless experience.
With S3 Batch Operations, you can perform storage management tasks, such as copying objects between buckets, replacing object tag sets, modifying access controls, and restoring archived objects from S3 Glacier or S3 Glacier Deep Archive. Additionally, S3 Batch Operations gives you the ability to invoke AWS Lambda functions to perform custom actions on objects.

How an S3 Batch Operations job works
A job is the basic unit of work for S3 Batch Operations. A job contains all of the information necessary to run the specified operation on a list of objects. To create a job, you give S3 Batch Operations a list of objects and specify the action to perform on those objects. Here is a list of operations supported by S3 Batch Operations.
A batch job performs a specified operation on every object that is included in its manifest. A manifest lists the objects that you want a batch job to process and it is stored as an object in a bucket. You can use a comma-separated values (CSV)-formatted Amazon S3 inventory report as a manifest, which makes it easy to create large lists of objects located in a bucket. You can also specify a manifest in a simple CSV format that enables you to perform batch operations on a customized list of objects contained within a single bucket. You can then create a job and start your operation. Check the documentation on managing S3 Batch Operations jobs for more information.
Getting started with S3 Batch Operations in the Amazon S3 console
You can create S3 Batch Operations jobs using the AWS Management Console, AWS CLI, Amazon SDKs, or REST API. You can link to your source, destination and to your inventory file for automation. For more information, see the documentation on granting permissions for Amazon S3 Batch Operations.

Overview of creating an S3 Batch Operations job
- Sign in to the AWS Management Console and open the Amazon S3 console.
- Choose Batch Operations on the navigation pane of the Amazon S3 console, then choose Create job.
- Choose the Region where you want to create your job.
- Under Manifest format, choose the type of manifest object to use. Then choose Next.
- If you choose S3 inventory report, enter the path to the manifest.json object that Amazon S3 generated as part of the CSV-formatted Inventory report, and optionally the version ID for the manifest object if you want to use a version other than the most recent.
- If you choose CSV, enter the path to a CSV-formatted manifest object. The manifest object must follow the format described in the console. You can optionally include the version ID for the manifest object if you want to use a version other than the most recent.
- Under Operation, choose the operation that you want to perform on all objects listed in the manifest. Fill out the information for the operation you chose and then choose Next.
- Fill out the information for Configure additional options and then choose Next.
- For Review, verify the settings. If you need to make changes, choose Previous. Otherwise, choose Create Job.
Job responses
If the Create Job request succeeds, Amazon S3 returns a job ID. The job ID is a unique identifier that Amazon S3 generates automatically so that you can identify your Batch Operations job and monitor its status. When you create a job through the AWS CLI, Amazon SDKs, or REST API, you can set S3 Batch Operations to begin processing the job automatically. The job runs as soon as it’s ready and not waiting behind higher-priority jobs.
Example solution with S3 Batch Operations
Now that we have reviewed how to create a S3 Batch Operations job, we will configure a S3 Batch Operations job for a restore and another for a cross-Region copy, both using a CSV input of objects you want to automate. This will allow you to bulk process the contents of the CSV list of objects with success and failures logged to an output file.
From the S3 console, choose Batch Operations. You will input the bucket name and object key used to perform the selected operation. You will then enter your Region, and select CSV for the Manifest format.

Configure S3 Batch Operations for S3 Glacier or S3 Glacier Deep Archive restore
You can use S3 Batch Operations to perform restore operations from S3 Glacier or S3 Glacier Deep Archive to the S3 Standard storage class. You also have the option to specify a hold time in the S3 Standard storage class before you revert the objects back to the S3 Glacier or S3 Glacier Deep Archive storage classes. Often data is “restored” to be acted on, for example you can restore an object, and then copy a file to another location as we did in our customer example. By using the method described, large numbers of objects can be restored and copied in parallel to maximize performance and minimize cost. This helps you to restore billions of objects across several days in parallel.
First, select the Restore option.
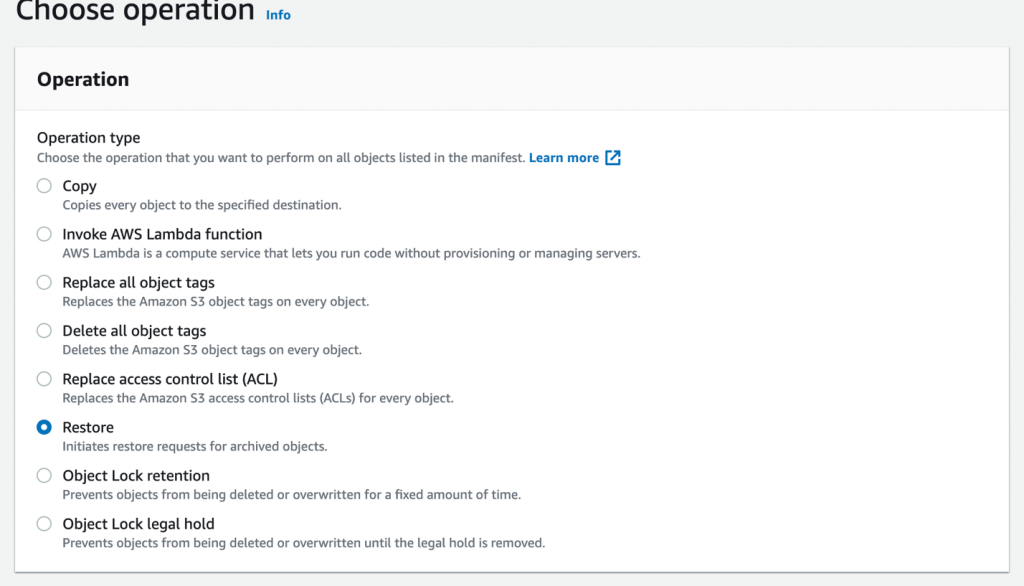
Then select the days to hold the data in standard until it automatically reverts to Amazon S3 Glacier or S3 Glacier Deep Archive, and the method of retrieval. Bulk is up to 48 hours, but Standard is 3–5 hours but at higher cost.
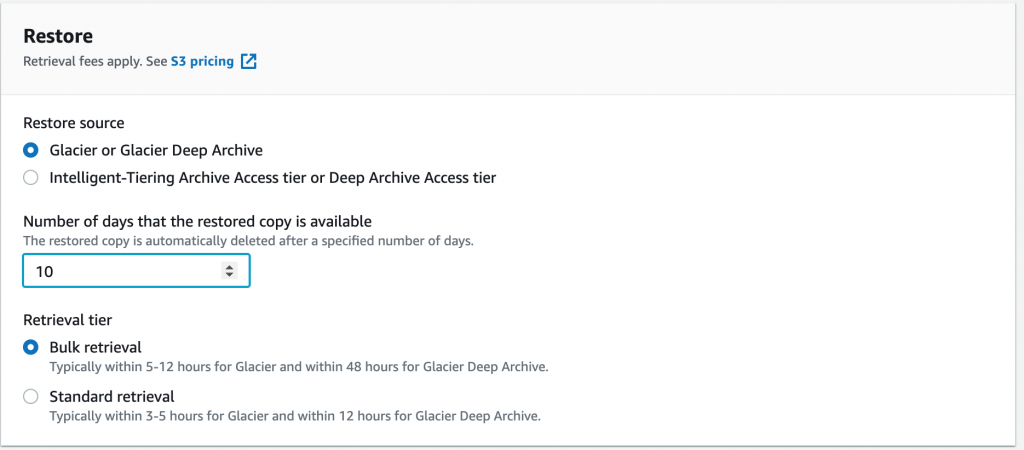
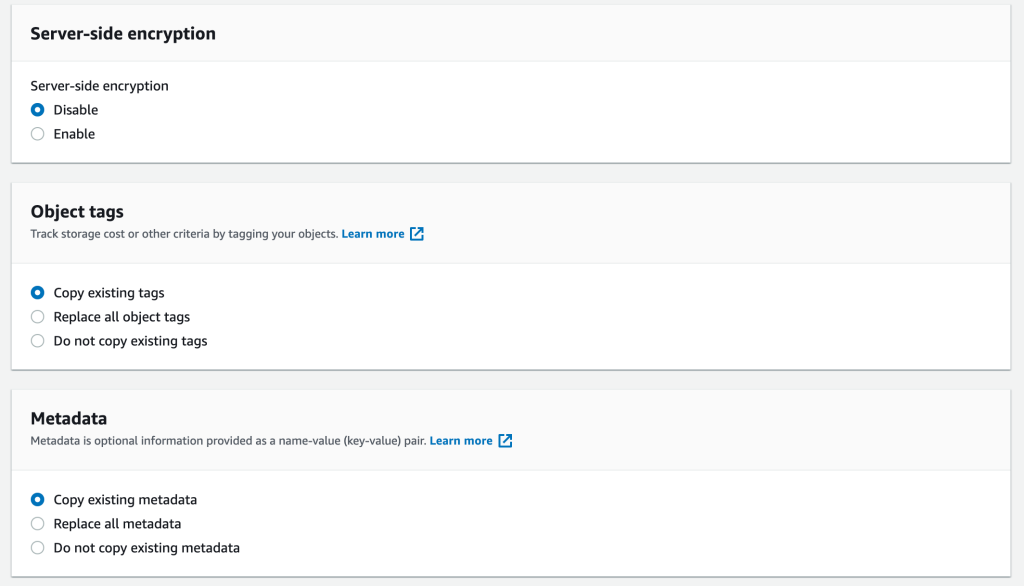
Other S3 Batch Operations options
A number of other S3 Batch Operations options are available for your job. The following screenshots depicts the encryption, object tagging, and metadata options.
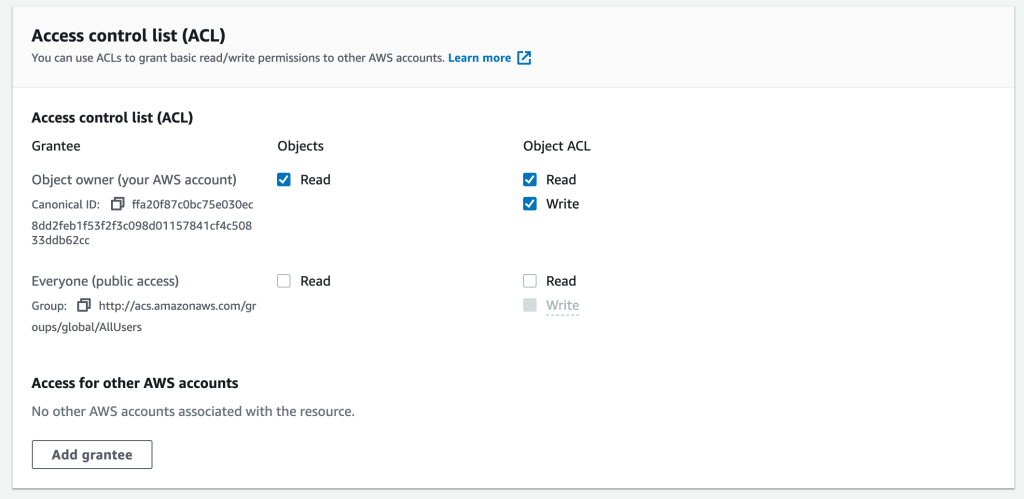
The following screenshot shows Access control list (ACL) permission options in Amazon S3 Batch Operations. Review the documentation for your preferred option based on your use case.
Set your S3 Batch Operations completion report location
The logs for S3 Batch Operations are stored at the location of your choosing. Remember to check to make sure you have permission for S3 Batch Operations to write the log file to your chosen directory or the job will fail.

S3 Batch Operations permissions
For S3 Batch Operations to work, you must select a role with permissions to perform the desired action on the source and destination bucket. The documentation goes into the examples of permissions and roles needed. If you are doing a cross-Region copy, make sure that the role has the required permissions, in addition to the required permissions on all objects in the job.

IAM resources:
- General IAM role permissions
- Supporting documentation
- Video on setting S3 Batch Operations permissions
Run the S3 Batch Operations job
Once the job is ready to run it will show “awaiting your confirmation to run.” Select the job and then Run job. A confirmation page will show, then select run once again. Your job will then schedule to process and the transfers will start. S3 Batch Operations will queue them to run.
Note: transaction rates will be influenced by the bandwidth between sites, size of objects and number of objects. When running jobs with extremely large numbers of objects (billions), we recommend working with your Technical Account Manager and consider opening an AWS Infrastructure Event management (IEM) ticket.
Monitor job and check your logs
You can monitor the status of your job and the details on the percentage complete, and failure rate as it performs. You can check the log files. If you experience failures, then investigate and rerun the job, or filter out just the failures. Common reasons for failure are lack of permissions for the object, or if the object is > 5 GB. If that is the case, an alternative copy method will need to be used.
Logs with failures
Here is a sample log with failures that shows what files failed to transfer. The log file has the necessary information to retry the job without modification. You can load the error log into a new S3 Batch Job and retry. If you retry an entire copy job, the destination object will be over written.

Other S3 Batch Operations operations
There are many other tasks you can do with Amazon S3 Batch Operations such as Amazon S3 Glacier or Amazon S3 Glacier Deep Archive restore, Object Lock setting, Delete Tags, and invoke Lambda functions as examples. With Lambda, you can write code to do any number of tasks and invoke them with the S3 Batch Operations automation process while Lambda scales to perform those operations.
Configure S3 Batch Operations for cross-Region copy
Alternatively, to the Restore, to copy data, select the copy operation type from a range of operations. These can all be performed on a CSV list of objects at scale (tens to billions of objects) between buckets and between accounts if permissions allow access.

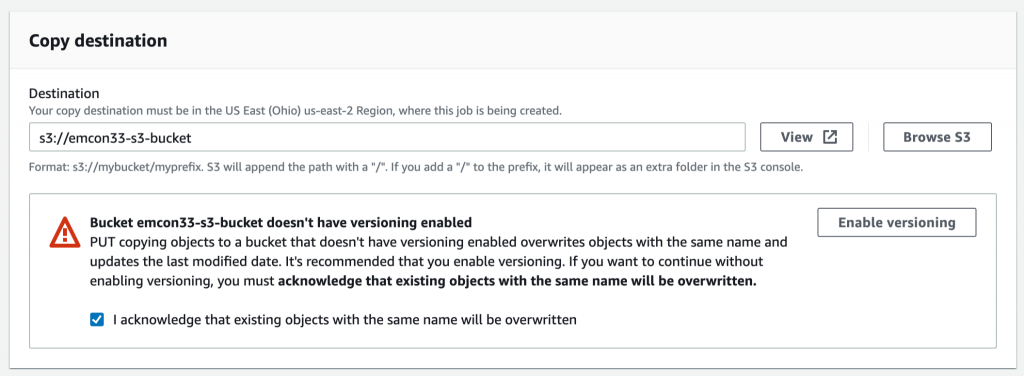
Select destination bucket for copy
You then select a destination bucket to perform the copy operation from your source bucket. S3 Batch Operations will perform the copy operation from your source bucket to destination bucket.
Set storage class
As part of a copy you can set the storage class to optimize your costs. You can choose from S3 Standard, S3 Intelligent-Tiering, S3 Standard-Infrequent Access, S3 One Zone-Infrequent Access, S3 Glacier, and S3 Glacier Deep Archive. This lets you choose the storage class that is ideal for your access patterns, and can help you optimize costs on the destination side.

The rest of the options follow the restore procedure.
Costs for S3 Batch Operations
You are charged for each S3 Batch Operations job ($0.25 per job), the number of objects per job ($1.00 per million object operations performed), in addition to any charges associated with the operation that S3 Batch Operations performs on your behalf, including data transfer, requests, and other charges. As always verify any numbers for your Region with the latest Amazon S3 pricing page.
Other migration options
S3 Batch Operations is ideal for a lot of workloads and use cases, but it is not always the right fit for the job. S3 Batch Operations does not support objects larger than 5 GB for the copy operation. S3 Batch Operations currently does not perform the deletion of objects, though you could do this with a Lambda function. GitHub additionally has a number of code submissions that apply to these use cases.
For workloads where S3 Batch Operations is not the right choice:
- Native S3 Replication (CRR or SRR)
- AWS DataSync
- Amazon EMR data with S3distcp
- Amazon S3 Storage Gateway
Real-world example
The inspiration for the solution demonstrated in this post comes from an instance of a customer needing to restore data from S3 Glacier Deep Archive and then copy that data between Regions and accounts. The quantity of the data was too large to do as 1 big inventory file so they optimized the order for restore speed, curated the CSV into daily runs, and then executed in sequence. The customer managed to restore 1 PB of data, with a hold for 7 days. Once they completed their restore, they then used a cross-Region and cross-account copy on that same CSV list. This enabled them to stage a subset of the data for restore then copy, parallelizing the work while minimizing the days in S3 Standard. The customer averaged 1 PB a day over 22 days with this method, but your mileage will vary based on object size, number, and cross-Region traffic.
Conclusion
With the scale and quantity of object data you can store in Amazon S3, many customers need help with managing that data through automation tools to optimize placement and drive down costs. Amazon S3 Batch Operations is a great tool to execute automation to manage your objects at scale in Amazon S3 and Amazon S3 Glacier. With S3 Batch Operations, you can increase efficiency by placing your data in the right storage class, migrate your data to a bucket in a different Region, and restore your data from archive. These steps can be combined with complete control to restore and copy data in stages, for example, using a “daily” CSV file, as we did in the customer example.
Thanks for reading this post! If you have any comments or questions, please leave them in the comments section.