AWS Big Data Blog
How Verizon Media Group migrated from on-premises Apache Hadoop and Spark to Amazon EMR
This is a guest post by Verizon Media Group.
At Verizon Media Group (VMG), one of the major problems we faced was the inability to scale out computing capacity in a required amount of time—hardware acquisitions often took months to complete. Scaling and upgrading hardware to accommodate workload changes was not economically viable, and upgrading redundant management software required significant downtimes and carried a large amount of risk.
At VMG, we depend on technologies such as Apache Hadoop and Apache Spark to run our data processing pipelines. We previously managed our clusters with Cloudera Manager, which was subject to slow release cycles. As a result, we ran older versions of available open-source releases and couldn’t take advantage of the latest bug fixes and performance improvements on Apache projects. These reasons, combined with our already existing investment in AWS, made us explore migrating our distributed computing pipelines to Amazon EMR.
Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark.
This post discusses the issues we encountered and solved while building a pipeline to address our data processing needs.
About us
Verizon Media is, ultimately, an online advertising company. Most online advertising today is done through display ads, also known as banners or video ads. Regardless of format, all internet ads usually fire various kinds of beacons to tracking servers, which are usually highly scalable web server deployments with a sole responsibility to log received beacons to one or multiple event sinks.
Pipeline architecture
In our group, which deals mostly with video advertising, we use NGINX web servers deployed in multiple geographical locations, which log events fired from our video player directly to Apache Kafka for real-time processing and to Amazon S3 for batch processing. A typical data pipeline in our group involves processing such input feeds, applying validation and enrichment routines, aggregating resulting data, and replicating it to further destinations for reporting purposes. The following diagram shows a typical pipeline that we created.
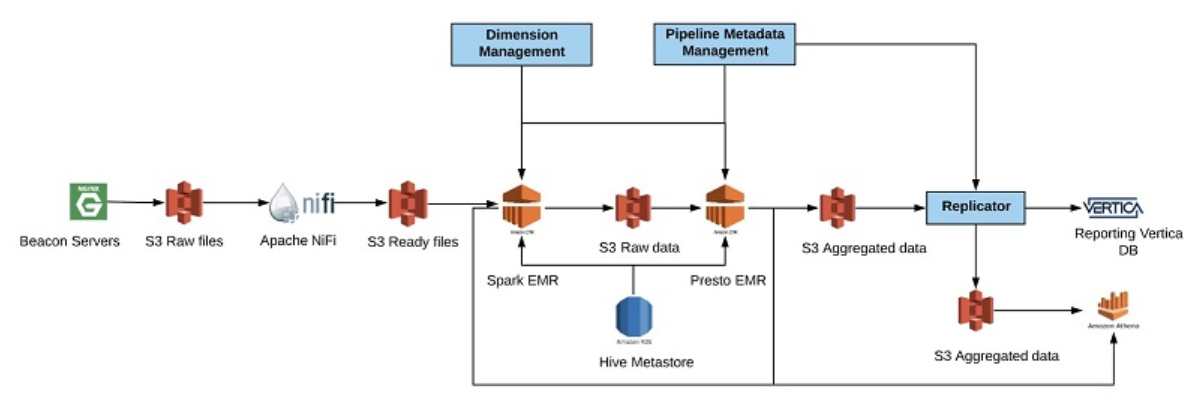
We start getting data on our NGINX beacon servers. The data is stored in 1-minute intervals on local disk in gzip files. Every minute, we move the data from NGINX servers to raw data location in S3. Upon landing on S3, the file sends a message to Amazon SQS. Apache NiFi is listening to SQS messages to start working on files. During this time, NiFi groups smaller files into larger files and stores the outcome in a special path on a temporary location on S3. The path name is combined using an inverse timestamp to make sure we store data in a random location to avoid reading bottlenecks.
Every hour, we scale out a Spark cluster on Amazon EMR to process the raw data. This processing includes enriching and validating the data. This data is stored in a permanent location folder on S3 in an Apache ORC columnar format. We also update the AWS Glue Data Catalog to expose this data in Amazon Athena in case we need to investigate it for issues. After raw data processing is finished, we downscale the Spark EMR cluster and start aggregating data based on pre-defined aggregation templates using Presto on Amazon EMR. The aggregated data is stored in ORC format in a special location on S3 for aggregated data.
We also update our Data Catalog with the location of the data so we can query it with Athena. Additionally, we replicate the data from S3 into Vertica for our reporting to expose the data to internal and external customers. In this scenario, we use Athena as the disaster recovery (DR) solution for Vertica. Every time our reporting platform sees that Vertica is in bad health, we automatically fail over to Amazon Athena. This solution proved to be extremely cost-effective for us. We have another use case for Athena in our real-time analytics that we do not discuss in this post.
Migration challenges
Migration to Amazon EMR required us to make some design changes to get the best results. When running big data pipelines on the cloud, operational cost optimization is the name of the game. The two major costs are storage and compute. In traditional on-premises Hadoop warehouses, these are coupled as storage nodes that also serve as computation nodes. The disadvantage of this coupling is that any changes to the storage layer, such as maintenance, can also affect the computational layer. In an environment such as AWS, we can decouple storage and computation by using S3 for storage and Amazon EMR for computation. This provides a major flexibility advantage when dealing with cluster maintenance because all clusters are ephemeral.
To further save costs, we had to figure out how to achieve maximum utilization on our computational layer. This meant that we had to switch our platform to using multiple clusters for different pipelines, where each cluster is automatically scaled depending on the pipeline’s needs.
Switching to S3
Running a Hadoop data warehouse on S3 introduces additional considerations. S3 is not a file system like HDFS and does not provide the same immediate consistency guarantees. You can consider S3 as an eventually consistent object store with a REST API to access it.
The rename
A key difference with S3 is that rename is not an atomic operation. All rename operations on S3 run a copy followed by a delete operation. Executing renames on S3 is undesirable due to running time costs. To use S3 efficiently, you must remove the use of any rename operations. Renames are commonly used in Hadoop warehouses at various commit stages, such as moving a temporary directory to its final destination as an atomic operation. The best approach is to avoid any rename operations and instead write data once.
Output committers
Both Spark and Apache MapReduce jobs have commit stages that commit output files produced by multiple distributed workers to final output directories. Explaining how output committers work is beyond the scope of this post, but the important thing is that standard default output committers designed to work on HDFS depend on rename operations, which as explained previously have a performance penalty on storage systems like S3. A simple strategy that worked for us was disabling speculative execution and switching the output committer’s algorithm version. It is also possible to write your own custom committers, which do not depend on renames. For example, as of Amazon EMR 5.19.0, AWS released a custom OutputCommitter for Spark that optimizes writes to S3.
Eventual consistency
One of the major challenges working with S3 is that it is eventually consistent, whereas HDFS is strongly consistent. S3 does offer read-after-write guarantees for PUTS of new objects, but this is not always enough to build consistent distributed pipelines on. One common scenario that comes up a lot in big data processing is one job outputting a list of files to a directory and another job reading from that directory. For the second job to run, it has to list the directory to find all the files it has to read. In S3, there are no directories; we simply list files with the same prefix, which means you might not see all the new files immediately after your first job is finished running.
To address this issue, AWS offers EMRFS, which is a consistency layer added on top of S3 to make it behave like a consistent file system. EMRFS uses Amazon DynamoDB and keeps metadata about every file on S3. In simple terms, with EMRFS enabled when listing an S3 prefix, the actual S3 response is compared to metadata on DynamoDB. If there’s a mismatch, the S3 driver polls a little longer and waits for data to show up on S3.
In general, we found that EMRFS was necessary to ensure data consistency. For some of our data pipelines, we use PrestoDB to aggregate data that is stored on S3, where we chose to run PrestoDB without EMRFS support. While this has exposed us to the eventual consistency risk for our upstream jobs, we found that we can work around these issues by monitoring for discrepancies between downstream and upstream data and rerunning the upstream jobs if needed. In our experience, consistency issues happen very rarely, but they are possible. If you choose to run without EMRFS, you should design your system accordingly.
Automatic scaling strategies
An important and yet in some ways trivial challenge was figuring out how to take advantage of Amazon EMR automatic scaling capabilities. To achieve optimal operational costs, we want to make sure no server is sitting idle.
To achieve that, the answer might seem obvious—create a long-running EMR cluster and use readily available automatic scaling features to control a cluster’s size based on a parameter, such as available free memory on the cluster. However, some of our batch pipelines start every hour, run for exactly 20 minutes, and are computationally very intensive. Because processing time is very important, we want to make sure we don’t waste any time. The optimal strategy for us is to preemptively resize the cluster through custom scripts before particular big batch pipelines start.
Additionally, it would be difficult to run multiple data pipelines on a single cluster and attempt to keep it at optimal capacity at any given moment because every pipeline is slightly different. We have instead opted to run all our major pipelines on independent EMR clusters. This has a lot of advantages and only a minor disadvantage. The advantages are that each cluster can be resized at exactly the required time, run the software version required by its pipeline, and be managed without affecting other pipelines. The minor disadvantage is that there’s a small amount of computational waste by running extra name nodes and task nodes.
When developing an automatic scaling strategy, we first tried to create and drop clusters every time we need to run our pipelines. However, we quickly found that bootstrapping a cluster from scratch can take more time than we’d like. We instead keep these clusters always running, and we upsize the cluster by adding task nodes before the pipeline starts and remove the task nodes as soon as the pipeline ends. We found that by simply adding task nodes, we can start running our pipelines much faster. If we run into issues with long-running clusters, we can quickly recycle and create a new one from scratch. We continue to work with AWS on these issues.
Our custom automatic scaling scripts are simple Python scripts, which usually run before a pipeline starts. For example, assume that our pipeline consists of a simple MapReduce job with a single mapping and reduce phase. Also assume that the mapping phase is more computationally expensive. We can write a simple script that looks at the amount of data that needs to be processed the next hour and figures out the amount of mappers that are needed to process this data in the same way that a Hadoop job does. When we know the amount of mapping tasks, we can decide how many servers we want to run all the mapper tasks in parallel.
When running Spark real-time pipelines, things are a little trickier because we sometimes have to remove computational resources while the application is running. A simple strategy that worked for us is to create a separate real-time cluster in parallel to the existing one, scale it up to a required size based on amount of data processed during the last hour with some extra capacity, and restart the real-time application on the new cluster.
Operational costs
You can evaluate all AWS costs up front with the EC2 calculator. The main costs when running big data pipelines are storage and computation, with some extra minor costs such as DynamoDB when using EMRFS.
Storage costs
The first cost to consider is storage. Because HDFS has a default replication factor of 3, it would require 3 PB of actual storage capacity instead of 1 PB.
Storing 1 GB on S3 costs ±$0.023 per month. S3 is already highly redundant so you don’t need to take the replication factor into account, which reduces our costs immediately by 67%. You should also consider the other costs for write or read requests, but these usually tend to be small.
Computation costs
The second-largest cost after storage is the cost of computation. To reduce computation costs, you should take advantage of reserved instance pricing as much as possible. An m4.4xlarge instance type with 16 VCPUs on AWS costs $0.301 an hour when it is reserved for 3 years, with all fees up-front. An On-Demand Instance costs $0.8 an hour, which is a 62% difference in price. This is easier to achieve in larger organizations that perform regular capacity planning. An extra hourly fee of $0.24 is added to every Amazon EMR machine for the use of the Amazon EMR platform. It is possible to reduce costs even further by using Amazon EC2 Spot Instances. For more information, see Instance Purchasing Options.
To achieve optimal operational costs, try to make sure that your computation clusters are never sitting idle and try to downscale dynamically based on the amount of work your clusters are doing at any given moment.
Final thoughts
We have been operating our big data pipelines on Amazon EMR for over a year and storing all our data on S3. At times, our real-time processing pipelines have peaked at handling more than 2 million events per second, with a total processing latency from the initial event to updated aggregates of 1 minute. We’ve been enjoying the flexibility around Amazon EMR and its ability to tear down and recreate clusters in a matter of minutes. We are satisfied with the overall stability of the Amazon EMR platform and we will continue working with AWS to improve it.
As we have mentioned before, cost is a major factor to consider, and you could argue that it could be cheaper to run Hadoop in your own data centers. However, this argument hinges on your organization’s ability to do so efficiently; it may have hidden operational costs as well as reduce elasticity. We know through first-hand experience that running on-premises is not an undertaking that you should take lightly and requires a lot of planning and maintenance. We believe that platforms such as Amazon EMR bring a lot of advantages when designing big data systems.
Disclaimer: The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the authors
 Lev Brailovskiy is Director of Engineering leading Service Engineering Group in Supply Side Platform (SSP) at Verizon Media. He has over 15 years of experience designing and building software systems. In the past six years, Lev spent time designing, developing, and running large-scale reporting and data processing software both in private Data Centers and in the public Cloud. He can be be contacted via LinkedIn.
Lev Brailovskiy is Director of Engineering leading Service Engineering Group in Supply Side Platform (SSP) at Verizon Media. He has over 15 years of experience designing and building software systems. In the past six years, Lev spent time designing, developing, and running large-scale reporting and data processing software both in private Data Centers and in the public Cloud. He can be be contacted via LinkedIn.
 Zilvinas Shaltys is Technical Lead for the Video Syndication cloud data warehouse platform at Verizon. Zilvinas has years of experience working with a wide variety of big data technologies deployed at considerable scale. He was responsible for migrating big data pipelines from AOL data centers to Amazon EMR. Zilvinas is currently working on improving stability and scalability of existing batch and realtime big data systems. He can be contacted via LinkedIn.
Zilvinas Shaltys is Technical Lead for the Video Syndication cloud data warehouse platform at Verizon. Zilvinas has years of experience working with a wide variety of big data technologies deployed at considerable scale. He was responsible for migrating big data pipelines from AOL data centers to Amazon EMR. Zilvinas is currently working on improving stability and scalability of existing batch and realtime big data systems. He can be contacted via LinkedIn.