亚马逊AWS官方博客
规划 Amazon EKS 从 1.32 升级到 1.35:关键变更识别与逐版本实施路径
摘要:Amazon EKS 不支持跨多个版本直接升级,且有时 Kubernetes 版本之间都伴随一系列废弃 API、运行时变更和节点 OS 调整。本文以一个真实集群从 EKS 1.32 升级到 1.35 为例,介绍如何对集群中的自管理组件和托管组件做风险分级评估、识别 cgroup v1、containerd、Ingress NGINX 等关键变更带来的影响,并给出一套可复制的逐版本升级路径,帮助企业以最小风险完成跨多个 Kubernetes 大版本的升级。
目录
一、引言
Amazon Elastic Kubernetes Service(Amazon EKS) 是 AWS 提供的托管 Kubernetes 服务,每年会跟随上游 Kubernetes 社区发布 3–4 个新版本,并对每个版本提供约 14 个月的标准支持期。这意味着即便业务负载完全稳定,集群本身也需要按照固定节奏滚动升级,否则将逐步进入扩展支持(Extended Support)并产生额外费用,长期不升级还会面临安全补丁断供的风险。
在为客户做集群升级评估时,我们发现以下痛点反复出现:
跨多个大版本一次性升级的现实需求:业务团队往往因为版本兼容性顾虑、变更窗口紧张等原因长期推迟升级,等到不得不升级时,集群已经落后 3 个甚至更多大版本。Amazon EKS 不支持跨多大版本直接升级,必须逐版本递进,这意味着一次升级窗口就要执行多次升级和验证。
自管理监控组件长期”挂着没人动”:客户集群中通常运行着 Prometheus、Thanos、node-exporter、Filebeat 等观测组件,由于”没出问题就不升级”的惯性,很多组件停留在 2020–2022 年的版本上。这些组件并不会随着 EKS 升级被自动更新,而它们的 client-go 库往往与目标 Kubernetes 版本不兼容,会在升级当天才暴露问题。
评估颗粒度模糊,业务方拍不了板:”要升级”和”评估完了再决定”之间,往往缺少一份能直接给到业务负责人的风险分级报告。如果只列一堆变更点而不给出”必须升级 / 建议升级 / 可选升级”的明确标签,最终结果常常是会议开了好几次仍然推进不下去。
本文将以一个 EKS 1.32 集群升级到 1.35 为例,介绍如何按照”路径分析 → 自管理组件风险分级 → 托管组件确认 → 重点风险项识别 → 分阶段实施”的方法完成评估,并给出一份可直接复用的升级路径模板。
二、概览
2.1 业务场景
我们以一个典型的中等规模 EKS 1.32 生产集群为例,集群上运行着以下几类工作负载:
- 业务应用容器(多个微服务)
- 自管理的可观测性栈(Prometheus、Thanos、node-exporter、prometheus-adapter、Filebeat 等)
- 自管理的扩缩容与控制器(cluster-autoscaler、aws-load-balancer-controller、NVIDIA device plugin 等)
- EKS 托管 Add-on(VPC CNI、kube-proxy、CoreDNS、EBS CSI、EFS CSI、Mountpoint for S3 CSI)
客户希望在一次升级窗口内将集群升级到 EKS 1.35,并要求在升级前明确:哪些组件必须先升级、哪些可以等、哪些组件已经停止维护需要替换、节点 OS 是否需要预先迁移到 AL2023。
2.2 方案收益
| 维度 | 收益 |
| 风险可见 | 组件按高/中/低风险三级分类,业务方一眼可读,决策成本显著下降 |
| 路径清晰 | 1.32 → 1.33 → 1.34 → 1.35 每一跳的”必做事项”明确,不会漏关键变更 |
| 节点迁移前置 | 在升级 1.34 前完成 AL2 → AL2023 的迁移,避免 1.35 因 cgroup v1 卡住 |
| 可观测组件统一翻新 | 借升级窗口把停留在 2020–2022 年的监控组件一次性升级到当前 LTS |
| 与 Well-Architected 对齐 | 与 AWS Well-Architected Framework 的卓越运营、安全性两个支柱保持一致 |
2.3 评估方法的核心思路
在我们的评估实践中,组件按”是否必须随 K8s 主版本升级”分为两类:
- EKS 托管组件:升级控制面后,EKS 会推荐与目标版本兼容的 Add-on 版本。这类组件无需提前评估”能不能跑”,只需要确认升级时机即可。
- 自管理镜像组件:由客户自己用 Helm Chart 或 manifest 部署,EKS 不会管理它们的版本,因此必须提前评估和升级。
后续章节按此分类展开。
三、升级路径与版本变更解读
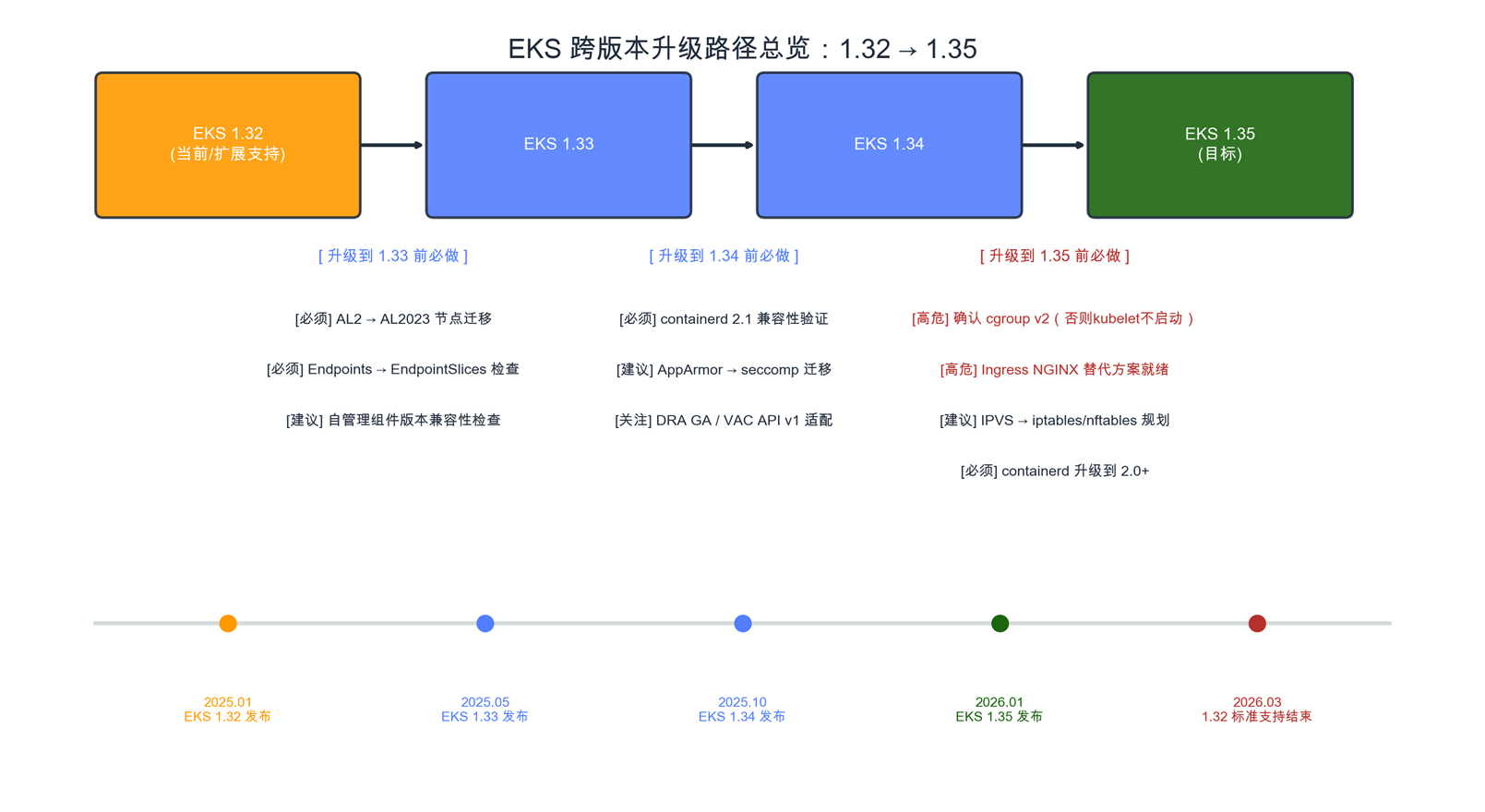
3.1 EKS 升级必须逐版本进行
Amazon EKS 不支持跨多个大版本直接升级,需要按 1.32 → 1.33 → 1.34 → 1.35 逐步升级。每次升级前需确认所有组件兼容目标版本。
[图1] |
3.2 Kubernetes 1.33 / 1.34 / 1.35 关键变更摘要
下表汇总了三个版本中对升级影响最大的”硬变更”。这些变更大多无法绕过,必须在升级前评估清楚:
| 版本 | 关键变更 |
| 1.33 | Endpoints API 正式废弃(需迁移到 EndpointSlices);Sidecar Containers GA;In-Place Pod Resize 进入 Beta |
| 1.34 | containerd 升级到 2.1;不再发布 AL2 AMI(需迁移到 AL2023);AppArmor 废弃;DRA GA;VolumeAttributesClass GA(API 从 v1beta1 → v1) |
| 1.35 | cgroup v1 支持已经弃用(kubelet 默认拒绝在 cgroup v1 节点启动);containerd 1.x 最后支持版本;Ingress NGINX 退役;--pod-infra-container-image kubelet flag 移除;IPVS 模式废弃(1.36 移除) |
从这份清单可以看出,1.34 是节点 OS 的关键拐点(AL2 停发、containerd 2.1),1.35 则是基础设施约束的拐点(cgroup v1 支持弃用、IPVS 废弃)。这两个版本的升级前置工作量明显高于 1.33。
四、自管理组件风险评估
我们将集群中所有自管理镜像组件按风险等级分为三类。决策原则是:
- 高风险:组件版本明确不兼容目标 K8s 版本,必须升级才能完成升级;
- 中风险:组件可工作但版本明显滞后,强烈建议借升级窗口一并升级;
- 低风险:兼容目标版本,可在升级后单独安排小窗口处理。
4.1 高风险 — 必须升级
| 组件 | 当前版本 | 问题 | 建议目标版本 |
| kube-state-metrics | v2.12.0 | 基于 client-go 1.30,不兼容 K8s 1.35 API。兼容矩阵显示 1.35 需要 main 分支(≥v2.18.0) | v2.18.0+ |
| Prometheus | v2.28.0 | 2021年发布,版本极老,缺少近4年的安全补丁和功能改进,可能存在与新版 K8s API 的兼容问题 | v2.55.0+(最新 LTS) |
| Thanos | v0.27.0 | 2022年发布,版本极老,需与 Prometheus 版本配套升级 | v0.36.0+ |
| node-exporter | v1.0.1 | 2020年发布,版本极老,缺少大量 metric 和安全修复 | v1.10.0+ |
| Filebeat | v7.11.2 / v7.4.2 | Elastic 7.x 已 EOL,不再获得安全更新。7.4.2 更是 2019 年版本 | v8.17.0+ 或迁移到 Fluent Bit/OpenTelemetry |
| cluster-autoscaler | v1.32.0 | 版本需与 K8s 大版本匹配,1.32 不兼容 1.35 | v1.35.x |
需要特别提醒的是 cluster-autoscaler:它的版本号需要与集群 K8s 大版本保持一致,因此每升一个 K8s 大版本就需要同步升级一次,不能跨多个版本一次到位。
4.2 中风险 — 建议升级
| 组件 | 当前版本 | 问题 | 建议目标版本 |
| prometheus-adapter | v0.12.0 | 功能可用但版本较老,建议升级以获得更好的 K8s API 兼容性 | v0.13.0+ |
| metrics-server | v0.7.1 | 可工作但最新版为 v0.8.0,包含性能改进和 bug 修复 | v0.8.0+ |
| pushgateway | v1.3.1 | 版本较老(2021年),建议升级 | v1.11.0+ |
| configmap-reload | v0.5.0 | jimmidyson 版本已不再维护,建议切换到 prometheus-operator 维护的版本 | 切换到 ghcr.io/jimmidyson/configmap-reload:v0.14.0+ 或替代方案 |
| prometheus-es-exporter | 0.14.0 | 社区维护,需验证与新版 Prometheus 兼容性 | 验证兼容性 |
4.3 低风险 — 可选升级
| 组件 | 当前版本 | 说明 | 建议 |
| aws-load-balancer-controller | v2.10.1 | 支持 K8s 1.22+,兼容 1.35,但建议升级到最新版获取 bug 修复 | 升级到最新版 |
| NVIDIA device plugin | v0.17.1 | 需验证与 K8s 1.35 DRA GA 的兼容性,建议升级 | 升级到最新版 |
| kubelet-stats-exporter | 0.0.3 | 小众组件,需验证兼容性 | 验证或考虑替代方案 |
五、EKS 托管组件评估
托管组件(EKS Add-on)由 EKS 自动管理,升级集群时会自动更新到兼容版本,但建议提前确认目标版本及对工作负载的潜在影响:
| 组件 | 当前版本 | 1.35 兼容性 | 建议 |
| Amazon VPC CNI | v1.19.3-eksbuild.1 | EKS 会自动提供兼容版本 | 升级集群后更新到最新 eksbuild |
| kube-proxy | v1.32.0-eksbuild.2 | 需随集群版本升级 | 随集群逐步升级到 v1.35.x |
| CoreDNS | v1.11.4-eksbuild.2 | 兼容 | 升级到 EKS 推荐版本 |
| Amazon EBS CSI | v1.40.1-eksbuild.1 | 注意 VolumeAttributesClass API 从 v1beta1 → v1(1.34) | 升级后验证 VAC 功能 |
| Amazon EFS CSI | v2.1.6-eksbuild.1 | 兼容 | 升级到最新 eksbuild |
| Mountpoint for S3 CSI | v1.13.0-eksbuild.1 | 兼容 | 升级到最新 eksbuild |
托管组件的升级建议不要”一把梭”:升级控制面后再单独执行 Add-on 升级,以便在出现问题时能够快速回滚单个 Add-on。
六、重点风险项深度解析
下面五项变更是这次跨版本升级中最容易”踩雷”的地方,建议在升级 Runbook 中单独列出 checklist。
6.1 ⚠️ cgroup v1 支持弃用(1.35)
- K8s 1.35 kubelet 默认拒绝在 cgroup v1 节点启动
- 检查项:确认所有节点使用 cgroup v2(AL2023 默认使用 v2)
- 如果仍在使用 AL2,须从 1.33 版本起迁移到 AL2023
这是本次升级中唯一会导致 kubelet 直接拒绝启动的变更,影响最大。如果在 1.34 阶段没有完成 AL2 → AL2023 的迁移,到了 1.35 滚动节点时会看到节点起不来,且无法通过简单回滚解决。
6.2 ⚠️ containerd 版本
- 1.34 将 containerd 升级到 2.1
- 1.35 是最后支持 containerd 1.x 的版本
- 检查项:确认容器运行时兼容性
虽然 containerd 1.x → 2.1 在大多数业务场景下兼容,但如果你有自定义 OCI hook、私有 registry mirror 配置或依赖特定 cgroup driver 行为,建议在测试环境先验证。
6.3 ⚠️ Ingress NGINX 退役
- 上游 Kubernetes 项目已于 2026年3月退役 Ingress NGINX
- 检查项:如使用 Ingress NGINX,需规划迁移到 Gateway API 或其他 Ingress Controller
注意区分社区维护的 ingress-nginx和NGINX 公司维护的 NGINX Ingress Controller,本次退役指的是前者。可选迁移路径包括 Gateway API(社区主推)、AWS Load Balancer Controller(结合 ALB)以及 NGINX 公司商业版。
6.4 ⚠️ Endpoints API 废弃(1.33)
- 访问 Endpoints API 会返回 warning
- 检查项:确认是否有组件依赖旧的 Endpoints API,迁移到 EndpointSlices
可以通过 audit log 或 kubectl get --raw=/metrics 查看是否有组件仍在调用 Endpoints API,重点检查老版本的 Service Mesh、ExternalDNS 等组件。
6.5 ⚠️ IPVS 模式废弃(1.35)
- kube-proxy IPVS 模式在 1.35 废弃,1.36 移除
- 检查项:如使用 IPVS 模式,需规划迁移到 iptables 或 nftables 模式
如果集群规模在数千 Pod 以下,从 IPVS 切回 iptables 通常无感;规模更大的集群建议直接切到 nftables 模式以获得更好的性能。
七、推荐升级实施路径
将前面所有评估项整合,可以得到以下 4 个阶段的升级实施路径。每个阶段都遵循”先升级控制面 → 再升级 Add-on → 再滚节点 → 再做工作负载验证”的顺序。
实践中我们建议把”阶段 1:升级前准备”作为一个完全独立的窗口来执行,例如先用 1–2 周时间把所有自管理组件升级完毕,把 AL2 节点替换成 AL2023,确认稳定运行后再进入阶段 2 的 K8s 升级。这样做的好处是:当任何一个版本升级阶段出现问题时,组件不再是变量,排查路径会大幅简化。
八、常见问题
Q1:可以跳过中间版本吗?比如直接从 1.32 升级到 1.35?
不可以。Amazon EKS 控制面只接受逐版本升级,必须按 1.32 → 1.33 → 1.34 → 1.35 顺序进行。如果有缩短窗口的诉求,可以考虑同一天连续完成多个版本的升级,但每一步的 Add-on 升级和验证都不能省。
Q2:自管理组件可以等到升级当天再处理吗?
不建议。如 Prometheus、Thanos、node-exporter 这些组件如果版本严重滞后,升级 K8s 时可能直接出现指标采集中断、Pod 无法注册等问题,且这些问题排查链路长(涉及 client-go 版本、CRD 版本、API server 版本)。建议在阶段 1 中独立完成。
Q3:cluster-autoscaler 是不是只在最后升一次到 1.35 就行?
最佳实践是每升一个 K8s 大版本就同步升级一次 cluster-autoscaler。例如控制面升级到 1.33 时,cluster-autoscaler 也升级到 1.33.x;控制面升级到 1.34 时,cluster-autoscaler 升级到 1.34.x。这样可以避免版本错配导致扩缩容异常。
Q4:如果业务还在使用 Ingress NGINX,是否必须在这次升级中完成迁移?
不一定要在 K8s 升级窗口内完成,但需要明确”已知风险并已制定迁移计划”。Ingress NGINX 项目退役后仍可继续运行,但不再获得安全补丁,长期运行存在合规风险。可以在 K8s 升级稳定之后,单独安排迁移到 Gateway API 或 AWS Load Balancer Controller 的窗口。
Q5:升级失败如何回滚?
EKS 控制面升级不支持就地回滚。如果升级后发现严重问题,标准做法是:① 保留旧版本节点组不动,新节点组用旧版本 AMI 继续承载流量;② 通过 Amazon EKS 集群快照工具 备份的 manifest 在另一个集群恢复。因此升级前的备份和验证集群是必备项。
九、总结
本文以一次真实的 EKS 1.32 → 1.35 升级评估为例,呈现了一种可复用的方法论:先做版本路径分析、再用三级风险标签对自管理组件做分类、然后单独识别”硬变更”风险、最后形成分阶段实施路径。
汇总本次评估涉及的组件数量:
| 类别 | 数量 |
| 必须升级(高风险) | 6 个组件 |
| 建议升级(中风险) | 5 个组件 |
| 可选升级(低风险) | 3 个组件 |
| 托管组件(自动处理) | 6 个组件 |
整体评估:从 1.32 升级到 1.35 跨越 3 个大版本,涉及多项重大变更(cgroup v1 弃用、containerd 升级、AL2 EOL、API 废弃等)。当前集群中多个监控组件(Prometheus、Thanos、Filebeat、node-exporter)版本严重滞后,即使不升级 K8s 版本也建议尽快更新以获得安全补丁。
建议预留 2-3 周时间进行组件升级和测试,在非生产环境完成全链路验证后再升级生产集群。
适用场景:
- 长期未升级、跨多个 K8s 大版本需要追赶的 EKS 集群
- 自管理可观测性组件较多的 EKS 集群
- 仍在使用 AL2 节点、需要平滑迁移到 AL2023 的集群
- 即将面临 EKS 标准支持期结束、希望避免进入扩展支持的集群
➡️ 下一步行动:
相关产品:
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon VPC — 隔离云网络
- Amazon EBS — 高性能数据块存储
- Amazon EFS — 弹性文件存储
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
相关文章:
- 告别 Ingress-NGINX:用 Amazon Load Balancer Controller Gateway API 实现更强大的流量管理
- 增强Amazon EKS 节点自愈方案:基于 NPD 的故障持久化与安全修复探索
十、下一步:让 AI Agent 帮你跑这套流程
本文给出的方法论(5 维度评分、风险三级分类、4 阶段升级路径)已经能让一个熟练 SRE 在数小时内完成评估和升级。但如果你的团队人手有限、运维知识需要跨多个项目复用,下一步是把这套方法论从”人工执行”升级到”AI Agent 自主执行”——把方法论封装成机器可读的 Skill 知识库,让 Agent 在升级时主动加载并按内置 workflow 执行。
我们在另一篇博客《AI 时代的 EKS 升级范式:用 Kiro-cli 让 Agent 接管识别、升级与排障》中详细介绍这套方案。在那篇文章里,我们做了一个特别的对照实验——同一集群、同一组件清单、同一 AI 工具链(kiro-cli + aws-mcp),唯一变量是是否加载 Skill:
| 维度 | Record 1:Agent 无 Skill(agent 跑命令,工程师人工排错) | Record 2:Agent + Skill v1.0(agent 自主按 workflow 执行) | 差距 |
| 同一集群 1.32 → 1.35 升级总耗时 | 约 6 小时 | 约 2.5 小时 | 节省 60% |
| 风险识别耗时 | 30–60 分钟 | 30 秒 | 60–120× |
| 已知坑诊断耗时 | 80 分钟/坑 | 0 分钟(Skill 已编码自动避开) | ∞ |
| 未知坑诊断耗时 | 80 分钟(agent 乱试 + 工程师 Google) | 30 分钟(agent 套用 SSM 5 步法) | 2.7× |
> 关键洞察:上表数据两组都是 AI Agent 完成的——Record 1 不是”传统手工”,而是”Agent 跑命令但工程师必须实时介入诊断”;差距来源于有没有加载 Skill。换句话说,让运维效率产生 10 倍提升的不是 AI 工具本身,而是 Skill 知识库。Agent 工具只把命令自动化,Skill 才让 agent 在专业领域产生差异化能力。
Skill 是会成长的资产。第二篇文章中我们公开了 Skill 知识库的完整结构、Agent 配置文件示例,以及在真实集群上踩到的全新隐性约束(vpc-cni v1.21+ 节点 IAM 权限 bug)如何被 Agent 自动诊断并反哺回 Skill v1.0 → v1.1 的演进过程。
如果你正在做以下任一件事,第二篇是值得阅读的延伸:
- 团队 SRE 经验参差不齐,希望降低对个人 know-how 的依赖
- 跨多个集群、多种维护任务,希望把运维知识标准化复用
- 已经在用 AI Agent,但发现 agent 在专业领域”没经验、要带教”——想让 agent 真正变专业
- 探索 AI Agent 在云运维中的落地路径
十一、参考资源
- Amazon EKS 集群版本与生命周期
- Amazon EKS 升级集群的最佳实践
- Amazon EKS Cluster Insights — 升级前的诊断工具
- Amazon EKS Add-on 版本兼容性
- Amazon Linux 2023 on Amazon EKS
- Kubernetes Deprecated API Migration Guide
- Kubernetes 1.33 / 1.34 / 1.35 Release Notes
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
