亚马逊AWS官方博客
Amazon Kinesis 更新& Amazon Elasticsearch Service 集成,分片级指标和基于时间的迭代器
Amazon Kinesis 让您在云中轻松实现流数据处理。Amazon Kinesis 平台由三种不同的服务组成:Kinesis Streams 允许开发人员构建自己的流处理应用程序;Kinesis Firehose 简化了将流数据加载到 AWS 以进行存储和分析的过程;Kinesis Analytics 支持分析人员使用标准 SQL 查询分析流数据。许多 AWS 客户使用Kinesis Streams 和Kinesis Firehose 作为实时流数据提取和处理系统的组件。他们能感受到托管服务带来的易用性,并将开发时间投入到应用程序中,而不是花时间管理自己的流数据基础设施。
他们感受完全托管服务带来的易用性,并将开发时间投入到应用程序中,而不是花时间管理自己的流数据基础设施。
今天我们宣布了 Amazon Kinesis Streams 和 Amazon Kinesis Firehose 的三个新功能:
- 与Elasticsearch 集成 – Amazon Kinesis Firehose 现在可以将数据流传输到 Amazon Elasticsearch Service 集群。
- 增强的指标 – Amazon Kinesis 现在可以每分钟向 CloudWatch 发送分片级指标。
- 灵活性 – Amazon Kinesis 现在允许您使用基于时间的分片迭代器检索记录。
与Amazon Elasticsearch Service 集成
Elasticsearch 是一个流行的开源搜索和分析引擎。Amazon Elasticsearch Service 是一项托管服务,让您可以在 AWS 云中轻松地部署、运行和扩展 Elasticsearch。您现在可以将 Kinesis Firehose 数据流传输到 Amazon Elasticsearch 集群索引和分析服务器日志、点击流和社交媒体流量。
传入的记录(Elasticsearch 文档)将根据您指定的配置在 Kinesis Firehose 中缓存,然后自动添加到集群并批量索引多个文档。在将数据发送到 Firehose 之前,数据必须已进行 UTF-8 编码并合并为单个 JSON 对象(请参阅我最近的博文,Amazon Kinesis 代理更新 – 新数据预处理功能,以了解有关如何执行此操作的更多信息)。
以下是如何使用 AWS 管理控制台进行设置的方法。选择目标 (Amazon Elasticsearch Service) 并设置传输流名称,然后选择一个 Elasticsearch 域 (本示例中为livedata),设置索引,并选择索引轮换 (无、每小时、每天、每周或每月)。同时指定一个 S3 存储桶,它将接收所有文档或失败文档的备份 (供参考):
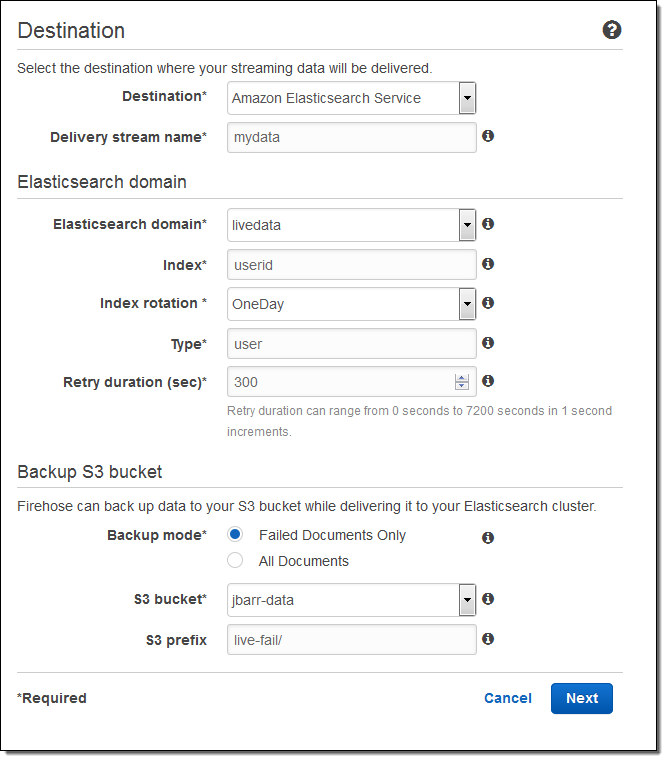
然后设置缓冲区大小,为将要发送到 S3 存储桶的数据选择一些压缩和加密选项,设置日志记录 (如果有需要),并选择适当的 IAM 角色:
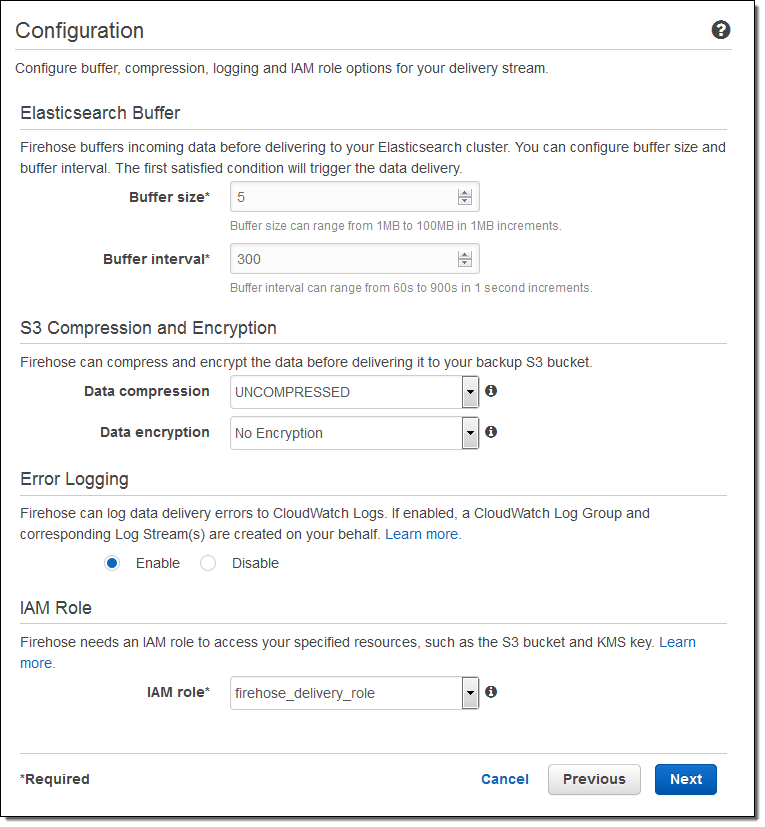
流将在一分钟左右准备就绪:
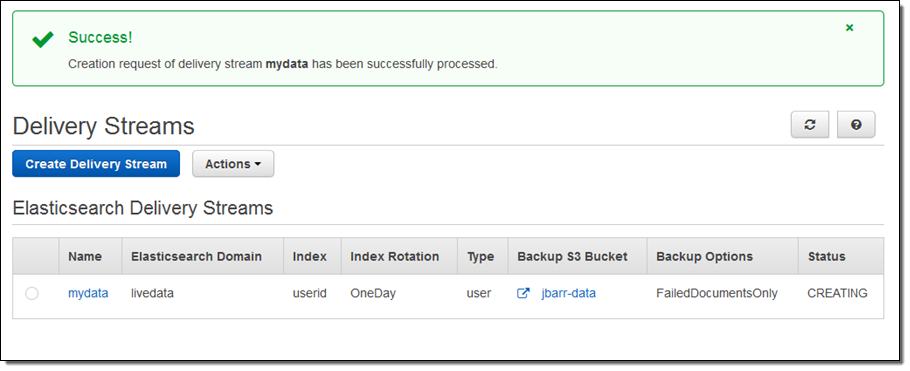
然后就可以在控制台中查看传输指标:
一旦数据开始到达 Elasticsearch,就可以使用 Kibana 或使用 Elasticsearch 查询语言来可视化查询数据。
综上所述,这种集成大大简化了捕获流数据并将其传输到 Elasticsearch 集群的过程。无需编写任何代码或构建自己的数据提取工具就可以实现。
分片级指标
每个 Kinesis 流由一个或多个分片组成,每个分片提供固定数量的读写容量。当我们向流平台添加分片时,就会增加流平台的容量。
为了使您能够更好地了解每个分片的性能,现在可以启用一组分片级指标。每个分片有 6 个指标,每个指标每分钟报告一次,并按标准的 CloudWatch 定价收费。这些指标将允许您查看特定分片是否比其他分片负载更高,并查找和根除端到端流数据传输管道中的任何效率底下的情况。例如,您可以识别以过高的速率接收记录的分片,以及应用程序以低于预期的吞吐量读取的分片。
以下是新指标:
IncomingBytes – 已成功放置到分片的字节数。
IncomingRecords – 已成功放置到分片的记录数。
IteratorAgeMilliseconds – 针对一个分片调用 GetRecords 所返回的最后一条记录的年龄 (以毫秒为单位)。值为 0 表示正在读取的记录完全被流捕获。
OutgoingBytes – 从分片中检索的字节数。
OutgoingRecords – 从分片中检索的记录数。
ReadProvisionedThroughputExceeded -已超过每秒 5 次读取或每秒 2 MB 分片限制而受限的GetRecords 调用数。
WriteProvisionedThroughputExceeded – 由于超过每秒 1000 条记录或每秒 1 MB 的分片限制而被拒绝的记录数。
您可以通过调用 EnableEnhancedMonitoring 函数来启用这些指标。与以往一样,您可以使用 CloudWatch APIs 在任何所需的时间段内聚合它们。
基于时间的迭代器
您的应用程序通过使用 GetShardIterator 函数在所需分片上创建迭代器并指定所需的起始点来从 Kinesis 流中读取数据。除了现有的起始点选项 (在序列号、最旧记录或最新记录处或之后),您现在还可以指定时间戳。指定的值 (Unix 时间戳) 表示您要读取和处理的最旧记录的时间点。