亚马逊AWS官方博客
Amazon OpenSearch Service 通过 GPU 加速和自动优化提升向量数据库性能并降低成本
今天我们宣布在 Amazon OpenSearch Service 中推出无服务器 GPU 加速和向量索引自动优化功能,帮助您以更低成本快速构建大规模向量数据库,并自动优化向量索引,在搜索质量、速度与成本之间实现最佳平衡。
以下是今日发布的全新功能:
- GPU 加速:与非 GPU 加速方案相比,您能以四分之一的索引成本实现最高 10 倍的向量数据库构建速度,并在一小时内完成十亿级规模向量数据库的创建。 在显著节省成本与提速的双重优势下,您将在产品上市时间、创新速度以及大规模向量搜索应用落地方面获得竞争优势。
- 自动优化:向量专业知识,即可为您的向量字段在搜索延迟、质量和内存需求之间找到最佳平衡点。相比默认索引配置,此优化方案可助您显著节约成本,提升召回率,而手动索引调优往往需要耗费数周时间才能完成。
借助这些功能,您可以在 OpenSearch Service 上更快速、更经济高效地构建向量数据库。您可利用它们为生成式人工智能应用提供动力,搜索产品目录与知识库等。在创建新的 OpenSearch 域或集合时,您可启用 GPU 加速与自动优化功能,亦可对现有域或集合进行此类配置更新。
让我们来看看它的工作原理!
向量索引的 GPU 加速
您在 OpenSearch Service 域或无服务器集合上启用 GPU 加速后,OpenSearch Service 会自动识别加速向量索引工作负载的机会。这种加速有助于在 OpenSearch Service 域或无服务器集合中构建向量数据结构。
您无需预置 GPU 实例、管理其使用量或为闲置时间付费。OpenSearch Service 将您的加速工作负载安全地隔离到您账户内域或集合的 Amazon Virtual Private Cloud(Amazon VPC)中。您仅需为通过 OpenSearch 单位(OCU)– 向量加速定价模式产生的有效处理量付费。
要启用 GPU 加速,请访问 OpenSearch Service 控制台,在创建或更新 OpenSearch Service 域或无服务器集合时,在高级功能部分中选择启用 GPU 加速。
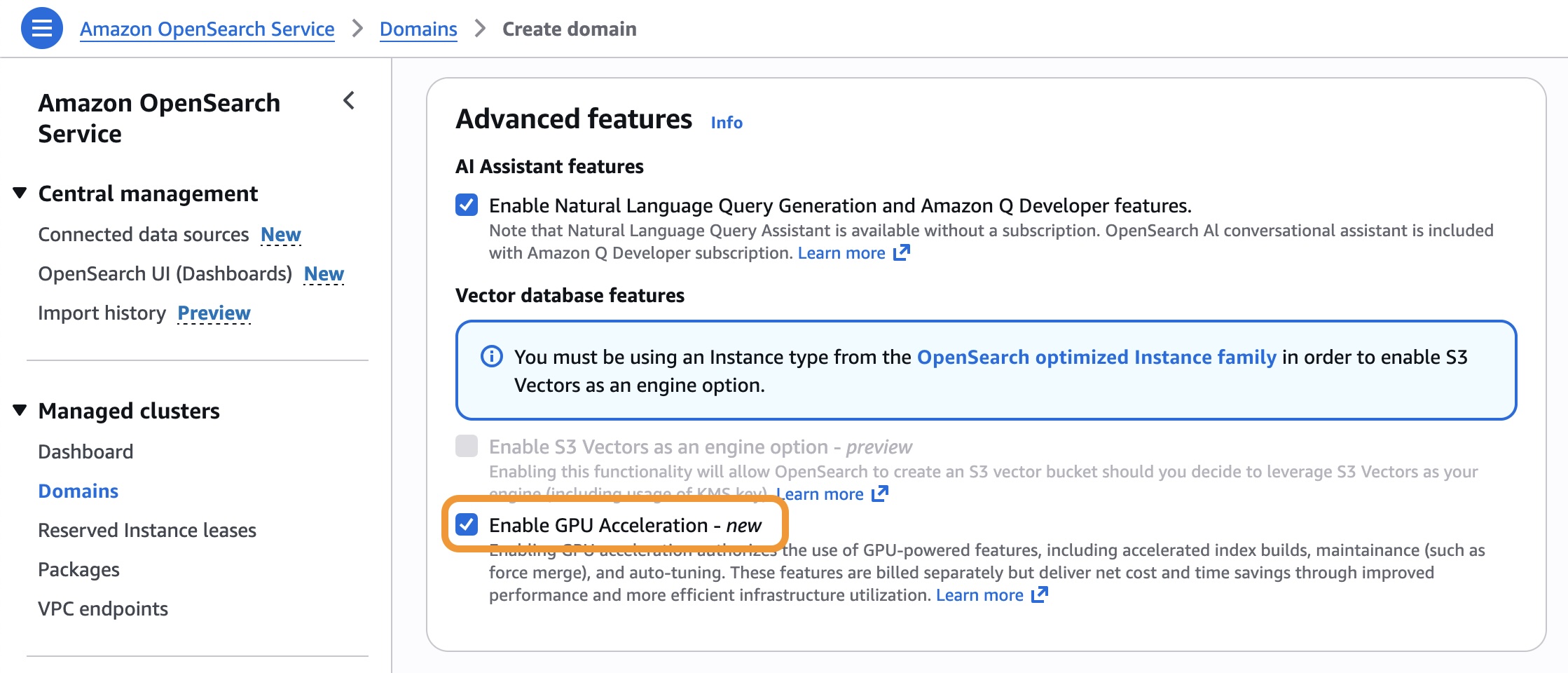
您可以使用以下 AWS 命令行界面(AWS CLI)命令为现有 OpenSearch Service 域启用 GPU 加速。
$ aws opensearch update-domain-config \
--domain-name my-domain \
--aiml-options '{"ServerlessVectorAcceleration": {"Enabled": true}}'
您可以创建针对 GPU 处理优化的向量索引。此示例索引通过启用 index.knn.remote_index_build.enabled 来存储用于文本嵌入的 768 维向量。
PUT my-vector-index
{
"settings": {
"index.knn": true,
"index.knn.remote_index_build.enabled": true
},
"mappings": {
"properties": {
"vector_field": {
"type": "knn_vector",
"dimension": 768,
},
"text": {
"type": "text"
}
}
}
}现在,您可以使用批量 API 使用标准 OpenSearch Service 操作来添加向量数据并优化索引。GPU 加速会自动应用于索引和强制合并操作。
POST my-vector-index/_bulk
{"index": {"_id": "1"}}
{"vector_field": [0.1, 0.2, 0.3, ...], "text": "Sample document 1"}
{"index": {"_id": "2"}}
{"vector_field": [0.4, 0.5, 0.6, ...], "text": "Sample document 2"}我们进行了索引构建基准测试,观察到 GPU 加速带来的速度提升介于 6.4 到 13.8 倍之间。敬请关注后续文章,我们将带来更多基准测试与深度解析。
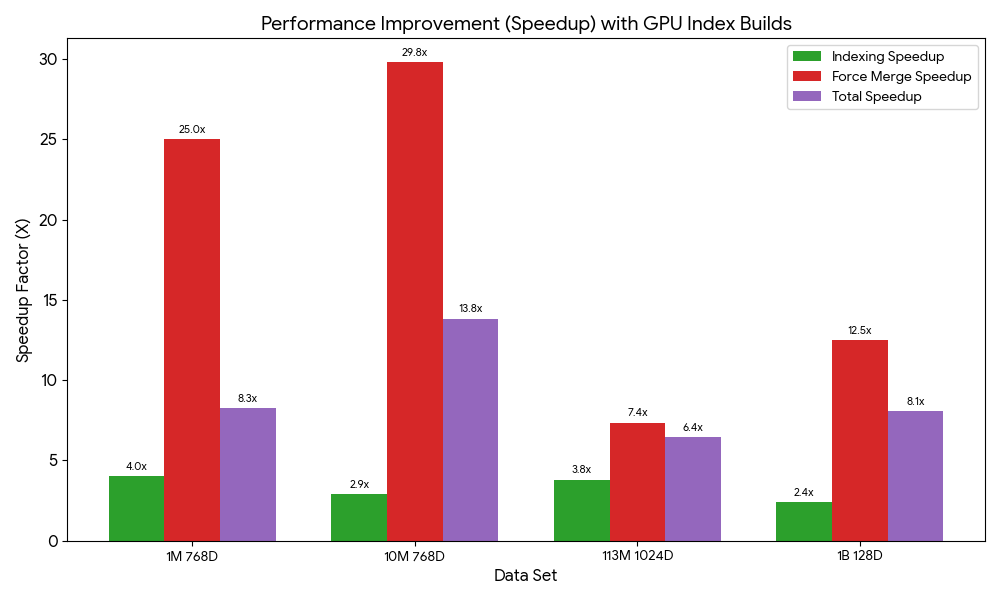
要了解更多信息,请参阅《Amazon OpenSearch Service Developer Guide》中的 GPU acceleration for vector indexing。
自动优化向量数据库
您可以使用全新向量摄取功能,从 Amazon Simple Storage Service(Amazon S3)摄取文档、生成向量嵌入、自动优化索引,并在数分钟内构建大规模向量索引。在摄取过程中,自动优化会根据您 OpenSearch Service 域或无服务器集合中的向量字段和索引生成优化建议。您可以从这些建议选项中选择一项,快速完成向量数据集的摄取与索引编制,无需手动配置映射关系。
要开始使用,请在 OpenSearch Service 控制台左侧导航窗格的摄取菜单下选择向量摄取。
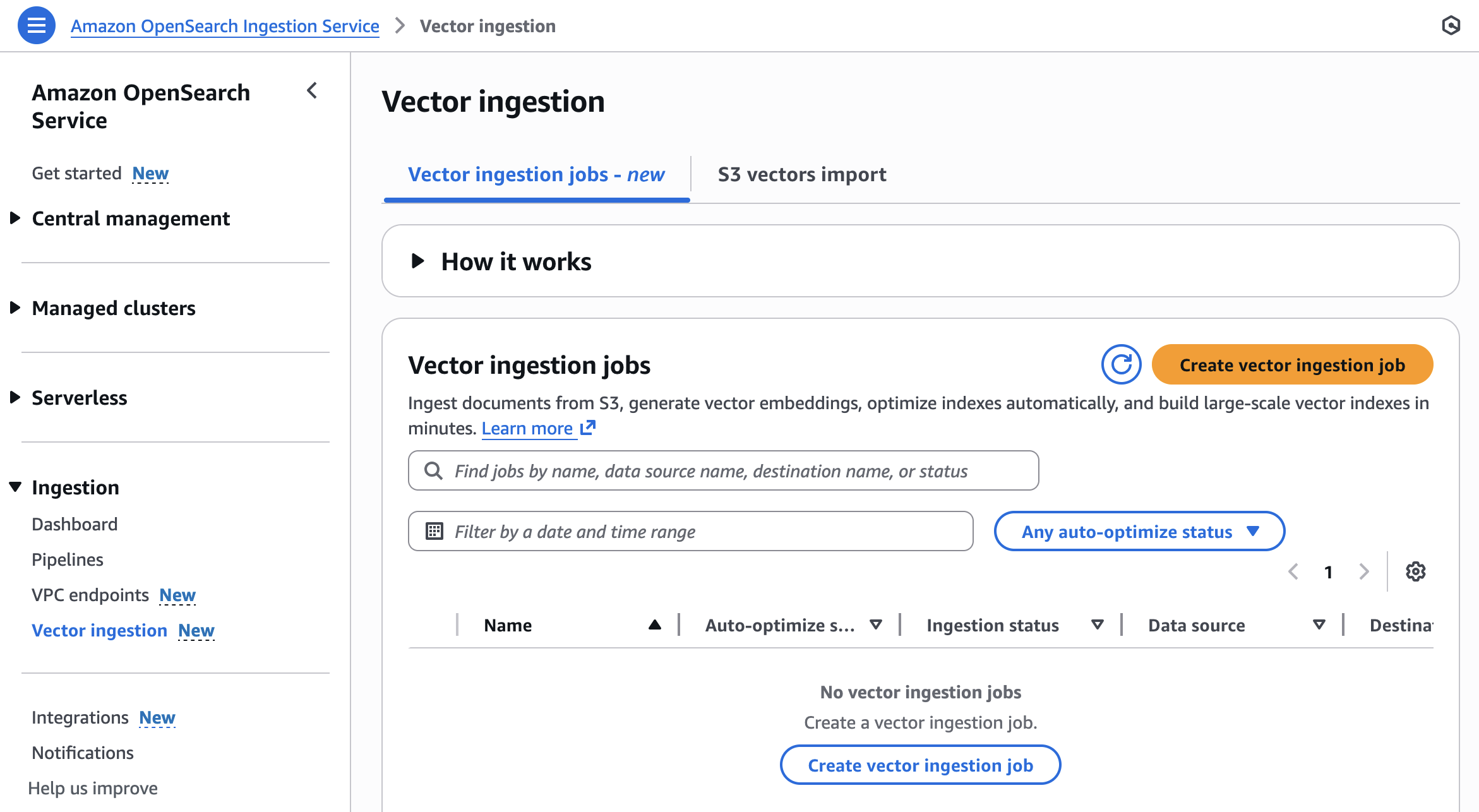
您可以按照以下步骤创建新的向量摄取任务:
- 准备数据集:在 S3 存储桶中准备 OpenSearch Service 的 parquet 文档,并为目标选择域或集合。
- 配置索引并自动优化:自动优化向量字段或手动配置向量字段。
- 摄取并加速索引:使用 OpenSearch 摄取管道将数据从 Amazon S3 加载到 OpenSearch Service。以四分之一的成本,高达 10 倍的速度构建大规模向量索引。
在步骤 2 中,配置具有自动优化向量字段的向量索引。自动优化目前仅限于一个向量字段。自动优化任务完成后,可以继续输入其他索引映射。
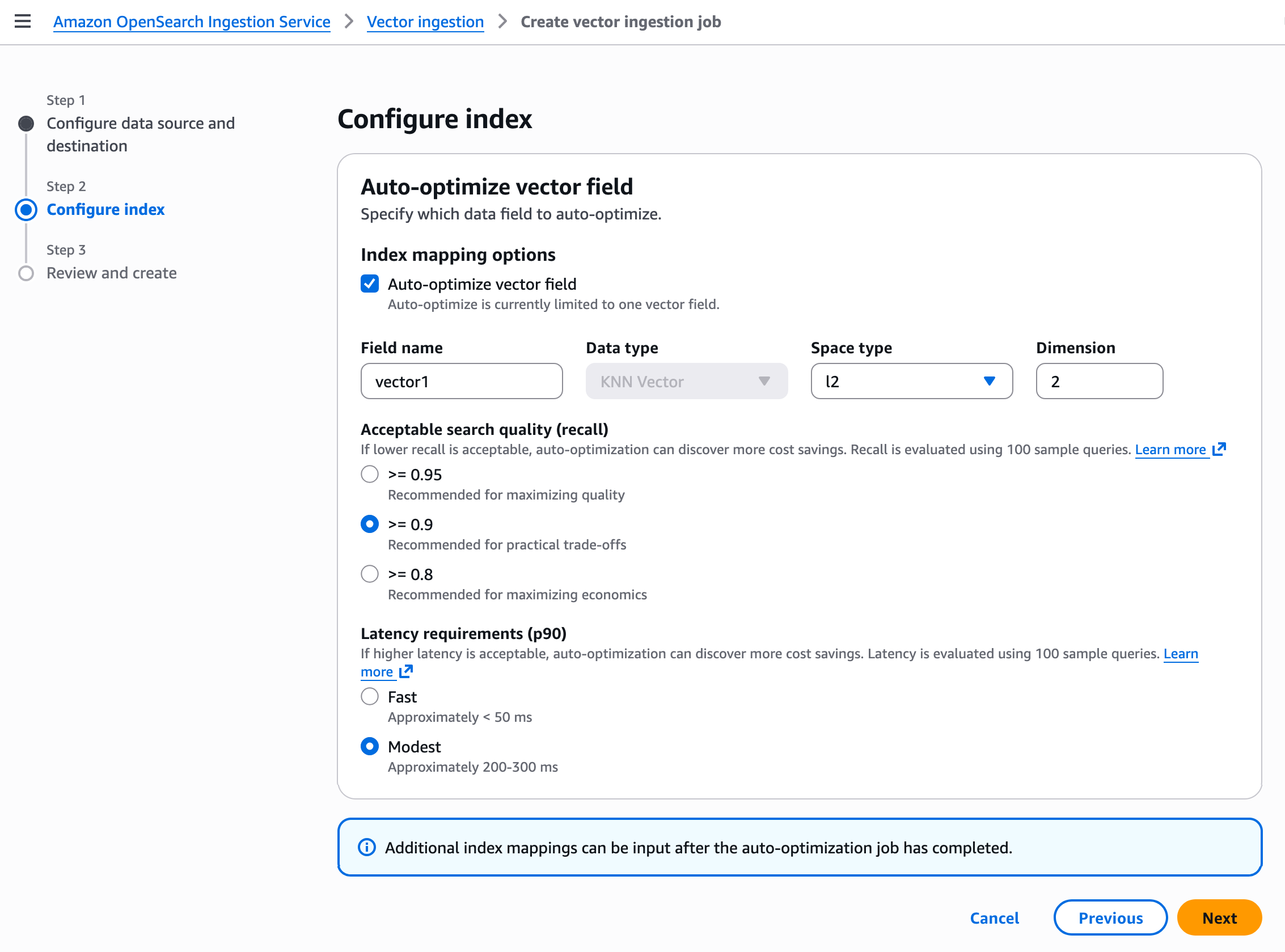
您的向量字段优化设置取决于具体使用案例。例如,若您需要较高的搜索质量(召回率)且对响应速度无严格要求,则可将延迟要求(p90)设为适中,并将可接受的搜索质量(召回率)设置为大于或等于 0.9。创建任务后,系统将开始摄取向量数据并自动优化向量索引。处理时间取决于向量维度。
要了解更多信息,请参阅《OpenSearch Service Developer Guide》中的 Auto-optimize vector index。
现已推出
Amazon OpenSearch Service 的 GPU 加速功能现已在美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(悉尼)、亚太地区(东京)和欧洲地区(爱尔兰)区域推出。OpenSearch Service 的自动优化功能现已在美国东部(俄亥俄州)、美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(孟买)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、欧洲地区(法兰克福)、欧洲地区(爱尔兰)区域推出。
OpenSearch Service 对使用的 OCU(向量加速)单独计费,仅用于为您的向量数据库编制索引。要了解更多信息,请访问 OpenSearch Service 定价页面。
立即试用,并将反馈发送至 AWS re:Post for Amazon OpenSearch Service 或通过您常用的 AWS Support 联系人发送反馈。
– Channy