亚马逊AWS官方博客
向量存储成本降低 85%:用 Amazon S3 Vectors 构建企业级多平台统一知识库
摘要:本文将介绍一个基于 AWS 云原生服务的统一知识库架构方案,重点阐述如何通过 Amazon S3 Vectors 实现显著的成本节约,以及如何通过 Provider 模式扩展支持多个 SaaS 平台,构建真正的企业级统一知识库。
1. 引言
在数字化转型的浪潮中,企业的知识资产分散在 Google Drive、SharePoint、Confluence、Dropbox、Notion 等多个 SaaS 平台。这种碎片化的知识管理方式不仅降低了信息检索效率,也阻碍了企业知识的沉淀和复用。
根据 IDC 的《数据年龄报告》(2023 年)研究,员工平均每天花费 1.8 小时搜索和整理信息,其中约 44% 的搜索无法快速找到所需内容。* 这一统计来自对全球数千家企业的调查,反映了企业知识管理的普遍挑战。
本文将介绍一个基于 AWS 云原生服务的统一知识库架构方案,重点阐述如何通过 Amazon S3 Vectors 实现显著的成本节约,以及如何通过 Provider 模式扩展支持多个 SaaS 平台,构建真正的企业级统一知识库。
2. 架构设计理念
云原生优先
方案完全基于 AWS 托管服务构建,遵循 Well-Architected Framework 的五大支柱:运营卓越、安全性、可靠性、性能效率和成本优化。通过使用 Amazon ECS Fargate、Amazon S3 Vectors、Amazon DynamoDB 和 Amazon Bedrock 等托管服务,企业无需投入资源管理底层基础设施,可以将精力集中在业务价值创造上。
服务解耦与事件驱动
架构采用微服务设计模式,将系统划分为独立的服务单元。通过 Amazon SQS 实现服务间的异步通信,确保各服务可以独立扩展和演进。这种松耦合的设计不仅提高了系统的可维护性,也为后续接入新的数据源提供了灵活性。
多模态统一处理
利用 Amazon Nova Multimodal Embeddings 模型,系统能够将文本、图片、视频等不同类型的内容映射到统一的向量空间。这意味着用户可以用文本查询图片,或用图片查找相关文档,真正实现跨模态的知识检索。
3. 核心架构组件
整体架构视图
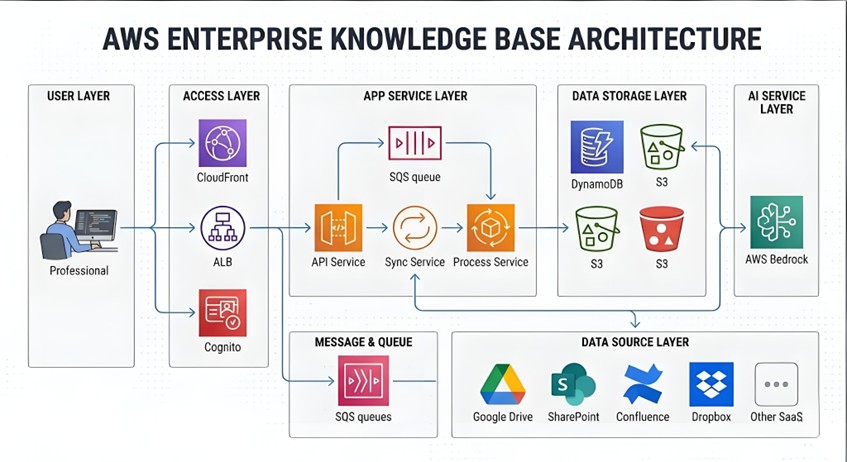 |
服务职责划分
API Service 作为系统的统一入口,处理所有来自前端的请求。它提供文档搜索、元数据查询、任务管理等 RESTful API 接口。服务运行在 ECS Fargate 上,通过 Application Load Balancer 实现负载均衡和高可用。
Sync Service 负责与各个数据源平台的集成。它定期扫描数据源的文件变更,提取文件元数据,并将处理任务发送到 SQS 队列。通过 Provider 模式设计,每个数据源实现统一的接口,使得添加新平台变得简单直接。
Process Service 从 SQS 队列消费任务,执行文档下载、内容解析、向量化等处理流程。它是系统中计算密集型的组件,可以根据队列深度自动扩展实例数量,应对突发的处理需求。
4. Amazon S3 Vectors:成本优化的关键
为什么选择 S3 Vectors
Amazon S3 Vectors 是 AWS 推出的首个云原生向量存储服务(Preview 阶段,2025 年 11 月),专为大规模向量数据设计。相比传统的向量数据库解决方案,S3 Vectors 在成本、运维和集成三个维度具有显著优势。
成本维度:S3 Vectors 采用按存储和查询量付费的模式,无需预置容量或持续运行实例。这种定价模型特别适合企业知识库场景,因为向量数据的访问模式通常是“写入一次,多次查询“,而查询频率相对可预测。
运维维度:作为完全托管服务,S3 Vectors 自动处理扩展、备份、高可用等运维工作。企业无需配置集群、管理分片、调优索引,也不需要担心容量规划和性能调优。
集成维度:S3 Vectors 与 AWS 生态深度集成,原生支持 Amazon Bedrock Knowledge Bases、Amazon SageMaker 和 Amazon OpenSearch Service。对于需要更低延迟的场景,可以将高频访问的向量导出到 OpenSearch,实现分层存储策略。
成本对比分析
以一个典型的企业知识库场景为例:存储 100 万个文档,每个文档平均生成 10 个向量块,总计 1000 万个向量,每个向量 1024 维(4 KB),每天 10,000 次搜索查询(30 天 × 10,000 = 300,000 次/月)。
成本计算假设:
- 所有价格基于 us-east-1 区域(2025 年 2 月)
- OpenSearch 采用 HA 配置(3 节点)
- 自建 Milvus/Qdrant 采用最小生产配置
- 自建方案运维成本参考:按照 1 名运维工程师 20% 时间投入(年薪 $120k)折算为 $200/月
| 方案类型 | 配置详情 | 成本项目 | 月度费用 | 总计 |
| Amazon OpenSearch Service | 3 个 r6g.xlarge.search 实例
(4 vCPU, 32 GB 内存) 存储:96 GB |
实例费用:3 × $0.302/小时 × 730 小时
存储费用:96 GB × $0.135/GB |
$662
$13 |
$675/月 |
| 自建 Milvus/Qdrant | 3 个 r6i.xlarge EC2 实例
(4 vCPU, 32 GB 内存) EBS 存储:150 GB gp3 |
实例费用:3 × $0.252/小时 × 730 小时
存储费用:150 GB × $0.08/GB 运维成本(估算):$200/月 |
$552
$12 $200 |
$764/月 |
| Amazon S3 Vectors | 存储:40 GB
查询:300,000 次/月 |
存储费用:40 GB × $2.30/GB
查询费用:300,000 × $0.00004 |
$92
$12 |
$104/月 |
成本节约分析
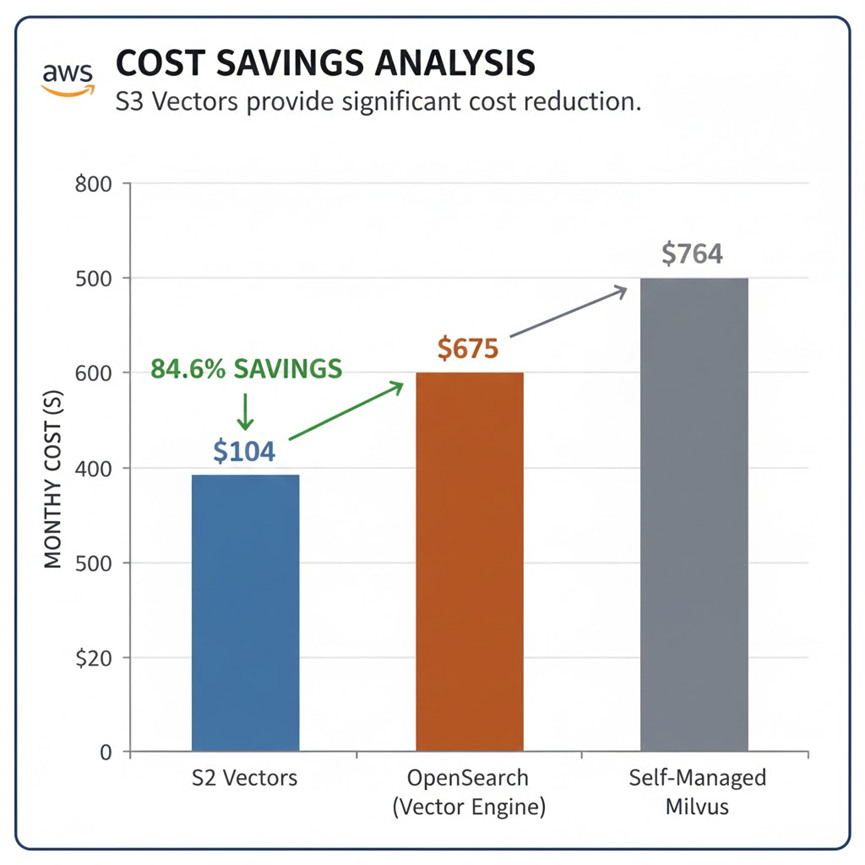 |
通过对比可以看出,S3 Vectors 方案的月度成本为 $104,相比 OpenSearch 的 $675 节省了 84.6%,相比自建 Milvus 的 $764 节省了 86.4%。
成本优势主要来自三个方面:
1. 无需持续运行实例:传统方案需要 24/7 运行计算实例以保持服务可用,即使在低峰期也要支付全额费用。S3 Vectors 只按实际存储和查询量计费,没有空闲成本。
2. 存储成本对比:虽然 S3 Vectors 的单位存储成本($2.30/GB)高于 EBS($0.08/GB),但传统方案需要额外的存储空间用于索引和备份副本。实际存储成本通常是原始数据的 3-4 倍。
3. 零运维成本:自建方案需要投入人力进行集群管理、性能调优、故障处理等工作。按照一个运维工程师 20% 的时间投入计算,月度人力成本约 $200-300。S3 Vectors 完全托管,无需任何运维投入。
进一步的成本优化策略
选择合适的向量维度:Amazon Nova Multimodal Embeddings 支持多种维度配置。* 对于大多数企业知识库场景,1024 维已经能够提供足够的检索准确率。如果对准确率要求不是特别高,使用 384 维可以将存储成本降低 62.5%,使用 256 维可以降低 75%。
*注:实际支持维度请参考 Amazon Bedrock 官方文档
实施数据生命周期管理:对于不再活跃的历史文档,可以定期清理对应的向量数据。例如,设置策略自动删除 2 年前的文档向量,或将低频访问的向量归档到成本更低的存储层。
批量处理优化:在文档处理阶段,使用批量 API 调用可以减少请求次数,合理设置批量大小可以在延迟和成本之间取得平衡。
查询缓存策略:对于常见的查询,将结果缓存在 Amazon ElastiCache 中,有效期设置为 5-10 分钟。这样可以显著减少对 S3 Vectors 的查询次数,降低查询成本。
5. Provider 模式:支持多平台统一接入
设计理念
企业的知识资产分散在多个 SaaS 平台,每个平台都有自己的 API 和认证机制。为了实现统一的知识库,系统需要能够灵活地接入新的数据源,而不影响现有功能。
Provider 模式通过定义统一的接口抽象,将不同数据源的差异封装在各自的实现中。这种设计使得添加新平台变得简单直接,只需实现标准接口即可无缝集成到系统中。
Provider 接口设计
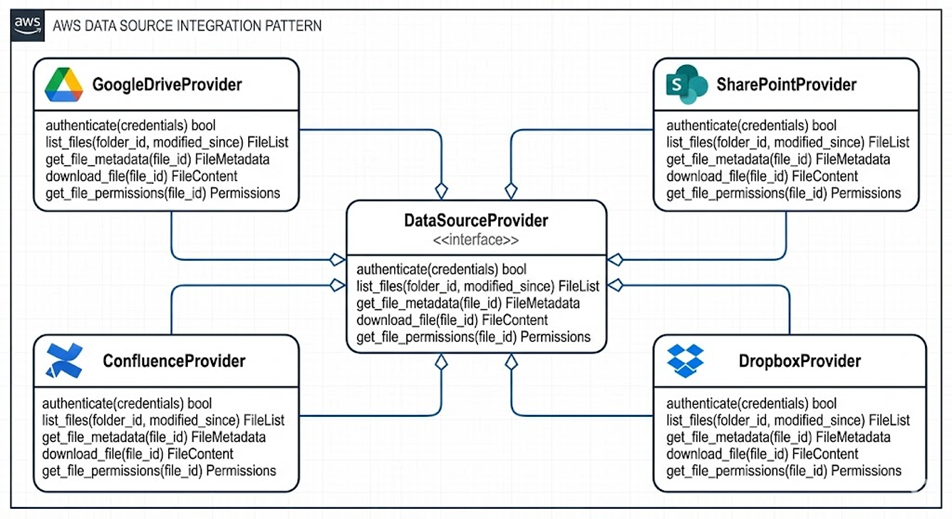 |
每个 Provider 实现五个核心方法:
- authenticate:处理平台特定的认证流程,支持 OAuth 2.0、API Key、JWT 等多种认证方式
- list_files:列出指定文件夹下的文件,支持增量同步
- get_file_metadata:获取文件的元数据
- download_file:下载文件内容
- get_file_permissions:获取文件的权限信息
多平台接入示例
Google Drive、SharePoint、Confluence、Dropbox、Notion 和 Box 等平台均可实施验证。各平台通过标准 REST API 集成,支持 OAuth 2.0 认证和增量同步。
6. 安全与合规设计
多层安全防护
架构实施端到端的安全防护机制。传输层使用 TLS 1.2+ 加密所有网络通信,CloudFront 强制 HTTPS 访问。存储层,S3 Vectors 和 DynamoDB 默认启用服务端加密,敏感凭证存储在 AWS Secrets Manager 中并支持自动轮换。
访问控制遵循最小权限原则,每个服务通过 IAM 角色获得所需的最小权限集。用户认证通过 Amazon Cognito 实现,支持 MFA 和与企业 IdP 的集成。数据访问隔离通过用户 ID 实现,确保用户只能访问自己有权限的文档。
审计与合规
系统启用 AWS CloudTrail 记录所有 API 调用,日志保留 7 年满足合规要求。应用日志通过 CloudWatch Logs 集中管理,支持实时监控和告警。对于需要满足 GDPR、HIPAA 等合规要求的企业,可以配置数据驻留策略,确保数据存储在指定的地理区域。
7. 性能与可扩展性
自动扩展机制
系统的各个组件都具备自动扩展能力。ECS Fargate 服务配置基于 CPU 和内存使用率的自动扩展策略,当负载增加时自动启动更多任务实例。SQS 队列作为缓冲层,可以平滑处理突发流量。DynamoDB 采用按需计费模式,自动适应读写负载的变化。
S3 Vectors 作为托管服务,无需配置扩展策略,自动处理大规模向量数据。
性能数据说明
根据测试数据,S3 Vectors 单次查询延迟在 200-500ms 之间,具体取决于数据规模、网络条件和查询复杂度。* 对于需要更低延迟(<100ms)的场景,建议采用分层存储策略,将热数据缓存到 Amazon OpenSearch。
8. 实施路径与最佳实践
分阶段实施策略
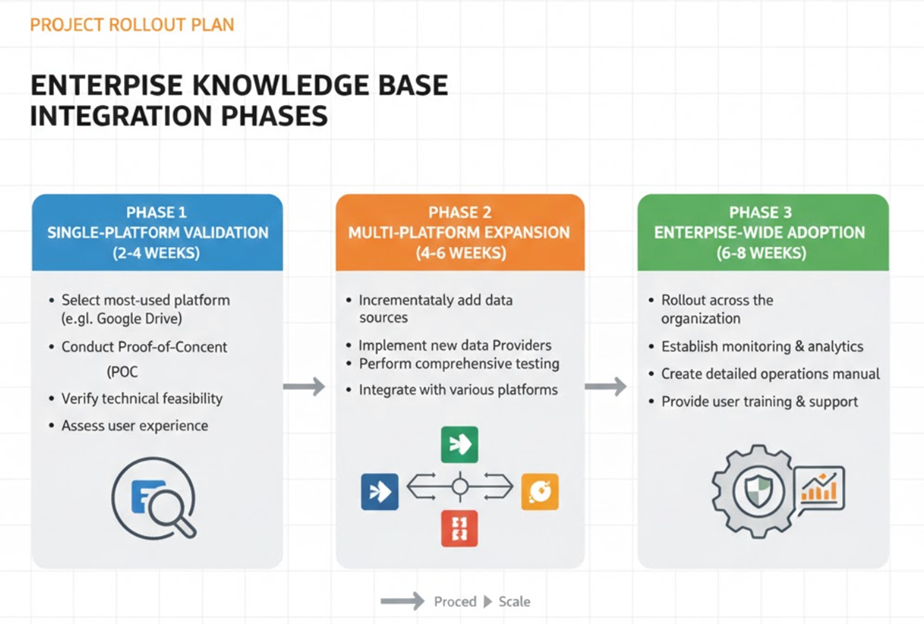 |
第一阶段:单平台验证(2-4 周) 首先选择企业使用最广泛的平台进行 POC 验证。这个阶段重点验证技术可行性和用户体验。
第二阶段:多平台扩展(4-6 周) 逐步接入其他数据源平台,实现对应的 Provider 并进行测试。
第三阶段:企业级推广(6-8 周) 在企业范围内推广,建立完善的监控体系和运维手册。
最佳实践建议
文档分块策略:根据文档类型选择合适的分块大小。对于技术文档和长文本,使用 512 tokens 的块大小,块之间重叠 50 tokens。
向量维度选择:对于企业知识库场景,推荐使用 1024 维向量,这个维度在检索准确率和存储成本之间取得了良好的平衡。
增量同步频率:根据文档的更新频率设置同步间隔。对于活跃的协作文档,可以设置为每小时同步一次。
权限继承:在同步文档时,保留原平台的权限信息,确保用户只能访问自己有权限的文档。
监控指标:重点关注文档同步成功率、向量化成功率、搜索查询延迟、搜索结果相关性和系统成本。
9. 实战用例:MCP 集成与 AI 编码助手增强
场景概述
统一知识库的最终价值,不在于“把文档存起来“,而在于让知识在工作流中随时可达。本章节以两个典型端到端场景为例,演示如何将 Amazon S3 Vectors 知识库无缝接入 AWS 开发工具链,实现开箱即用的企业智能检索。
场景一:通过 MCP 协议接入 Kiro
背景
Model Context Protocol(MCP)是 AI 工具与外部数据源之间的通用连接标准,Kiro 原生支持 MCP。通过为 Amazon S3 Vectors 构建 MCP Server,企业只需配置一次,即可让 Kiro IDE 和 Kiro CLI 共享同一份向量知识库——Build Once,Use Everywhere。
架构
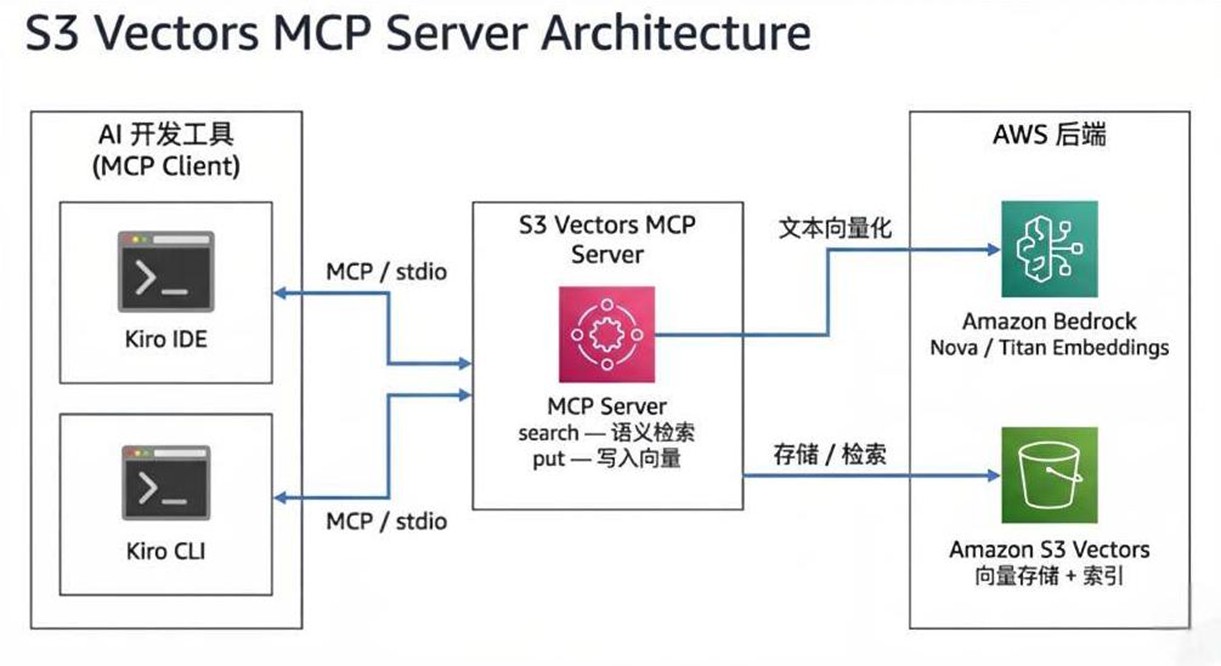 |
在 Kiro 中配置 MCP
以下演示通过开源的s3-vectors-mcp作为实现,企业可以自行构建s3 vector MCP Server。
Kiro 原生支持 MCP,在项目目录下添加 .kiro/mcp.json 即可完成接入:
JSON
{
"mcpServers": {
"s3-vectors-kb": {
"command": "uv",
"args": [
"run",
"s3-vectors-mcp",
"stdio"
],
"env": {
"S3VECTORS_BUCKET_NAME": "your-vectors-bucket",
"S3VECTORS_INDEX_NAME": "knowledge-base-index",
"S3VECTORS_MODEL_ID": "amazon.nova-2-multimodal-embeddings-v1:0",
"S3VECTORS_DIMENSIONS": "1024",
"S3VECTORS_REGION": "us-east-1"
},
"timeout": 120000
}
}
}
Kiro IDE 与 Kiro CLI 共用同一份配置,保存后自动生效,无需重启。配置完成后,Kiro Chat 面板中即可直接调用知识库检索工具。
端到端流程
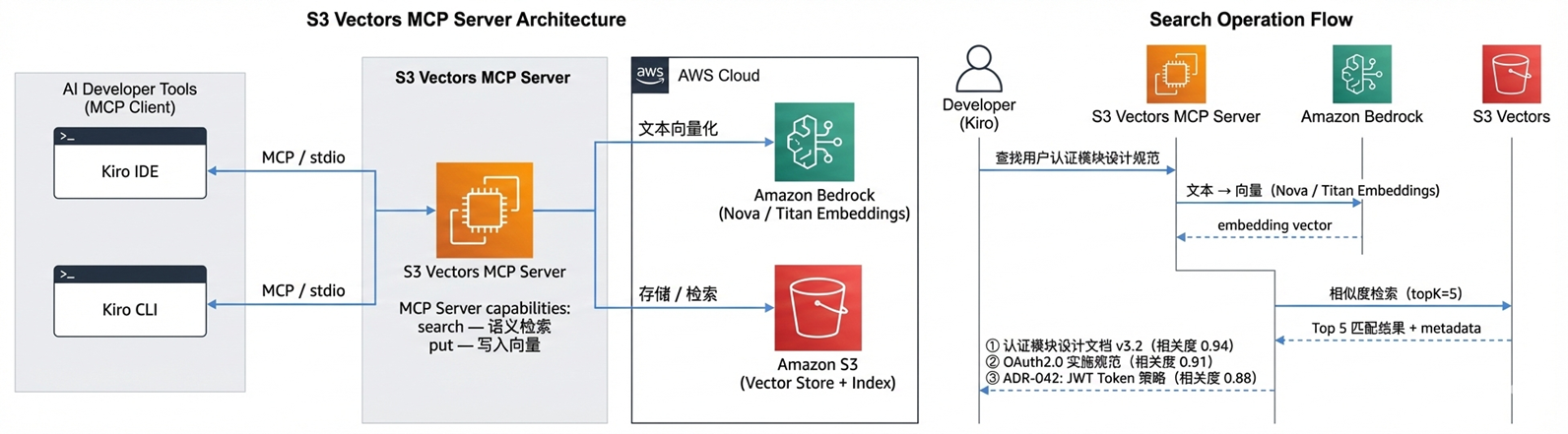 |
场景二:AI 编码助手的企业内部知识增强
背景
Kiro 的训练数据来自公开互联网,无法感知企业内部的私有规范:
- 内部 API 文档和 SDK 使用规范
- 架构决策记录(ADR)
- 编码规范与最佳实践
- 历史故障复盘和解决方案
通过将 S3 Vectors MCP Server 接入 Kiro,AI 助手可以在生成代码时实时检索这些内部知识,给出符合企业规范的建议。
步骤 1:开发者在 Kiro 中编写代码
# 开发者开始实现用户认证模块class UserAuthService:
def authenticate(self, user_id: str, token: str):
# Kiro Agent 自动触发:检测到认证相关代码pass步骤 2:Kiro 通过 MCP 检索内部规范
Kiro 的 Agent Hooks 功能在检测到特定代码模式时,自动调用 MCP 工具检索知识库:
步骤 3:返回企业内部上下文
步骤 4:AI 生成符合内部规范的代码
class UserAuthService:
def authenticate(
self,
user_id: str,
token: str,
device_id: str # ← 来自 API-DOC v2.1 的规范要求) -> AuthResult:
"""
企业认证规范 ADR-042 / SEC-007:
- Access Token 有效期:15 分钟
- 禁止在日志中记录 Token 原文
- 强制 Token 轮换
"""# 实现基于内部规范...架构对比
| 维度 | 无知识库增强 | 接入 S3 Vectors 知识库 |
| 代码规范 | 基于公开最佳实践 | 符合企业内部规范和 ADR |
| API 使用 | 可能使用过时接口 | 自动获取最新内部 API 文档 |
| 安全合规 | 通用安全建议 | 企业特定安全策略 |
| 知识时效 | 训练数据截止日期 | 实时同步(最快 1 小时内) |
| 来源可追溯 | 无明确来源 | 每条建议附带原始文档链接 |
Kiro Steering File 配置
通过 Kiro 的 Steering 文件,让 AI 在每次响应前自动检索知识库:
价值总结
通过 MCP 协议与 Kiro 的深度集成,统一知识库从“存储系统“升级为“企业智能神经系统“:
| 价值维度 | 具体体现 |
| 开发效率 | 开发者无需切换工具,在 Kiro IDE / Kiro CLI 中直接检索内部文档 |
| 代码质量 | AI 生成代码自动符合企业内部规范,减少 Code Review 返工 |
| 知识复用 | 架构决策、故障经验等隐性知识显性化,新人上手周期缩短 |
| 完全 AWS 原生 | Bedrock + S3 Vectors + Kiro,全链路 AWS 托管,无第三方向量数据库 |
| 安全合规 | IAM Role 自动鉴权,最小权限原则,敏感文档不泄露 |
10. 场景扩展与演进展望
基于 S3 Vectors 构建的统一知识库不仅是数据的终点,更是企业智能化的新起点。通过集成 RAG(检索增强生成) 技术,企业可以将海量文档转化为触手可及的智能问答系统,彻底终结在 SharePoint 或 Google Drive 中“大海捞针”的时代。无论是在法律咨询中快速索引万份判例,还是在医疗影像分析中实现精准的语义检索,这一架构都能支撑起跨平台的语义搜索需求,让分散在各处的数字资产真正实现“书同文、车同轨”,为媒体管理、电商推荐等多元场景提供高性能的向量底座。
在更深层次的应用中,系统能够利用向量相似度实现智能文档推荐,并分析引用关系来自动勾勒出企业内部的知识图谱。这种能力在受监管行业尤为关键,它能将原本繁琐的人工核对转化为自动化的合规性检查,显著降低运营风险。随着企业对内容理解要求的提高,系统不再仅仅停留在“找得到”的层面,而是开始向“读得懂”进化,通过挖掘文档间的深层逻辑,为个性化内容分发和复杂决策提供更具洞察力的支持。
展望未来,技术架构将向着更实时、更全球化且更安全的方向持续演进。我们将引入 Webhook 通知机制,将当前的定时同步升级为秒级的实时同步能力,确保知识库始终处于最新状态。同时,依托 Amazon Nova 多模态嵌入模型的语言天赋,企业可以无缝跨越多种语言的障碍,构建全球协同的知识网络。而在安全侧,通过集成 Amazon Verified Permissions,我们可以实现极其细腻的权限控制 (PBAC),确保每一条敏感信息的流动都符合企业级的安全策略与合规标准。
11. 总结
本文介绍了一个基于 AWS 云原生服务的多平台统一知识库架构方案。方案的核心价值体现在三个方面:
显著的成本优势:通过使用 Amazon S3 Vectors 作为向量存储,相比传统的向量数据库方案,成本降低 85% 以上。对于存储 1000 万向量的场景,月度成本仅为 $104,而 OpenSearch 需要 $675,自建 Milvus 需要 $764。
灵活的扩展能力:通过 Provider 模式设计,系统可以轻松接入新的 SaaS 平台。
完善的企业级特性:方案基于 AWS Well-Architected Framework 设计,在安全性、可靠性、性能和运维方面都达到了企业级标准。
➡️ 下一步行动:
相关产品:
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon S3 Vectors — 云原生向量存储服务
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Nova — 提供前沿智能和最高性价比的基础模型
相关文章:
- 使用 Bedrock 和 RAG 构建 Text2SQL 行业数据查询助手
- 基于Strands Agents SDK和Amazon Bedrock AgentCore构建商品详情图广告词审查Agent
- 完全基于 AWS 的视频内容搜索引擎 VideoSearch
- 基于无服务器架构和事件驱动的 Data Lake 数据移动
- 使用Amazon EMR Serverless Storage简化运维节省成本
12. 参考资源
- Amazon S3 Vectors 产品文档
- Amazon Bedrock 开发者指南
- Amazon Nova Multimodal Embeddings 发布博客
- AWS Well-Architected Framework
- Amazon ECS 最佳实践指南
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
