亚马逊AWS官方博客
如何为 AWS WAF 速率限制的 IP 配置固定封禁时长
摘要:通过 Serverless 方案为 AWS WAF 速率限制规则添加可配置的固定时长 IP 封禁,支持一键部署与自动解封。
目录
一、引言
本文介绍如何通过 AWS Lambda、Amazon DynamoDB 和 AWS WAF IPSet 构建一个 Serverless 方案,为 AWS WAF Rate-based Rules 触发的 IP 封禁添加可配置的固定时长。文章涵盖双通道检测架构设计、核心代码实现、一键部署步骤及成本估算。
Web 应用面临的一个常见威胁是大规模请求洪水——攻击者在短时间内向服务器发送远超正常水平的 HTTP 请求,造成响应变慢甚至服务不可用。
AWS WAF 提供了 Rate-based Rules 来应对这类场景:当某个源 IP 的请求速率超过设定阈值时,自动对其进行阻断。但这种阻断是”即时恢复”的——一旦该 IP 的请求频率回落到阈值以下,封禁通常在30秒内自动解除。这给了攻击者可乘之机:他们可以用同一批 IP 反复发起短时间的请求洪水,每次等待自动解封后再来一轮。
要打破这种循环,一个有效的策略是让封禁持续一段固定时间,而不是随请求速率自动解除。这大幅提高了攻击者反复使用同一组 IP 的难度和成本。
二、方案概览
该方案通过两个互补的通道来检测和封禁违规 IP:
- 主通道:AWS Lambda 函数每秒轮询 AWS WAF GetSampledRequests API,以近实时延迟检测被封禁的 IP。
- 备份通道:第二个 Lambda 函数处理投递到 Amazon Simple Storage Service(Amazon S3)的 WAF 日志,捕获主通道因 API 采样限制可能遗漏的 IP。
第三个 Lambda 函数每分钟运行一次,移除封禁时长已到期的 IP。运行频率可通过修改 Amazon EventBridge 调度表达式自行配置,频率越高解封越精确,但 Lambda 调用次数也相应增加。
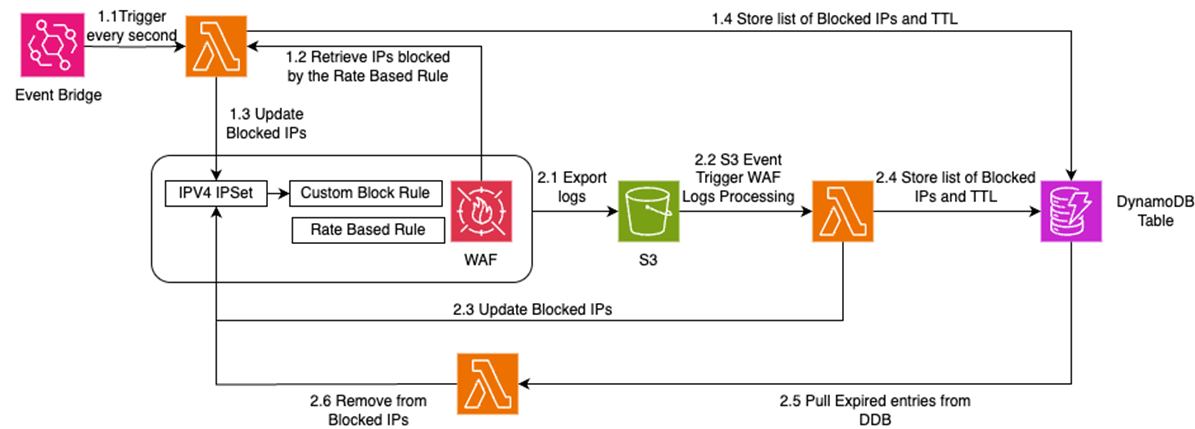
[图一:双通道检测与自动解封架构图] |
三、为什么需要双通道?
仅依赖 Amazon S3 WAF 日志存在一个关键问题:日志从 WAF 投递到 S3 通常有几分钟的延迟 (如果通过Firehose投递,延迟取决于buffer配置)。对于高频率但持续时间很短的攻击(例如几十秒内发送大量请求后立即停止),等日志到达 S3 时攻击可能已经结束,IP 也已被 WAF Rate-based Rule 自动解封。
GetSampledRequests API 弥补了这一延迟——通过查询最近数秒的采样窗口,主通道可以在攻击进行中就检测到被封禁的IP并完成固定时长封禁。
但 GetSampledRequests 是采样 API,每次最多返回 500 条请求。在极高流量下,部分被封禁的 IP 可能不出现在采样中。S3 日志作为备份通道,包含所有请求的完整记录,确保不会遗漏任何违规 IP。
两个通道各取所长:主通道保证速度,备份通道保证覆盖率。
四、架构详解
4.1 主通道:SamplerFunction
Amazon EventBridge 的最小调度间隔为 1 分钟。为实现每秒轮询,Lambda 函数在内部运行一个循环,在每次被 EventBridge 触发后持续执行约 55 秒,然后正常退出,等待下一次触发。
Lambda 函数的 Timeout 配置为 70 秒,循环运行 55 秒,两者之间留有 15 秒余量,确保循环能在超时前正常完成并退出。
4.2 备份通道:LogProcessorFunction
投递到 Amazon S3 的 WAF 日志包含所有被评估请求的完整(未采样)记录。该函数由 S3 ObjectCreated 事件触发,处理每个日志文件:
ℹ️ 注意:
对于 Rate-based Rule,规则名称出现在 terminatingRuleId 字段,而不是 ruleGroupList。Rate-based Rule 匹配时,ruleGroupList 字段为空。
4.3 解封:CleanupFunction
DynamoDB 内置的 TTL 功能可以删除过期记录,但实际删除通常在 48 小时内——不适合精确解封。因此,专用的 Lambda 函数每分钟主动移除过期 IP:
DynamoDB TTL 字段(ttl)作为安全兜底——如果 CleanupFunction 出现故障,DynamoDB 最终会自动删除记录,防止表无限增长。
4.4 通过 AWS CloudFormation Custom Resource 自动配置 WAF
该方案使用 AWS CloudFormation Custom Resource 在 stack 创建时自动配置 WAF,并在删除时清理:
- 为每个监控的规则创建 WAF IPSet
- 在 WebACL 中添加引用 IPSet 的 Block Rule
- 创建启用 TTL 的 DynamoDB 表
- Stack 删除时撤销所有变更
这意味着部署 CloudFormation stack 是唯一需要手动操作的步骤。
五、部署
5.1 前置条件 1:确认 Amazon CloudFront 已关联 AWS WAF WebACL
在 Amazon CloudFront 控制台中,打开目标 Distribution,切换到 Security 标签页,确认已关联一个 AWS WAF WebACL,并记录该 WebACL 的 ARN。
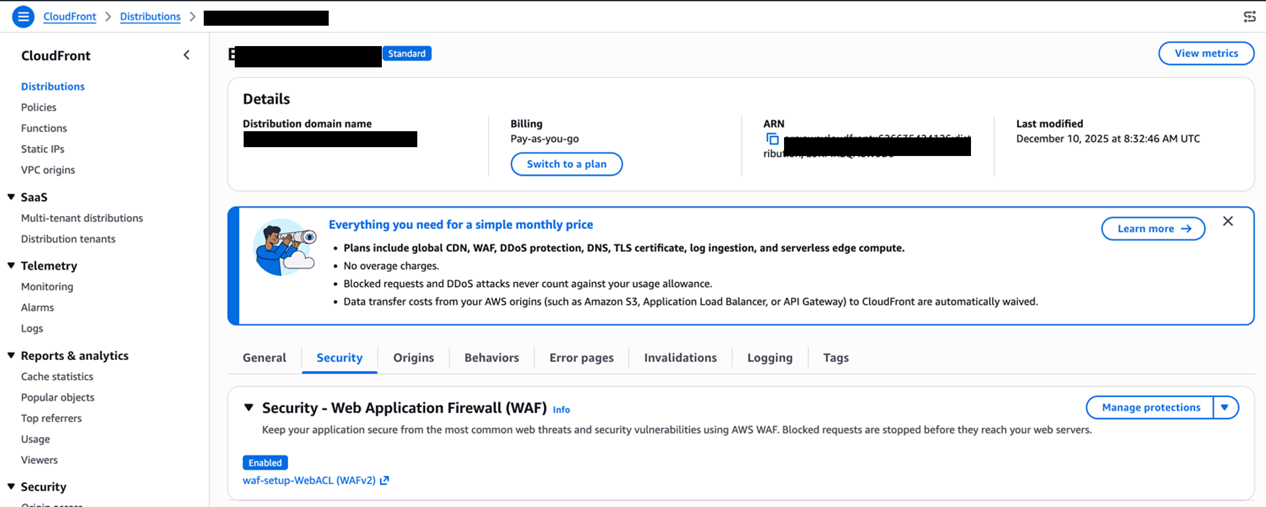
[图二:CloudFront关联WAF配置] |
5.2 前置条件 2:确认 WAF WebACL中已配置 Rate-based Rule
在 AWS WAF 控制台中,打开上一步关联的 WebACL,在 Rules 标签页中确认已有 Rate-based Rule,并记录规则名称(例如 RateLimitRule)。
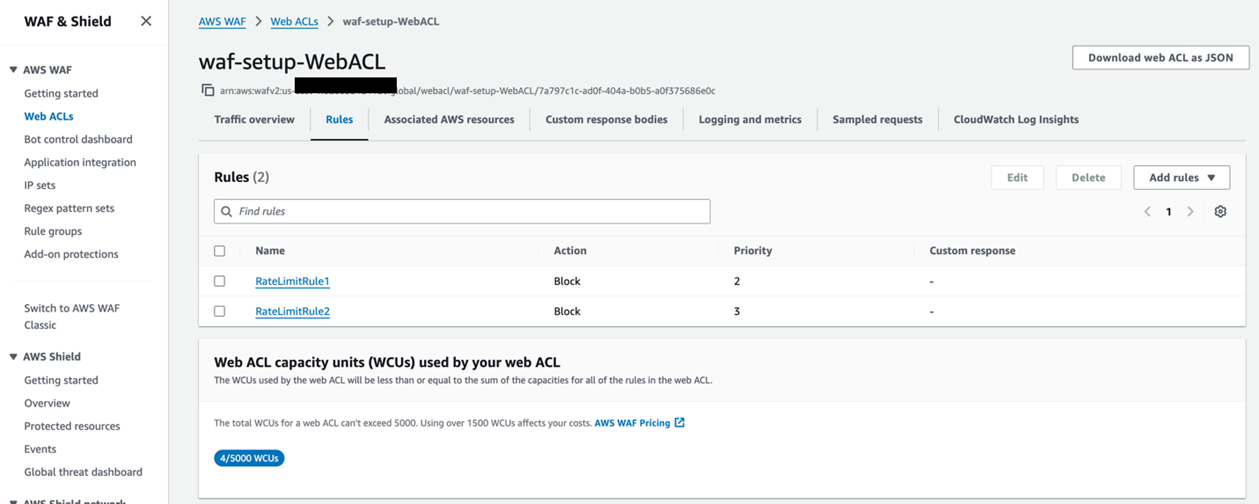
[图三:WAF速率限制规则配置] |
5.3 前置条件 3:启用WAF日志投递到Amazon S3
本方案的备份通道需要从 Amazon S3 读取 WAF 日志文件。AWS WAF 支持三种日志投递目标:Amazon CloudWatch Logs、Amazon S3 和 Amazon Data Firehose。本方案需要日志存储在 S3 中,以下两种方式均可:
- 通过 Amazon Data Firehose:在 WAF WebACL 的 Logging and metrics 标签页中,选择一个 Data Firehose stream 作为投递目标(stream 名称必须以 aws-waf-logs- 开头)。确认该 Firehose stream 的 Destination 是一个 S3 Bucket,并记录该 Bucket 的 ARN。参考文档:将 AWS WAF 日志发送到 Amazon Data Firehose
- 直接投递到 S3:选择一个 S3 Bucket 作为日志目标(Bucket 名称必须以 aws-waf-logs- 开头),记录该 Bucket 的 ARN。参考文档:将 AWS WAF 日志发送到 Amazon S3 存储桶
两种方式生成的日志文件格式相同,本方案均支持。
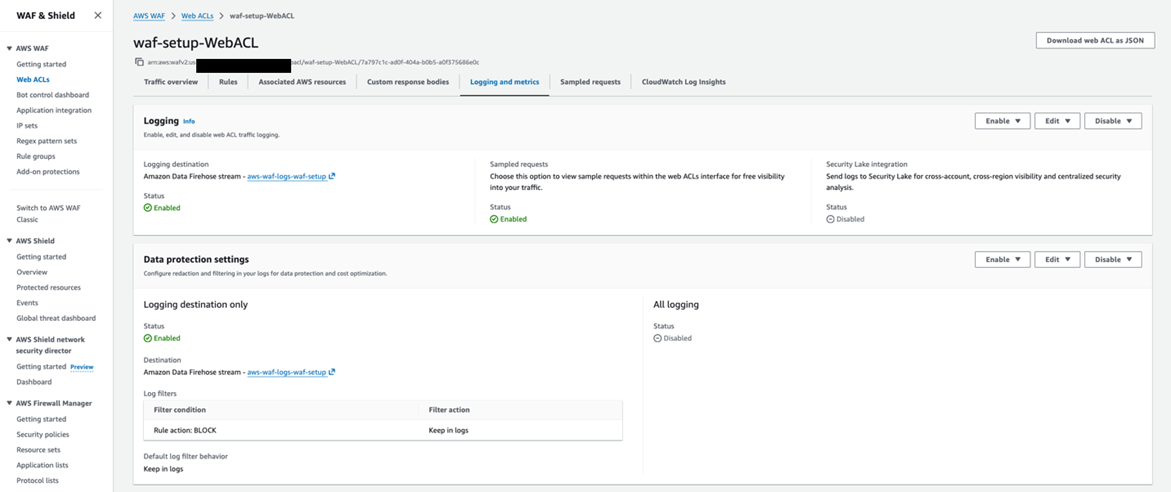
[图四:WAF日志投递配置] |
5.4 前置条件 4 (可选):配置日志过滤
默认情况下 WAF 会记录所有请求的日志。由于本方案只需要处理被 Rate-based Rule 阻断的请求,可以配置日志过滤来减少日志量和存储费用:
在 WAF WebACL 的 Logging and metrics 标签页中,在 Logging 部分点击 Edit,向下滚动到 Filter logs 部分:
- 点击 Add filter condition
- Filter behavior 选择 Keep in logs
- Condition 选择 Action on rule → Block
- Default behavior 选择 Drop from logs
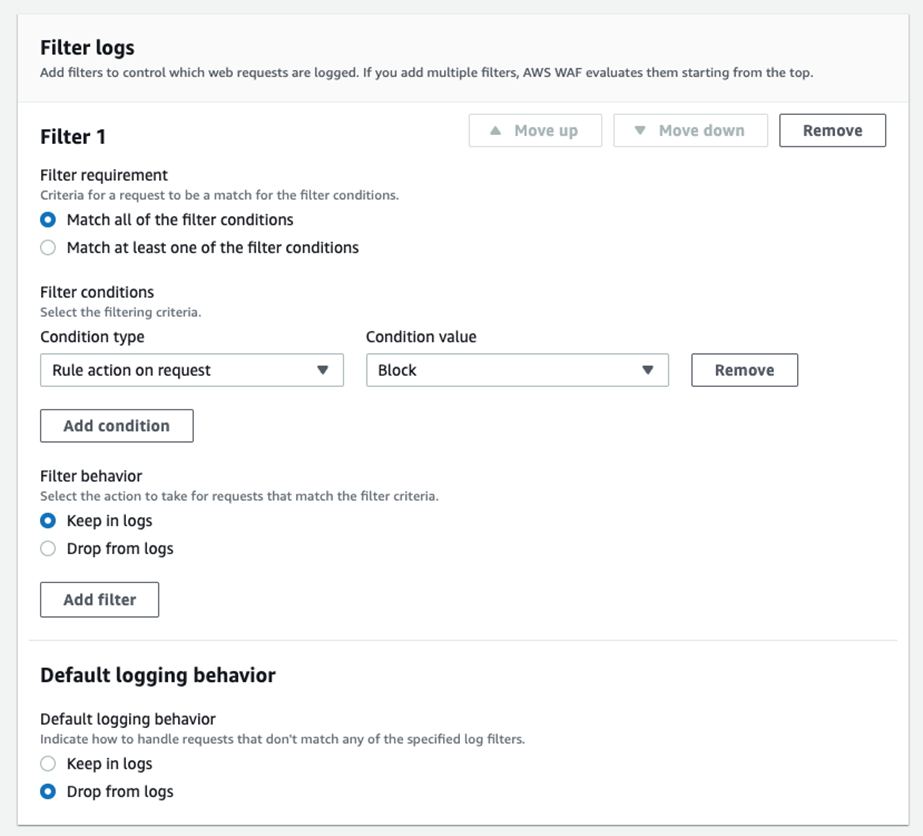
[图五:WAF日志过滤仅保留Block] |
保存后,只有被阻断的请求才会写入日志。这不影响方案功能(LogProcessorFunction 本身也只处理 action == ‘BLOCK’ 的记录),但能大幅降低 Firehose 和 S3 的费用。
ℹ️ 注意:
如果 WAF 日志还用于安全审计或流量分析等其他用途,建议保留全量日志,不配置过滤。
5.5 部署 AWS CloudFormation Stack
本方案通过一个 AWS CloudFormation template(freeze-ip-template.yaml)一键部署所有资源,包括 3 个 Lambda 函数、EventBridge 调度规则、IAM 权限,以及通过 Custom Resource 自动创建的 WAF IPSet、DynamoDB 表和 S3 事件通知。
在 AWS CloudFormation 控制台中,选择 Create stack → With new resources,上传 template 文件,填写 WebACL ARN、S3 Bucket ARN、Rate-based Rule 名称和封禁时长(分钟)。勾选 IAM 确认后点击 Create stack,等待状态变为 CREATE_COMPLETE(通常 2-3 分钟)。
| 参数 | 说明 | 示例 |
| WAFScope | WAF 部署模式:CLOUDFRONT(CloudFront,Global scope)或 REGIONAL(ALB/API Gateway,Regional scope) | CLOUDFRONT |
| WebACLArn | 前置条件 1 中记录的 WAF WebACL ARN | arn:aws:wafv2:us-east-1:123456789012:global/webacl/my-acl/abc-123 |
| S3BucketArn | 前置条件 3 中记录的 S3 Bucket ARN | arn:aws:s3:::aws-waf-logs-my-bucket |
| RateLimitRuleNames | 前置条件 2 中记录的规则 MetricName(CloudWatch 指标名称,可能与规则名不同),多个用逗号分隔 | RateLimitRule1,RateLimitRule2 |
| BlockDurationMinutes | 每个 IP 的封禁时长(分钟),与规则一一对应 | 10 |
5.6 验证部署结果
部署完成后,可以在 AWS WAF 控制台中确认 WebACL 的 Rules 列表中新增了以 stack 名称开头的 Block Rule(如 waf-ip-freeze-BlockRule-RateLimitRule1),并且 IP sets 中新增了对应的 IPSet。触发速率限制后,可以检查 IPSet 中的封禁 IP 和 DynamoDB 中的记录,经过配置的封禁时长后 IP 应自动移除。
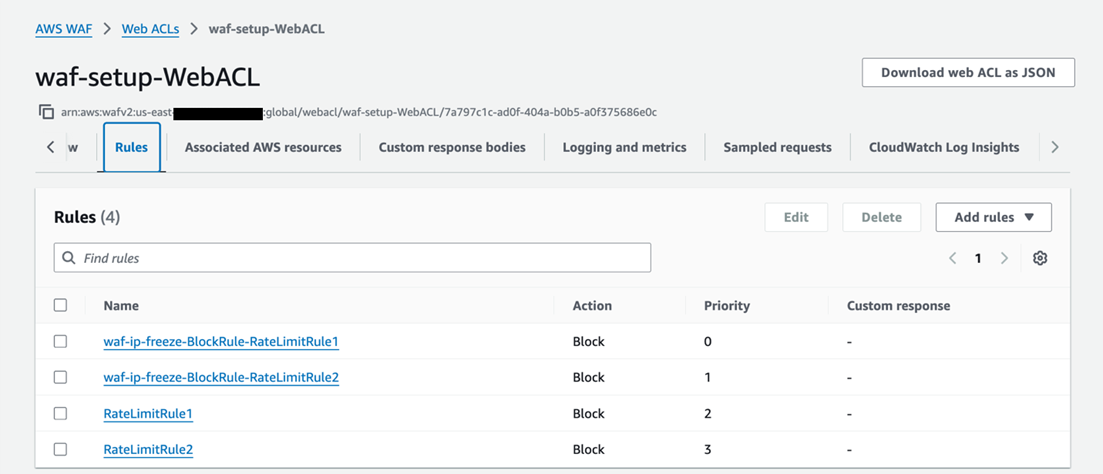
[图六:部署后Block Rule和IPSet] |
六、行为说明与边界情况
GetSampledRequests 每次调用最多返回 500 条请求。在极高流量下,部分被封禁的 IP 可能不出现在采样中。备份通道(S3 日志)弥补了这一差距,因为 WAF 日志是完整且未采样的。
每个 WAF IPSet 最多支持 10,000 个 IP 地址。CleanupFunction 确保过期 IP 被及时移除,在正常攻击场景下 IPSet 容量不会成为瓶颈。
SamplerFunction、LogProcessorFunction 和 CleanupFunction 都会调用 UpdateIPSet,存在并发竞争的可能。AWS WAF 使用乐观锁机制(LockToken):如果两个函数同时读取 IPSet 并尝试更新,后提交的一方会收到 WAFOptimisticLockException。三个函数均已实现指数退避重试(最多 5 次),绝大多数冲突会在重试中自动解决。
WAF API 存在限流约束(参考 AWS WAF quotas):GetSampledRequests 的限流为每账号每 Region 5 req/sec,UpdateIPSet 为 1 req/sec。SamplerFunction 每秒对每个规则调用一次 GetSampledRequests,监控 1-2 个规则时风险不大,但监控 5 个以上规则可能超限。三个 Lambda 函数的 UpdateIPSet 调用已包含指数退避重试逻辑,以应对限流和乐观锁冲突。
UpdateIPSet 成功后,变更传播到所有 CloudFront 边缘节点需要一定时间(参考 UpdateIPSet API 文档)。在传播期间,部分边缘节点可能尚未生效新的封禁或解封。
七、成本估算
以 us-east-1 为例,AWS Lambda x86 定价 $0.0000166667/GB-s(GB-s = 内存 GB × 运行秒数),$0.20/百万请求。以下按 Lambda 无免费额度估算:
| 服务 | 用量 | 月度成本 |
| AWS Lambda – SamplerFunction | 43,200 次 × 55s × 128MB ≈ 297,000 GB-s | ~$5.00 |
| AWS Lambda – CleanupFunction | 43,200 次 × ~3s × 128MB ≈ 16,200 GB-s | ~$0.30 |
| AWS Lambda – LogProcessorFunction | 按 S3 日志文件数量,每万次调用约 $0.03 | ~$0.15* |
| Amazon DynamoDB | 按需计费,仅存活跃封禁 IP | ~$1.00 |
| Amazon CloudWatch Logs | Lambda 平台日志 | < $0.50 |
| Amazon EventBridge | 免费额度内 | $0 |
| AWS WAF API | 免费 | $0 |
| 总计 | ~$7/月 |
*按每天 1,000 个日志文件、128MB 内存、平均执行 2 秒估算。注意:LogProcessorFunction 由 S3 WAF 日志文件的 ObjectCreated 事件触发,调用频率与流量成正比。在遭受大规模攻击时,WAF 日志文件数量会大幅增加,该函数的调用次数和计算费用也会相应上升。不过攻击通常是间歇性的,对月度总成本的影响有限。
如果账号下 Lambda 免费额度(400,000 GB-s/月)未被其他函数占用,SamplerFunction 的计算费可降至接近 $0,基础总成本约 $2/月。
八、总结
AWS WAF Rate-based Rules 能够实时检测和阻断高频流量,但原生不支持固定时长封禁。通过将 GetSampledRequests API 与 AWS Lambda、Amazon DynamoDB 和 AWS WAF IPSet 结合,可以实现可配置的 IP 冻结时长,具备近实时检测和自动解封能力——全部基于 Serverless 架构,每月基础成本约 $7(无免费额度)或 $2(有免费额度)。
双通道设计(API 轮询 + S3 日志处理)确保在 API 采样限制下也不会遗漏任何违规 IP。
➡️ 下一步行动:
相关产品:
- Amazon WAF — Web 应用程序防火墙
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- AWS Lambda — 无需服务器即可运行代码
- Amazon DynamoDB — 无服务器分布式 NoSQL 数据库
- Amazon CloudFormation — 基础设施即代码服务
相关文章:
- 基于 MinerU 和 AWS Serverless 构建企业级 RAG 文档处理平台-平台搭建-聊天助手部署与 Prompt 工程
- 基于 MinerU 和 AWS Serverless 构建企业级 RAG 文档处理平台-文档处理平台搭建
- DX 维护通知全球自动化处理方案 — 基于 Severless 的跨账号/跨区域实践
- Aurora 慢查询与无索引慢查询监控方案
- AWS Direct Connect 故障演练实战指南
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
