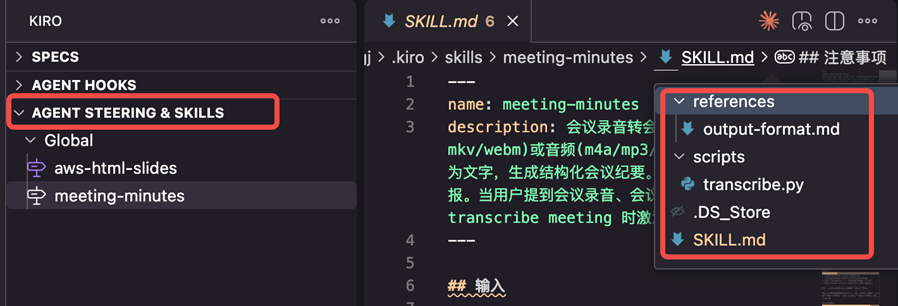
---
name: meeting-minutes
description: 会议录音转会议纪要。将视频(mp4/mkv/webm)或音频(m4a/mp3/wav/flac)文件转录为文字,
生成结构化会议纪要。支持生成会议工作日报。
当用户提到会议录音、会议纪要、转录、transcribe meeting 时激活。
---## 输入
用户提供以下信息:
- 文件路径:视频或音频文件的绝对路径
- 是否生成日报:可选,额外生成会议工作日报
- 输出目录:可选,默认与源文件同目录
## 执行步骤
### 第一步:环境检查1. 确认文件存在,识别文件类型(视频/音频)
2. 确认 ffmpeg 已安装(`which ffmpeg`)
3. 检查 whisper 虚拟环境是否存在:`~/whisper-env/bin/python` - 如果不存在,创建并安装依赖:
```bash
python3 -m venv ~/whisper-env
~/whisper-env/bin/pip install mlx-whisper
```
第二步:提取音频
用 ffmpeg 将源文件转为 WAV:
ffmpeg -i "<源文件>" -vn -acodec pcm_s16le -ar 16000 -ac 1 "<输出目录>/audio.wav" -y
第三步:转录
使用 scripts/transcribe.py 执行转录:
~/whisper-env/bin/python ~/.kiro/skills/meeting-minutes/scripts/transcribe.py "<音频文件路径>" "<输出目录>"
第四步:读取转录结果
1. 读取转录文本,分批处理大文件
2. 识别并过滤 whisper 幻觉(静默段落中反复出现的固定短语)
3. 修正常见语音识别错误(技术术语、人名、产品名)
第五步:生成会议纪要
基于转录内容生成结构化会议纪要,格式参见 references/output-format.md。
第六步(可选):基于会议记录生成其他类型报告
基于会议纪我们可以根据个人工作流程生成其他类型报告,例如要生成精简的工作日报,聚焦关键结论和待跟进事项等。
几个设计要点值得注意:
- description 要精准:Kiro 用 description 判断何时激活 Skill。写上”会议录音、会议纪要、转录、transcribe meeting”这些关键词,确保用户用中文或英文提问都能触发。
- 步骤编排要清晰:每一步做什么、用什么工具、输入输出是什么,都要写明。Agent 会严格按照步骤执行。
- 环境依赖要自检:第一步就检查 ffmpeg 和 whisper 环境,如果缺失就自动安装。这样用户不需要手动配置环境。
- 确定性任务交给脚本:语音转录是确定性任务(同样的输入必须产生同样的输出),交给 Python 脚本比让 LLM 处理更可靠。
4.2 编写转录脚本 transcribe.py
转录脚本使用 mlx-whisper,这是 OpenAI Whisper 的 Apple Silicon 优化版本,利用 MLX 框架在 Mac 上实现硬件加速。
#!/usr/bin/env python3
"""会议录音转录脚本 - 使用 mlx-whisper 进行语音识别"""
import sys
import os
def main():
if len(sys.argv) < 3:
print("Usage: transcribe.py <audio_file> <output_dir>")
sys.exit(1)
audio_file = sys.argv[1]
output_dir = sys.argv[2]
if not os.path.exists(audio_file):
print(f"Error: Audio file not found: {audio_file}")
sys.exit(1)
os.makedirs(output_dir, exist_ok=True)
import mlx_whisper
print(f"Transcribing: {audio_file}")
result = mlx_whisper.transcribe(
audio_file,
path_or_hf_repo="mlx-community/whisper-large-v3-turbo",
language="zh",
word_timestamps=False,
)
# 保存完整文本
transcript_path = os.path.join(output_dir, "transcript.txt")
with open(transcript_path, "w") as f:
f.write(result["text"])
# 保存分段文本(带时间戳)
segments_path = os.path.join(output_dir, "transcript_segments.txt")
with open(segments_path, "w") as f:
for seg in result["segments"]:
start = seg["start"]
end = seg["end"]
text = seg["text"].strip()
if text:
f.write(f"[{start:.1f}s - {end:.1f}s] {text}\n")
print(f"Total segments: {len(result['segments'])}")
print(f"Text length: {len(result['text'])} chars")
print("Done!")
if __name__ == "__main__":
main()
脚本输出两个文件:transcript.txt(完整文本)和 transcript_segments.txt(带时间戳的分段文本)。分段文本对后续的会议纪要生成很重要——Agent 可以根据时间戳判断话题切换点。
4.3 定义输出格式模板
references/output-format.md 定义了会议纪要和工作日报的标准格式:
# 会议纪要格式# 会议纪要:<主题>- **日期**:<从文件名或内容推断>
- **时长**:约XX分钟
- **形式**:<线上/线下>
- **参与方**:<从内容推断>
- **主题**:<核心主题>
---
## 一、<第一个议题>
...
## N、待跟进事项
| 事项 | 负责方 | 优先级 |
|---|---|---|
| ... | ... | ... |
## N+1、关键结论1. ...
# 会议工作日报格式# 会议工作日报- **日期**:
- **参与方**:
---
## 一、会议背景与议题## 二、关键讨论与结论## 三、待跟进事项
这个模板的作用是约束 Agent 的输出格式。没有模板时,Agent 每次生成的纪要格式可能不一致;有了模板,输出质量稳定可控。
4.4 处理 Whisper 幻觉
Whisper 有一个已知问题:在静默或低音量段落中,它会”幻觉”出重复的固定短语(比如反复出现的广告词、栏目名)。在 SKILL.md 的第四步中,我们明确要求 Agent 识别并过滤这些幻觉。
同时,语音识别对技术术语的准确率不高。比如”Elasticsearch”可能被识别为”一拉斯提克搜索”,”Kafka”可能变成”卡夫卡”。SKILL.md 中要求 Agent 根据上下文修正这些错误,这正是 LLM 擅长的事情——理解语境并做出合理推断。
五、使用方式
Skill 构建完成后,使用非常简单。在 Kiro 聊天窗口中输入类似以下内容:
帮我把 /Users/me/meetings/meeting_1.m4a 转成会议纪要
Kiro 会自动匹配到 meeting-minutes Skill 并激活,然后按照 SKILL.md 中定义的六个步骤依次执行。整个过程无需手动干预,最终在录音文件同目录下生成 会议纪要_<主题>.md。
Skill首先会检查环境里是否已经安装依赖组件(ffmpeg 和mlx-whisper),如果没有则会请求安装。用户同意后,便会自动安装。
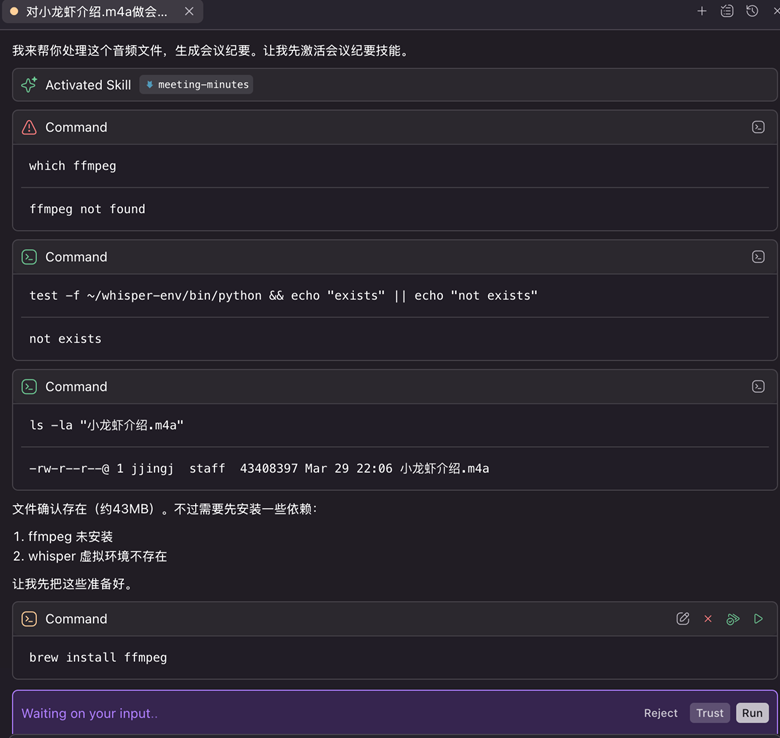
[图2] |
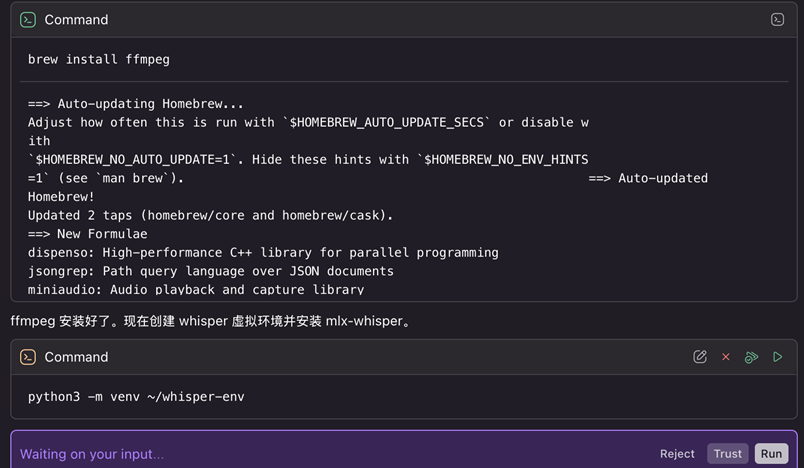
[图3] |
依赖安装完毕后,便会用ffmpeg先来处理文件格式。
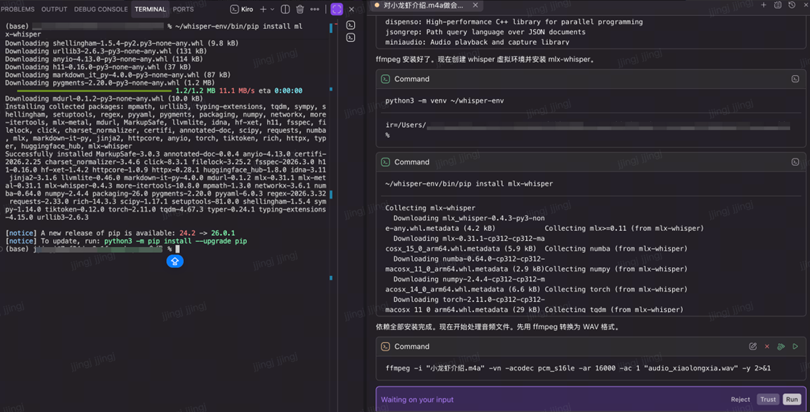
[图4] |
处理完音频格式后,便会用mlx-whisper来进行语音的转录了。
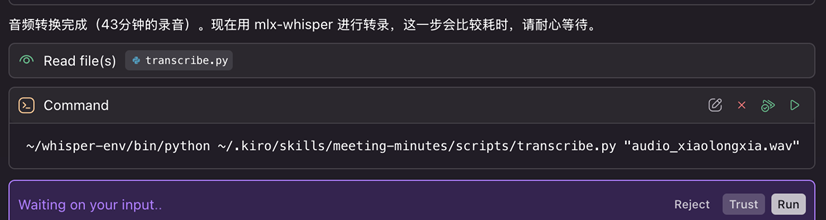
[图5] |
转录完成后,kiro便会用模型能力来根据音频生成相应的会议记录。
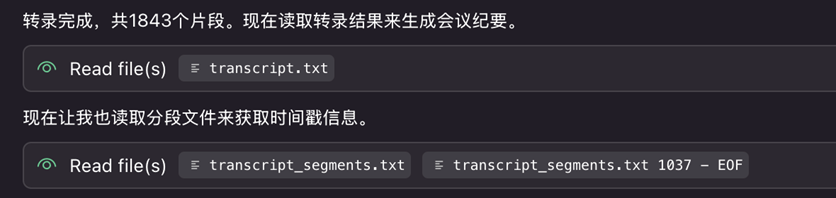
[图6] |
会议纪要的格式会按照 ~/meeting-minutes/references/output-format.md 的格式进行输出。语音中模糊或理解错误的转录也会被模型在这一步中进行纠正。
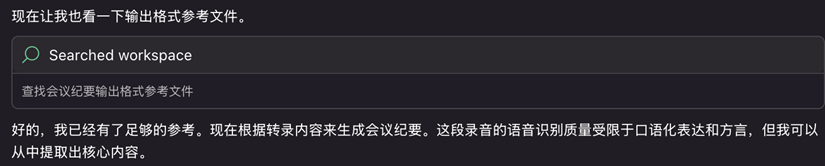
[图7] |
如果你还需要工作日报,可以说:
Agent 会在生成纪要后,额外输出一份精简的 会议工作日报_<日期>.md,聚焦关键结论和待跟进事项。
[图8] |
六、延伸:本地转录 vs 云端 ASR
本文的实现选择了本地 mlx-whisper 进行语音转录,主要原因是:
- Apple Silicon 加速:在 M 系列芯片的 Mac 上,mlx-whisper 利用 MLX 框架实现硬件加速,一小时的录音大约 5-10 分钟完成转录,性能完全够用。
- 隐私:会议内容不出本机,适合涉及敏感信息的内部讨论。
- 零成本:不需要调用任何云端 API,没有按量计费。
但如果你的场景不同——比如需要处理大量录音、或者需要更高的识别准确率——可以考虑接入 AWS 云端服务:
- Amazon Transcribe:AWS 的托管语音转录服务,支持中文,提供说话人识别(Speaker Diarization)、自定义词汇表、实时转录等能力。适合需要区分多个说话人的会议场景。
- Amazon Bedrock + LLM:转录完成后,可以用 Amazon Bedrock 上的大模型(如 Claude)替代 Kiro Agent 做纪要生成,适合批量处理或 CI/CD 集成场景。
云端方案的 Skill 改造也很简单——只需要修改 transcribe.py,将 mlx-whisper 调用替换为 Amazon Transcribe SDK 调用,SKILL.md 的步骤编排基本不变。你甚至可以用 Kiro 的 Power 机制,将 AWS SDK 作为 MCP 工具接入,让 Agent 直接调用云端服务。
七、Skill 开发最佳实践
基于这个实战案例,总结几条 Skill 开发经验:
- description 决定激活时机:Kiro 用 description 中的关键词判断是否激活 Skill。写得太泛会误触发,写得太窄会漏触发。建议覆盖中英文关键词和常见表述。
- SKILL.md 保持精简:把详细的格式定义、参考文档放到
references/ 目录。Kiro 激活 Skill 时会加载完整的 SKILL.md,过长会浪费上下文窗口。
- 确定性任务用脚本:语音转录、文件格式转换、数据校验这类任务,结果必须确定,交给脚本比交给 LLM 更可靠。LLM 擅长的是理解、推理和生成,把它用在刀刃上。
- 环境依赖要自检:在 SKILL.md 的第一步就检查依赖(ffmpeg、Python 虚拟环境),缺失时自动安装。用户体验的关键是”开箱即用”。
- 选对扩展机制:不需要 MCP 工具就用 Skill,需要外部工具就用 Power,项目规范用 Steering,自动化触发用 Hook。不要过度设计。
八、总结
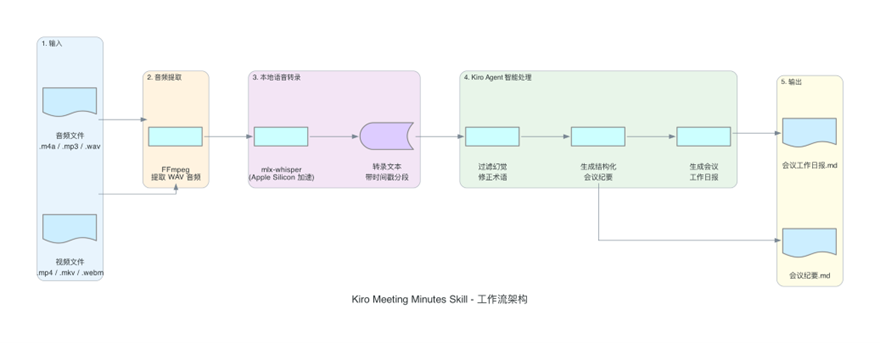
Kiro Skill 让你可以把任何重复性工作流封装成 AI Agent 的能力。本文以会议纪要生成为例,展示了从零构建一个 Skill 的完整过程——从目录结构设计、指令编排、脚本开发到输出模板定义。
这个思路可以推广到很多场景:代码审查清单、部署检查流程、文档生成模板、数据分析报告……任何你发现自己在重复做的事情,都可以考虑封装成一个 Skill。
Skill 遵循 agentskills.io 开放标准,你构建的 Skill 不仅能在 Kiro 中使用,也可以在其他支持该标准的 AI 工具中复用。
开始构建你的第一个 Skill 吧。
➡️ 下一步行动:
相关产品:
相关文章:
九、参考链接
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者

2026 亚马逊云科技中国峰会
智能投标、AI 质检、财务自动化、智能客服——生产级 Agent 全天开放体验。

|
 |