亚马逊AWS官方博客
使用 Amazon Forecast 评估预测模型准确性,切实优化业务目标
原文链接:https://aws.amazon.com/cn/blogs/machine-learning/measuring-forecast-model-accuracy-to-optimize-your-business-objectives-with-amazon-forecast/
我们高兴地宣布,现在您可以使用AWS最新功能来衡量预测模型的准确性,借此优化可能存在的预测成本过低或过高问题,进而提升实验的灵活性。预测过低和预测过高所导致的成本是不同的。通常,预测过高可能导致高昂的库存成本与资源浪费,而预测过低则可能导致库存缺货、无法满足需求以及错失收入机会。 Amazon Forecast 通过提供平均预测并捕捉需求从最小值到最大值变化的预测分布,帮助您针对业务目标优化具体成本。通过此次发布,Forecast 现在可以在模型训练过程中为多个分布点提供准确性指标,帮助您快速优化预测过低与预测过高,且全程无需手动进行指标计算。
零售商一直依靠概率预测以优化自身供应链,确保在预测过低(导致库存缺货)与预测过高(导致库存过量及资源浪费)之间取得平衡。根据产品类别不同,零售商可以为各个不同的分销点生成预测。例如,杂货零售商可以选择适当提高牛奶及鸡蛋等副食品库存量以满足不断变化的需求。这是因为此类商品的运营成本相对较低,但是一旦缺货不仅导致相应部分的营业额受损,更可能导致客户直接放弃本打算一并购买的其他商品。在这种情况下,通过维持较高的库存率,零售商可以提高客户满意度与忠诚度。与之对应,当降价促销或库存处理成本超过偶发性的销售损失时,零售商则更倾向于选择库存不足,借此抵消高昂的潜在库存成本。随着需求的持续变化,对不同分销点做出准确预测的能力将帮助零售商持续优化业务运营思路,在市场竞争中始终占得先机。
Anaplan 公司拥有一套用于协调业务绩效的云原生平台,已经将 Forecast 集成至其 PlanIQ 解决方案当中,借此为企业客户带来更准确的预测及敏捷规划方案。产品管理总监 Evgy Kontorovich 表示,“我们为每一家合作客户都打造有一套独特的运营与供应链模型,用以驱动不同的业务重点。一些客户希望以更审慎的态度做出预测,以尽可能减少库存,另一些客户则更关注如何提高库存可用性,借此始终如一的满足客户需求。借助预测分位数,规划人员可以评估这些模型的准确性、模型质量并根据业务目标做出微调。这种通过多个自定义分位数级别评估预测模型准确性的能力,也让我们的客户能够进一步针对业务实际做出高度明智的优化决策。”
虽然Forecast提供了对整体变化分布做出预测的能力,借此在库存过低与库存过量之间求取平衡,但其准确性指标仅适用于最低、中位数与最高预测需求,并以80%的置信度作为中位数评判边界。要评估特定兴趣点上的准确性指标,您首先需要在该点上创建预测,然后自行手动计算准确率指标。
通过今天的发布,您可以在Forecast中的任何分布点上评估预测模型,且无需生成预测结果或执行手动计算指标。此功能使您能够更快进行实验,从而经济高效地找到满足业务需求的分布点。
要使用此项新功能,请在创建预测器时选择需要关注的预测类型(或者分布点)。Forecast会将输入数据分为训练数据集与测试数据集,用以训练及测试所创建的模型,并为这些分布点生成准确性指标。您可以继续尝试以进一步优化预测类型,且无需在各个步骤中分别创建预测。
关于Forecast准确性指标
Forecast为您提供多种不同的模型准确性指标,供您评估预测模型。我们为每个指定的分布点提供加权分位数损失(wQL)指标,以及在平均预测时计算的加权绝对百分比误差(WAPE)与均方根误差(RMSE)。对于每项指标,较低的值表示误差较小,即代表模型准确性更高。所有这些准确性指标都将保持在非负区间。
下面,我们通过一份表格以零售数据集为例,了解这些不同的准确性指标。在此数据集中,我们面向未来两天做出三项预测。
| 条目ID | 备注 | 日期 | 实际需求 | 平均预测 | P75预测 | P75误差(P75预测-实际) |
平均绝对误差 |实际–平均预测| |
均方误差 (实际–平均预测)2 |
| Item1 | Item 1是一种需求量很大的热门商品 | 第1天 | 200 | 195 | 220 | 20 | 5 | 25 |
| 第2天 | 100 | 85 | 90 | -10 | 15 | 225 | ||
| Item2 | Item 2是一种需求较低,且需求主要分布在长尾区间内的商品 | 第1天 | 1 | 2 | 3 | 2 | 1 | 1 |
| 第2天 | 2 | 3 | 5 | 3 | 1 | 1 | ||
| Item3 | Item 3是一种需求主要分布在长尾区间内,且观察到的需求与实际需求存在较大偏差的商品 | 第1天 | 5 | 45 | 50 | 45 | 40 | 1600 |
| D第2天 | 5 | 35 | 40 | 35 | 30 | 900 | ||
| 总需求 = 313 | 用于wQL[0.75] | 用于WAPE | 用于RMSE |
下表总结了使用零售数据集用例计算出的准确性指标。
| 指标 | 值 |
| wQL[0.75] | 0.21565 |
| WAPE | 0.29393 |
| RMSE | 21.4165 |
在以下各节中,我们将具体解释每项指标的计算方式,以及针对每项指标的最佳用例建议。
加权分位数损失 (wQL)
wQL指标用于在名为分位数的指定分布点上测量模型的准确性。此项指标有助于捕捉每个分位数中的固有偏差。对于倾向于过量储备牛奶等的杂货零售商而言,选择较高的分位数(例如0.75,即P75)能够更好地捕捉需求峰值,其实际意义也高于在0.5分位数(P50)上获得的预测值。
在此示例中,我们更多强调预测过度、而非预测不足,并建议需要更高的库存量才能以75%的成功概率满足客户需求。换句话说,实际需求会在75%的时间内小于或等于预测需求,从而使杂货零售商能够以较少的安全库存维持目标库存率。
当预测不足及预测过度所对应的成本不同时,我们建议在不同的分位数上使用wQL指标。如果成本差异可以忽略不计,则可以考虑以0.5(P50)的中位数分位数进行预测,或者使用WAPE指标,该指标使用平均预测进行评估。下图所示,为根据百分位得出的满足购买需求的概率。

对于零售数据集用例,P75预测表明我们需要优先考虑预测过度,且同时对预测不足加以惩罚。要计算wQL[0.75],我们可以将P75误差列中的正项值相加,而后乘以1 – 0.75 = 0.25的较小权重,而后将P75误差列中负项的绝对值相加并乘以0.75的较大权重来惩罚预测不足。wQL[0.75]如下:

加权绝对百分比误差 (WAPE)
WAPE指标是总需求归一化的绝对误差总和。WAPE同样会因预测不足或预测过度而受到惩罚,因此不对二者做出任何倾向。我们使用预测的期望均值(平均)来计算绝对误差。当预测不足或预测过高的差异可以忽略不计时,或者您希望在平均预测时评估模型准确性时,建议使用WAPE指标。例如,为了预测特定时间在ATM机中储备的现金量,银行可能会选择满足平均需求,换言之,既不担心无法为客户提供充足现金,又不担心ATM机中储备的现金量过大。在此示例中,您可以选择以均值进行预测,而后选择WAPE作为指标以评估模型的准确性。
归一化或加权,有助于对使用不同数据集训练出的模型进行比较。例如,如果整个数据集的绝对误差总和为5,则在不清楚总需求规模的情况下,我们很难解释该指标的质量。总需求高(1000)将导致WAPE指标低(0.005),总需求低(10)则导致WAPE指标高(0.5)。WAPE与wQL中的权重允许在不同规模的数据集之间直接比较这些指标。
归一化或加权也有助于评估包含不同规模的混合条目数据集。WAPE指标主要强调需求量较大的商品的准确性。您可以将WAPE用于那些少量SKU预测会推动大部分销售额的数据集。例如,如果零售商可能更喜欢使用WAPE指标,以减少商品中某些特定版本所引发的预测误差,并优先考虑销售额最高的标准商品的预测误差。
在我们的零售数据集用例中,WAPE等于绝对误差列的总和除以实际需求列的总和(总需求)。

由于总需求的总和主要由Item1驱动,因此WAPE更重视销售量更大的Item1的准确性。
许多零售客户使用稀疏数据集,其中大部分SKU很少出售。对于大多数历史数据点而言,其需求为0。对于这些数据集,考虑总需求规模非常重要,这使得wQL和WAPE优于RMSE,可以评估稀疏数据集。RMSE指标并不考虑到总需求的规模,而是通过考虑历史数据点总数和SKU总数,来返回较低的RMSE值,这会给您造成一种模型准确性较高的假相。
均方根误差(RMSE)
RMSE指标是平方误差(预测均值与实际值的差)之和的平方根除以条目数量与时间点数量的乘积。如果预测不足或者预测过度之间的折衷可以忽略不计,或者您希望进行平均预测,那么不会对预测不足或预测过度做出任何惩罚的RMSE就显得更为合适。由于RMSE与误差的平方成正比,因此它对实际需求与预测值之间存在的较大偏差会非常敏感。
但是,请您谨慎使用RMSE,因为预测误差中的某些较大偏差会严重影响原本准确的模型。例如,如果大型数据集中的某一条目出现了严重的预测不足或预测过度,则该条目的误差会导致整个RMSE指标的严重偏离,并可能使您直接否定一个本来准确的模型。对于一些较大偏差、但较低重要性的用例,请考虑使用wQL或WAPE指标。
在我们的零售数据集示例中,RMSE等于平方误差列之和的平方根除以总点数(3个条目 x 2天 = 6)。

RMSE更重视Item3预测误差中的较大偏差,这会导致更高的RMSE值。
如果模型中某些条目上发生错误预测会给企业造成重大损失,我们建议您优先使用RMSE指标。例如,预测机器故障的制造商可能更倾向于使用RMSE指标。由于操作机械非常重要,因此在评估模型的准确性时,应明确强调实际需求与预测需求之间的任何较大偏差(即使偏差的出现频率很低)。
下表所示,总结了我们之前就准确性指标的选择标准所讨论的结果。
| 用例 | wQL | WAPE | RMSE |
| 针对可能带来不同影响的预测不足或预测过度做出优化 | X | ||
| 优先处理高人气或高需求商品,其重要度高于低需求商品 | X | X | |
| 强调因为预测误差过大引发的业务成本影响 | X | ||
| 评估对象为稀疏数据集,即历史数据点中的大多数条目的需求为0 | X | X |
选择自定义分布点以评估Forecast中的模型准确性
您可以通过 CreatePredictor API 与 GetAccuracyMetrics API ,或者使用Forecast控制台在Forecast中衡量模型的准确性。在本节中,我们将分步介绍控制台的使用步骤。
- 在Forecast控制台上,创建一个数据集组。

2. 上传您的数据集。
3. 在导航面板中,选择Predictors。
4. 选择Train predictor。
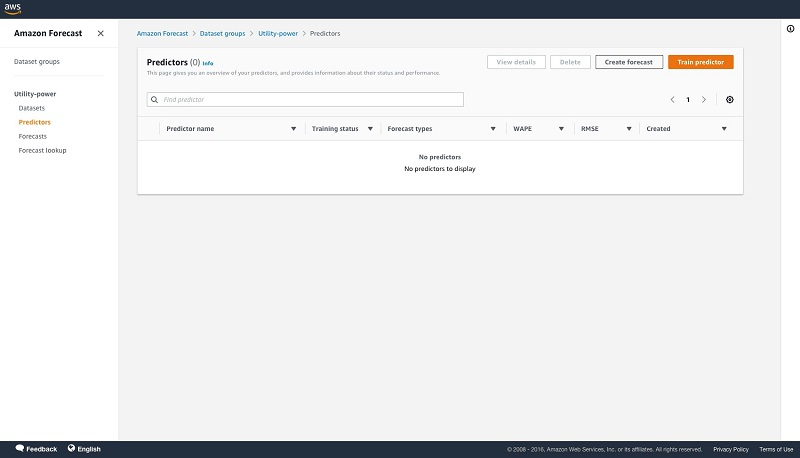
5. 在Predictor Settings中的Forecast types之下,您最多可以输入选定的五个分布点,且可以使用均值。
如果未指定,则使用默认分位数0.1、0.5以及0.9来训练预测器,并计算相应的准确性指标。
6. 在Algorithm selection部分,选择 Automatic (AutoML)。
AutoML能够针对指定的分位数实现模型优化。
7. 作为可选项,您可以在Number of backtest windows中选择最多5个窗口以评估模型。
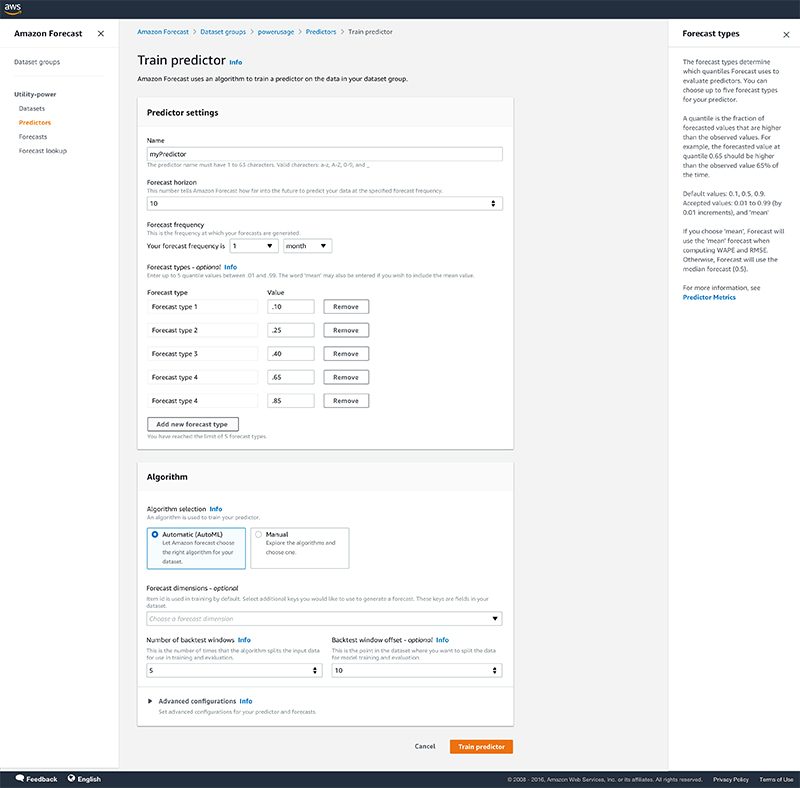
8.在预测器训练完成之后,在Predictors页面上选定您的预测器以查看各准确性指标的详细信息。

在预测器的详细信息页面上,您可以查看整体模型的准确性指标,以及来自指定的回测窗口的具体指标。整体模型的准确性指标可通过对各回测窗口指标求均值来计算。
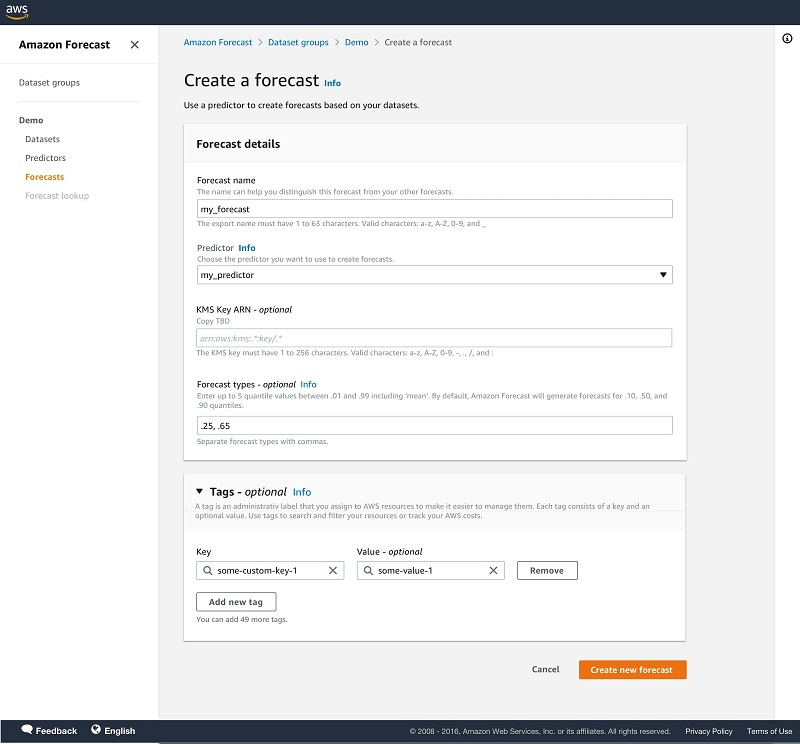
9. 现在您的模型已经训练完成,接下来在导航面板中选择Forecasts。
10. 选择Create a forecast。
11. 选择经过训练的预测器以创建预测。
在预测器训练期间,各分布点将生成对应的预测结果。作为可选项,您还可以指定不同的分布点以生成相应预测。
提示与最佳实践
在本节中,我们将分享使用Forecast时的技巧与最佳实践:
- 在尝试使用Forecast之前,请定义与预测不足或预测过度相关的业务问题。评估权衡结果并确定优先顺序(例如更倾向于预测过度,而非预测不足)。
- 对多个分布点进行试验,以优化您的预测模型,在预测不足与预测过度之间实现成本平衡。
- 如果您要对多个不同模型进行比较,请使用相同分位数的wQL指标进行比较。值越低,则代表预测模型越准确。
- Forecast允许您最多选择5个回测窗口。Forecast使用回测机制调整预测器并生成准确性指标。为了执行回测,Forecast会自动将我们的时间序列数据集分为两组:训练数据集与测试数据集。训练数据集用于训练模型,测试数据集则用于评估模型的预测准确性。我们建议选择一个以上的回测窗口,以最大程度减少选择偏差。单一窗口的偶然性或多或少会影响准确性。通过多个回测窗口评估模型的整体准确性,能够帮助我们更好地评估模型。
结论
现在,大家可以使用Forecast在您所指定的多个分布点上测量预测模型的准确性。这使您可以更灵活地将Forecast与您的业务保持同步,因为预测过度与预测不足所引发的影响经常不同。您可以在Forecast正式上线的各区域内使用这项功能。关于区域可用性的更多详细信息,请参阅区域表。关于在创建预测器与访问准确性指标时指定自定义分布点API的更多详细信息,请参阅CreatePredictor API 与 GetAccuracyMetrics API说明文档。关于评估多个分布点上预测器准确性的更多详细信息,请参阅评估预测器的准确性。