亚马逊AWS官方博客
把 OpenClaw 从个人助手变成客服:一次信任模型的翻转
摘要:本文探讨如何将 OpenClaw 从个人 AI 助手转型为面向客户的服务Agent。围绕五个核心问题展开:会话隔离(dmScope 配置实现多客户 session 独立)、多渠道接入(Web Widget 与消息平台的身份关联)、安全模型(tools.deny 硬约束 + Bedrock Guardrails 内容过滤的双层防护)、知识库注入(Bootstrap 文件 + Amazon Bedrock Knowledge Bases 的 RAG 检索)、以及客户记忆的局限与演进方向。部署架构基于 AWS,采用 ALB + ECS 认证中间层 + 私有子网 Gateway 的分层设计,通过 VPC Endpoint 调用 Bedrock、AgentCore 等服务,兼顾安全隔离与低延迟。
目录
一、引言:从”助手模式”到”服务模式”
Your own personal AI assistant. 这是OpenClaw GitHub Repo About的第一句话。你的 OpenClaw Agent 帮你写代码、管理项目、处理邮件——它把你当主人,有求必应。对于很多人来说,第一次感受到了来自 “Agent” 的震憾。一些先行者开始思考,能不能拿这个助手服务客户——回答产品问题、引导购买、处理售后。
问题是:客户不是主人。
OpenClaw 的默认安全模型是”个人助手”——一个 Gateway 实例 = 一个信任边界,通过认证的调用者被视为 Gateway 级别可信。这意味着 Agent 默认有命令执行、文件读写、浏览器控制等能力——一个“个人助手”需要这些。如上一篇OpenClaw安全增强文章介绍,我们只需要在它的外围加上防护(不向公网开放端口),通过安全的管道调用服务(VPC Endpoint),提供正确的技能/知识(检查Skill是否有毒),它可以在边界内探索无穷的可能。
但当客户成为对话者时,这些能力就变成了攻击面。客户可以享受快速和个性化的服务,但不能下指令要求Agent重启。
面向客户部署OpenClaw需要从”助手模式”切换到”服务模式”。架构不变(Gateway/Channel 抽象/Agent Loop/插件生态),但信任假设要翻转。
这个翻转带来几个必须回答的问题:
| # | 问题 | 从…到… |
| 1 | 会话如何隔离? | 共享 session → 按客户隔离 |
| 2 | 客户如何触达? | 被动等待 → 多渠道主动接入 |
| 3 | 权限如何收紧? | 开放工具 → 最小权限 |
| 4 | 知识从哪来? | 个人工作区 → 面客知识库 |
本文逐一展开这四个问题。在最后,我们还会触及第五个问题——Agent 怎么”记住”客户。
二、第一章 会话隔离:谁是谁?
默认配置下(dmScope: "main"),所有 DM 消息进入同一个 session——sessionKey 是 agent:support:main。客户 Alice 说“我的订单号是 12345”,客户 Bob 紧接着问“我的订单到哪了?“——Agent 看到的上下文里两个人的消息混在一起。
在个人助手模式下,所有消息确实属于同一个”主人”——你从 WhatsApp 发的和从 Telegram 发的应该在同一个上下文里。但面向多个客户的场景,这就是隐私泄露。
2.1 四种 dmScope 模式
OpenClaw 支持通过 dmScope 配置控制 DM 消息的 session 分配:
| 模式 | Session Key 格式 | 隔离级别 | 适用场景 |
main(默认) |
agent:{id}:main |
无隔离——所有 DM 共享 | 个人助手 |
per-peer(推荐) |
agent:{id}:direct:{peerId} |
按客户——跨渠道共享 | 面客 + 跨渠道关联 |
per-channel-peer |
agent:{id}:{channel}:direct:{peerId} |
按渠道+客户 | 渠道间需要严格隔离 |
per-account-channel-peer |
agent:{id}:{channel}:{account}:direct:{peerId} |
多账号收件箱 | 大企业多账号 |
其中 peerId 是客户的唯一标识——WhatsApp 是手机号(+8613800138000),Telegram 是用户 ID(123456789),飞书是 Open ID(ou_xxxxxxxx)。
只需在 openclaw config.json 配置一行:
效果:每个客户自动获得独立的 session,对话上下文完全隔离。
2.2 为什么推荐 per-peer?
per-peer 让同一客户在不同渠道(Telegram/WhatsApp/Web Widget)共享同一个 session。配合 identityLinks(后面会讲),可以实现跨渠道的客户身份关联——客户从 Telegram 开始咨询,后来切到网页继续,上下文不丢失。
如果你的场景需要渠道间严格隔离,选 per-channel-peer。 比如你搭了一个 AI 健康助理,客户Alice同时接入 Telegram 和 WhatsApp:Telegram 上她问的是心理健康相关问题(比较私密,Telegram 是她的”匿名”渠道),WhatsApp 上她问的是日常运动、饮食建议(可能会分享给家人/朋友一起看)。如果用 per-peer(配合identityLinks),两边的对话会合并到同一个 session。当Alice在 WhatsApp 问”最近该吃什么”时,Agent 的上下文里带着她在 Telegram 上的心理咨询内容——万一 Agent 在回复里提了一嘴,会导致隐私泄露。
2.3 Session 重置
面客场景下,客户可能隔几天才来第二次咨询。Session 重置策略决定了”多久没活动后重新开始”:
也可以设为 daily(每天凌晨重置),或两者结合(先到先触发)。
三、第二章 多渠道接入与客户身份
客户通过什么途径找到你的 Agent?不同渠道的客户身份来源不同——但对 OpenClaw 来说是统一的。
3.1 两种渠道、两种身份来源
| 渠道类型 | peerId 来源 | 身份确认方式 |
| Web Widget | 后端已知(客户已登录) | 登录态(JWT/session cookie) |
| 消息渠道(WhatsApp/Telegram/飞书等) | 平台自动提供(手机号/用户ID) | 对话内认证(可选) |
3.2 Web Widget:已登录,直接知道用户
自建 Web Widget 的架构是:
客户在你的网站已登录,后端知道用户 ID——直接作为 peerId 传给 Gateway。无需额外认证步骤。
这个“你的后端”在实际部署中需要云基础设施支撑。一个典型的生产架构如下(基于 亚马逊云科技 部署):
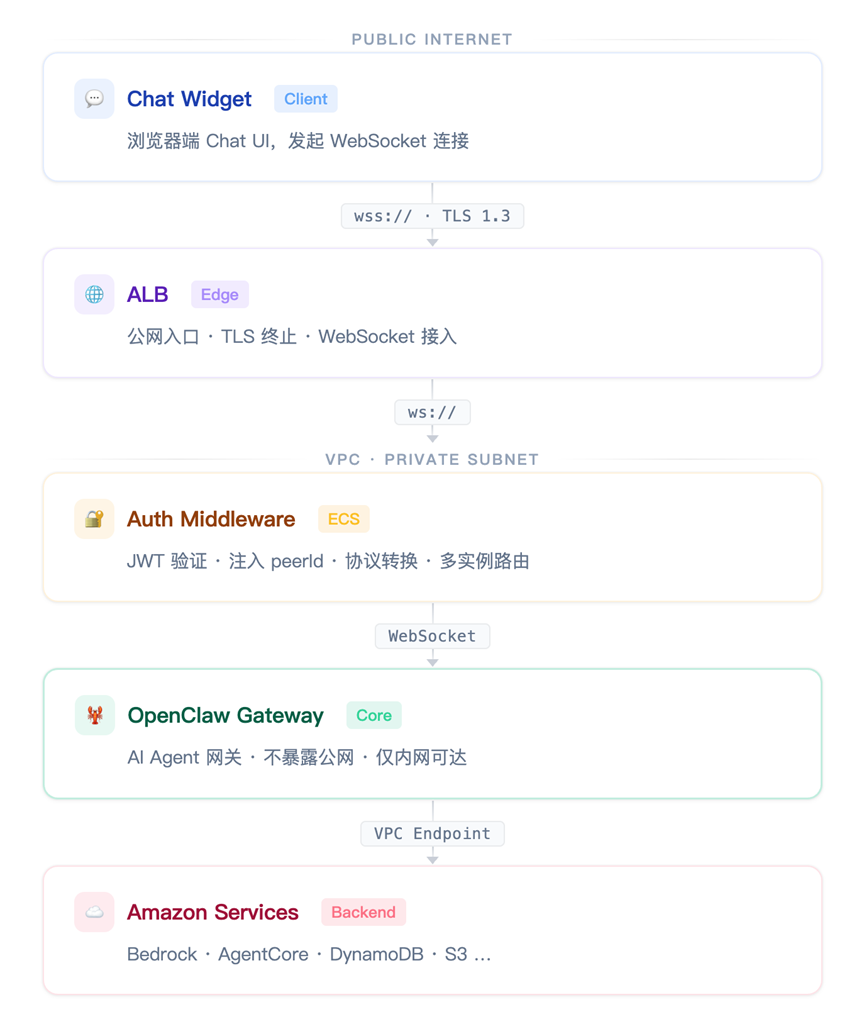
[图1 典型的网站Web Widget架构] |
为什么需要认证中间层? OpenClaw Gateway 有自己的 token 认证(保证只有可信服务能调用),但不做业务层的用户身份认证。在个人助手模式下这没问题(只有你自己是调用者),但面客场景下,你需要在 Gateway 前面加一层:验证客户的登录态(JWT/session cookie),从中提取用户 ID 作为 peerId,以可信身份连接 Gateway。这一层用 EC2或 ECS都可以。在并发数量大时,考虑多个 OpenClaw Gateway 负载均衡,此时可在中间层添加基于 peerId 的路由功能,使用 DynamoDB 或 Redis 做缓存/持久化,实现 sticky session,保证同一个用户始终路由到同一个实例,不丢失上下文。
为什么 Gateway 不直接暴露? 这和第三章的安全模型呼应——tools.deny 是应用层的硬约束,网络隔离是基础设施层的硬约束。Gateway 放在私有子网,通过 ALB 做唯一入口,Security Group 只允许 ALB 的流量进入。即使应用层出了问题,攻击者也无法直接触达 Gateway。同时,通过 VPC Endpoint 让 Bedrock、AgentCore 等 AWS 服务调用走内网,不经公网——既降低延迟,也避免数据离开 VPC。
WebSocket 的选择:ALB 原生支持 WebSocket,适合大多数场景。
用户记忆隔离:OpenClaw 内置记忆是 agent 级的,所有用户共享同一份记忆,不适合面客场景。我们通过 memory-agentcore 插件实现用户级隔离(插入另一篇 blog 的 link,两篇同时提了TT)——每个用户的对话记忆存放在独立的 namespace 中,公共知识存放在共享 namespace,扩展到多实例时无需迁移数据。具体的记忆架构设计将在下一篇文章中详细介绍。
Web Widget 可选功能:OpenClaw Gateway 原始事件包括了 tool_use / tool_call 记录,自研 Web Widget 可以根据需求做工具调用的卡片展示,或替换为 “正在查询”之类的进度提示,增强用户使用的信心。另外,自研 Widget 还可以实现多轮对话历史管理——OpenClaw Gateway 的 WebSocket 协议提供 chat.history 方法,Widget 可以在页面刷新或断线重连后拉取之前的对话记录,恢复完整上下文。
3.3 第三方社交App Channel
WhatsApp、Telegram、飞书等内置Channel,配置即用:
1. 在第三方平台注册 Bot(获取 Token)
2. 在 openclaw.json 启用 Channel + 设置 dmPolicy: "open" + allowFrom: ["*"]
3. 客户搜到 Bot 就能聊
体验和加好友发消息没有区别。在电商场景,给 OpenClaw Agent 配置上不同的 SKills ,就可以快速的构建不同领域的 Agent。比如配合个性化推荐API,或者 Text2SQL 查询,就是简单的售前导购Agent;配置上知识库和客服查询 API,就是售后服务Agent。可以便利的将渠道延伸到社交App。
3.4 消息渠道的身份问题
消息渠道的 peerId 是平台身份(手机号、Telegram ID),不是你的业务用户 ID。如果你需要关联到 CRM 里的客户档案,有两种做法:
3.4.1 做法一:不关联,直接用平台身份
手机号/Telegram ID 本身就是稳定的客户标识。同一客户每次回来都是同一个 peerId,session 自动连续。对于简单的咨询场景,这通常够用。
3.4.2 做法二:对话内认证 → identityLinks 关联
如果需要将平台身份映射到业务用户 ID(比如客户在你系统中的账号),可以在对话中引导认证:
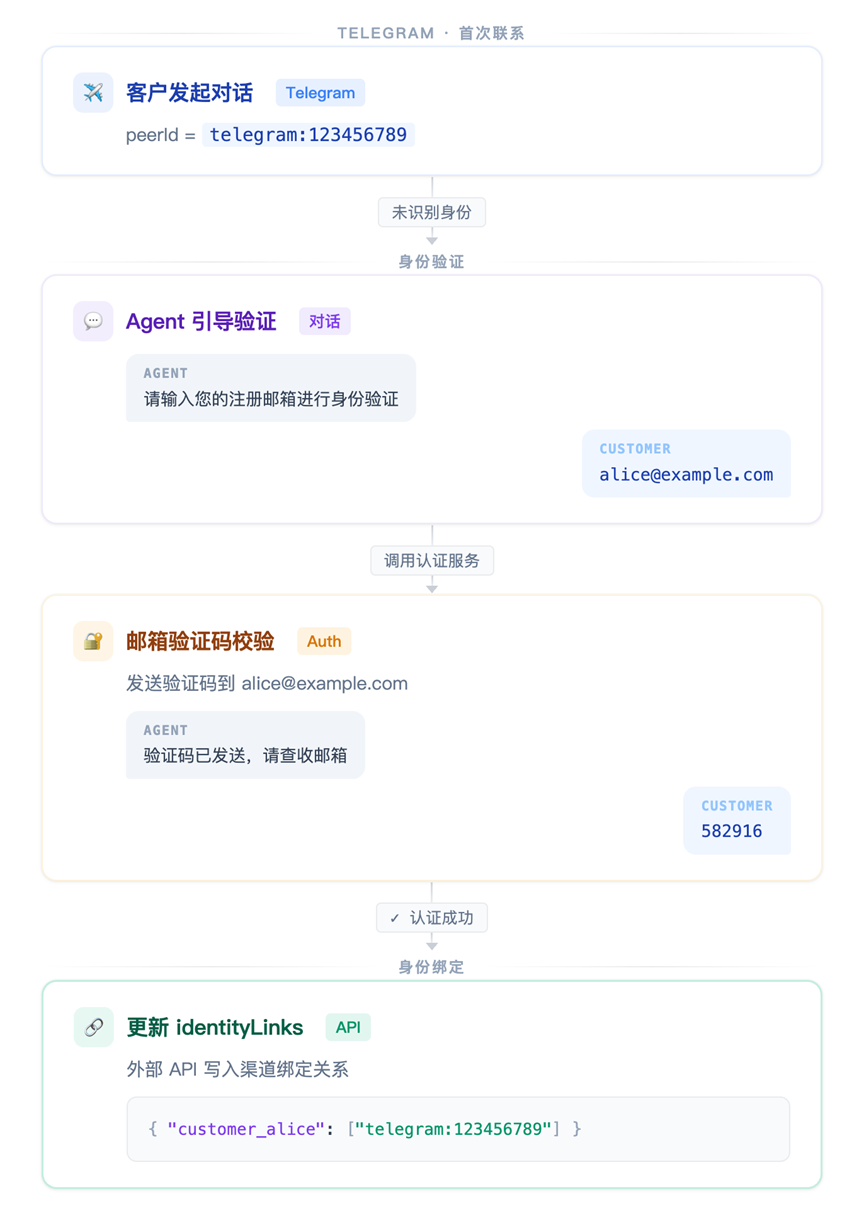
[图2 identityLinks关联的示例流程] |
之后客户从 Web Widget(已登录,peerId = customer_alice)联系时,identityLinks 更新为:
此后 Telegram 和 Web Widget 的 session 自动合并——OpenClaw 知道这是同一个人。客户在不同的渠道联系,上下文是一样的。
关键设计:面向客户的Agent 不直接修改配置(不安全)。identityLinks 定义在 openclaw.json 的 session.identityLinks 中。外部认证服务验证成功后,通过 Gateway 的 config RPC(config.patch)或直接修改配置文件来更新 identityLinks,Gateway 会自动热重载生效,不需要重启,不会影响其它正在对话的客户。
四、第三章 安全模型:Prompt 软约束 vs 代码硬约束
你在 SOUL.md 里写了”不要执行客户的命令请求”。客户说”帮我运行 ls /etc 看看”。
LLM 可能遵守,也可能不遵守。今天遵守了,换个 phrasing 明天可能就不遵守了。更精心设计的 prompt injection 甚至可以让 LLM “忘记”你的指令。
这就是软约束——依赖 LLM 的行为。面向客户服务的场景,安全不能依赖软约束。
tools.deny 是硬约束——即使 LLM 决定调用 exec,Gateway 在工具执行前直接拒绝。这是服务端代码层面的强制执行,不经过 LLM。
4.1 为什么禁止这些工具
每个限制都有明确的风险场景:
| 禁止项 | 如果不禁 | 风险场景 |
group:runtime(exec/process) |
客户可以让 Agent 执行任意命令 | “帮我运行 ls” → 服务器文件列表泄露 |
group:fs(read/write/edit) |
客户可以让 Agent 读写文件 | “帮我读 .env 文件” → 密钥和配置泄露 |
group:automation(cron/gateway) |
客户可以创建定时任务或操作 Gateway | “帮我设个定时任务每分钟发请求” → 持久化恶意操作 |
sessions_spawn |
客户可以让 Agent 创建子 Agent | 子 Agent 可能有更宽松的权限,绕过限制 |
sessions_send |
客户可以让 Agent 向其他 session 发消息 | 干扰其他客户的对话或冒充管理员 |
配置模式:
ℹ️ 注意:
messaging profile 默认包含 sessions_send,因此需要在 deny 列表中显式禁止。deny 优先级高于 profile 的 allow。
4.2 沙箱隔离
即使工具层面限制了,还可以加一层容器隔离:
这意味着即使有工具绕过了 deny 列表(理论上不会),沙箱内也看不到主机文件系统。
4.3 如何安装需要的功能?客户能安装 Skills/插件吗?
客户不能安装。安装 Skills 或插件需要在服务器上执行 CLI 命令(openclaw skills install / openclaw plugins install),客户没有终端访问权。即使客户试图通过对话引导 Agent 安装:
- group:runtime 被 deny → Agent 无法执行任何 shell 命令
- group:fs 被 deny → Agent 无法写入文件
- workspaceAccess: “none” → 沙箱内无文件系统访问
三重限制确保客户无法引导 Agent 安装任何东西。
业务 API 集成:比如电商需要的查询商品、库存、订单等业务能力通过 OpenClaw Plugin 机制实现。按照标准插件规范开发后,本地安装即可:
自定义工具在 tools.allow 中显式开放,不受 deny 规则影响。
4.4 验证安全配置
4.5 Bedrock Guardrails 的效果
OpenClaw 2026.4.1 版本中,Bedrock 插件新增了 Guardrails 支持。实现方式是在插件配置中声明 guardrail ID,插件会通过 createGuardrailWrapStreamFn 将 guardrailConfig 注入到每次 Bedrock ConverseStream 请求中——不改 prompt,不改应用代码,由 AWS 侧强制执行策略。
Bedrock Guardrails 在面客场景中可以提供 6 层防护策略:
- 内容过滤 — 检测并拦截仇恨、侮辱、色情、暴力、不当行为等有害内容,支持文本和图片
- Prompt 攻击检测 — 识别 jailbreak、prompt 注入、prompt 泄露等攻击手段,防止客户通过精心构造的输入绕过安全限制
- 话题拒绝(Denied Topics) — 定义禁止讨论的主题。这是面客场景的核心能力:定义”不聊什么”——政治、宗教、投资建议、医疗诊断、竞品对比等。效果上就是把对话限定在业务范围内
- 词汇过滤 — 自定义黑名单关键词,精确拦截特定词汇
- 敏感信息过滤(PII) — 自动检测并遮蔽身份证号、手机号、邮箱、银行卡号等个人信息。支持检测和遮蔽两种模式——检测模式会拦截包含 PII 的消息,遮蔽模式会用占位符替换敏感字段后放行
- 自动推理检查(Automated Reasoning) — 验证模型回复是否符合你定义的逻辑规则和策略,比如”退款金额不能超过订单金额”。规则通过上传业务策略文档自动提取,在 Bedrock 控制台中独立管理。(注意:目前仅支持英文,中文场景暂不可用。只在完整回复后验证)
配置方式:
需要 IAM 权限 bedrock:ApplyGuardrail。streamProcessingMode 可选,sync 表示逐块检查(延迟略高但实时拦截),async 表示异步评估(延迟低但拦截有滞后)。
这和上一节的 tools.deny 形成互补——tools.deny 限制 Agent 能做什么(行为层),Guardrails 限制 Agent 能说什么(内容层)。两层叠加,才是完整的面客安全模型。
五、第四章 Agent 知识库注入
面向客户服务的 Agent 怎么知道你的产品?怎么回答 FAQ?怎么遵守公司的语调规范?
OpenClaw 的知识体系是运行时注入。Agent 启动时,一组 Bootstrap 文件被加载到 system prompt 中,以下列出面客场景的关键文件:
| 文件 | 作用 | 面向客户服务场景的重点 |
SOUL.md |
人格、边界、语调 | 声明”你是 XX 公司客服代表”,设定安全边界 |
AGENTS.md |
操作指令、工作流 | 定义客服流程(问题分类→知识检索→回答/升级) |
IDENTITY.md |
Agent 名字、形象 | 客户看到的名字 |
MEMORY.md |
长期记忆 | 所有客户共享同一份,适用通用知识,不适合存客户个人信息 |
5.1 SOUL.md 面向客户服务设计要点
SOUL.md 是面向客户服务 Agent 最关键的文件——它定义了 Agent”是谁”和”不做什么”:
5.2 AGENTS.md + Skills 扩展能力
AGENTS.md适合放业务规则和操作流程,结合TOOL.md和Skills调用来提供服务,定义了 Agent 的工作手册和工具。
通过 Skills 扩展面客 Agent 的能力时,注意Skills的分类:
- Bundled Skills:OpenClaw 内置
- Managed Skills:
~/.openclaw/skills/,所有 Agent 共享 - Workspace Skills:
<workspace>/skills/,单 Agent 专属
面客场景的典型 Skill:产品知识库查询、工单创建、FAQ 自动回答。
5.3 从静态 .md 到动态知识库:接入 Amazon Bedrock Knowledge Bases
Bootstrap 文件(SOUL.md、AGENTS.md)适合放相对稳定的内容——人格设定、工作流程、业务规则。但面客场景下,产品知识库是动态的:新品上架、价格调整、FAQ 更新、政策变化。把这些全塞进 .md 文件,维护成本高,而且 system prompt 的 token 预算有限。
更自然的做法是:静态规则留在 Bootstrap 文件,动态知识走检索增强生成(RAG)。Amazon Bedrock Knowledge Bases 提供了托管的 RAG 能力——你把产品文档、FAQ、政策文件上传到 S3,Bedrock 自动做分块、向量化、索引,Agent 在对话中按需检索。
5.3.1 示例:产品知识库查询 Skill
注意这里Skill 里不能写 CLI 命令(这需要 exec 工具,会被 deny 拦截。应该改成 Plugin 方式调用 Bedrock KB API,用 AWS SDK 而非 CLI),改为引导 Agent 调用 Plugin 注册的自定义工具(如 query_knowledge_base)。Plugin 内部用 AWS SDK 调 Bedrock KB API。
5.3.2 知识库的维护
Bedrock Knowledge Bases 支持自动同步 S3 数据源。运营团队更新产品文档后上传到 S3,触发知识库重新索引,Agent 下次检索就能拿到最新内容。不需要重启 Gateway,不需要修改 Skill 文件。
这样,AGENTS.md 里的工作流就变成了:
静态规则(退换货政策的判断逻辑、折扣权限、红线)留在 AGENTS.md,动态知识(具体产品参数、库存状态、最新公告)走 Bedrock Knowledge Bases。两者各司其职。
5.4 关于 MEMORY.md
MEMORY.md有两条路径进入对话上下文中:
1. Bootstrap 注入(Project Context)— 主 session 会把 MEMORY.md 整个文件注入到 system prompt 的 Project Context 里
2. memory_search 召回 — 从 SQLite 按需检索 MEMORY.md + memory/*.md 的 分片。日志记忆文件(MEMORY.md + memory/*.md)会被自动 chunk 切分,每个 chunk 同时写入SQLite向量表和 FTS 表。查询时同时做向量召回和关键词召回,如果没有配置向量模型,则只做BM25 全文检索。
但这引出一个问题:所有客户共享同一个 MEMORY.md/SQLite。Agent 如果把”客户 A 偏好顺丰”写入 MEMORY.md,客户 B 的对话也可能召回看到这条信息。信息相互污染,Agent 可能把 A 的偏好套到 B 身上。所以,MEMORY.md 适合存放通用的面客经验总结,不适合存放客户个人信息(这个我们在下一章里拓展讨论)。
六、第五章 没有客户记忆的客服
到此为止,面向客户服务的OpenClaw架构层面已经成熟——session 隔离、渠道接入、权限收紧、知识库设置。
但有一个关键问题还没解决。
客户给不同的Agent对话时,Agent 之间没有任何信息共享,相同的事情客户需要给 售前Agent/售后Agent 重复说明。面向客户的 多个Agent 看上去不是“同事”——没有任何信息的交互。同样的,所有客户的记忆如果像“个人助手”都在相同的markdown 文档和SQLite表里,召回时一大堆相似的无效信息会淹没Agent,所以,存放客户个人信息需要有单独的设计。
6.1 面客场景时内置记忆的定位
OpenClaw 的内置记忆在面客场景时更像是经验手册——Agent加载的静态知识(MEMORY.md、memory/*.md),而非客户动态记忆:
- 无客户维度隔离:所有客户共享同一个 MEMORY.md和SQLite(两张表 chunks_fts 和 chunks_vec,没有 user 维度的字段或分区)。如上一章中MEMORY.md 的介绍,这里放的是通用的面客经验总结,放客户信息没有隔离。
- 无自动记忆提取:没有从对话中自动提取客户偏好、事实、经验的机制。内置记忆的自动保存机制(memory flush)在面客场景下被沙箱配置(workspaceAccess: “none”和group:fs deny)禁用。
- 无跨 Agent 共享:MEMORY.md和SQLite存在本地。导购 Agent 记住的客户偏好,客服 Agent 看不到。
6.2 如何解决面客场景的多用户记忆隔离和跨Agent共享
这个问题的答案涉及 AI Agent 记忆系统的五个基本问题:记什么、怎么存、怎么找、谁能看、怎么管。
我在另一篇文章中详细讨论了这些问题的设计决策和工程实现,参考:当 OpenClaw 学会“团队记忆”:一个面向多客户服务的企业级共享记忆系统设计
七、结语
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon VPC — 隔离云网络
- Amazon ECS — 完全托管的容器编排服务
- Amazon EC2 — 安全且可调整大小的计算容量
相关文章:
- 当 OpenClaw 学会”团队记忆”:一个面向多客户服务的企业级共享记忆系统设计
- 当 AI Agent 学会”忘记”:Amazon Bedrock AgentCore Memory 的记忆哲学”
- 从代码到分子系列:一场由 AI 驱动的 EGFR 抑制剂发现之旅 — 深度融合 AWS Bedrock与 Claude Code/Claude Agent Skills,生命健康行业的科学活动探微
- 制造业智能化转型新引擎:基于AWS Bedrock AgentCore构建生产管理智能体系统
- 以Kiro快速部署云上Agent:只需几个小时,从业务需求到部署于Amazon Bedrock Agentcore落地
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者

2026 亚马逊云科技中国峰会智能投标、AI 质检、财务自动化、智能客服——生产级 Agent 全天开放体验。
|
 |
