亚马逊AWS官方博客
当 OpenClaw 学会”团队记忆”:一个面向多客户服务的企业级共享记忆系统设计
摘要:本文围绕 AI Agent 在多客户、多 Agent 协作场景下的”记忆困境”,介绍基于 Amazon AgentCore Memory 的 OpenClaw 企业级共享记忆插件 memory-agentcore,逐一拆解记忆系统的五个核心问题:记什么(Amazon AgentCore 4 策略自动提取 + 本地三层噪音预过滤)、怎么存(Event → Memory Record 的全托管数据路径)、怎么找(auto-recall 自动召回 + 肘点算法分数间隙过滤)、谁能看(层级命名空间 + actorId 驱动的最小权限隔离)、怎么管(8 个 Agent 工具 + 9 个 CLI 命令的全生命周期管理)。架构基于 Amazon Bedrock AgentCore Memory 构建,采用三层记忆模型(上下文层 / 本地记忆层 / 云端共享层)叠加设计,在面客模式下通过 peerId 实现记忆按客户自动隔离、跨 Agent 天然共享。
目录
一、引言:AI Agent 的”记忆困境”
在上一篇文章中,我们介绍了如何用 OpenClaw 构建面向客户服务的 AI Agent。本文继续这个话题,聊聊多客户、多 Agent 场景下的共享记忆系统设计。
大语言模型(LLM)上下文窗口是有限的,我们不能在一个会话里解决所有的问题。新的任务/需求往往需要创建新的会话,规避上下文窗口限制,同时也减少“无效信息污染”,提升对话质量。Agent 在跨会话时会清空上下文而”失忆”。上一次对话中建立的理解、达成的共识、用户表达的偏好,在新会话开始时都归零了。
对于个人助手 Agent 的场景,这个问题已有成熟解法。以 OpenClaw 内置的 memory-core 为例:Agent 将重要信息写入本地 Markdown 文件(MEMORY.md、memory/*.md),通过混合 BM25 + 向量搜索检索。另一个选项是内置的 memory-lancedb,使用纯向量搜索,但额外提供 auto-recall/auto-capture 自动化能力。这两个组件都足以让一个个人助手”记住”你的偏好和上下文中的重要信息。
但当场景扩展到多客户多 Agent 协作时,情况完全不一样。 这不是模型能力的问题,也不是 prompt 工程的问题,而是一个记忆架构的问题。单 OpenClaw Agent 的本地记忆是”个人笔记本”,而企业多 Agent 场景需要的是”团队知识管理系统”。在面向多客户的场景时,不同客户的记忆混合在同一份 Markdown 文档里,就像桃谷六仙一起往令狐冲体内灌注真气——每个人的偏好都在打架,Agent 不走火入魔才怪。
就像企业从”每个人记自己的笔记”演进到”共享知识库 + 权限管控 + CRM”,Agent 的记忆系统也需要同样的演进。
一个完整的故事:小林和三个 Agent
让我们把这个问题具体化。先说明一点:一个设计良好的业务系统(订单、CRM、工单系统)是基础。记忆系统不能代替这些业务系统——而是提取那些不在任何数据库字段里的、非结构化的、在对话中自然流露的认知。
第一幕:导购记了小本本,但是会迷糊
小林在电商平台上咨询了一款桑蚕丝围巾,准备母亲节送给妈妈。在对话过程中,他随口提到了几件事:
“我妈对化纤过敏,所以必须真丝的。”
“她审美偏保守,素色就好,别太花哨。”
“上次在你们这买的那条羊绒围巾她很喜欢,质量不错。给长辈买东西,还是要注重质感。”
这些信息不会出现在订单系统的任何字段里——订单只记录 SKU、数量、地址、支付状态。“化纤过敏”不是商品属性筛选条件,“审美偏保守”不是订单备注,“上次买的羊绒围巾她很喜欢”更不会写进任何结构化数据库。
对话结束,订单创建,一切顺利。导购 Agent 把这些偏好写进了自己的 MEMORY.md。嗯,几千个客户不同的偏好都混在这个markdown文档里,但导购记录不是像结构化数据库一样,记在小林的条目下。小林的“我妈喜欢素色”和其它客户的“喜欢鲜艳颜色”混在一起,这些相互冲突相互污染的信息会让导购 Agent 崩溃。
第二幕:客服什么都不知道
围巾到货后,小林发现颜色比商品图偏深,联系客服 Agent 咨询换货:
小林:“颜色比图片深不少,我妈不太喜欢,能换个浅色的吗?”
客服 Agent:“好的,我帮您申请换货。我们这款有米白、浅灰、藕粉三个浅色可选,每个颜色都有三种花纹可选。您看哪个合适?”
小林:“她喜欢素色的,我之前说过的”
客服 Agent:“抱歉,我这边只能看到您的订单信息。我推荐另一款,这款纯色围巾特别推荐给您,颜色很温柔百搭,素色的设计反而更显气质。面料是腈纶仿羊绒面料,摸起来很舒服,轻盈不厚重,春秋冬都能戴。而且材质不怕水洗,颜色持久如新,特别实用。”
小林:“腈纶是化纤吧?我说过我妈对化纤过敏的。算了,直接退货吧”
客服 Agent 能查到订单——这是业务系统的能力。但它查不到”审美偏保守、喜欢素色”这个偏好,也不知道”化纤过敏”这个关键信息,因为这些都记在导购 Agent 的本地 MEMORY.md 里,客服 Agent 无权访问。即使能访问,召回的也是和前面一样的一团乱麻,倒不如不召回。
第三幕:经验无法传承
半年后,小林又来给妈妈买生日礼物。这次他吸取教训,直接告诉导购 Agent:
小林:“上次买的围巾色差很大,换货的时候客服还给我推荐化纤的,体验很差。这次帮我看看有没有真丝的丝巾,颜色要准的。”
但这是一个新的导购 Agent 实例——它对半年前的那次不愉快一无所知。它不知道这个客户曾经因为色差换过货,不知道客服推荐化纤踩过雷,也不知道平台上围巾类商品的色差是个高频投诉点。
事实上,过去半年里已经有几百个类似的色差投诉。如果系统能从这些对话中提炼出”围巾类商品色差是高频问题,建议导购主动提醒实物可能偏深”这样的经验,就能在源头降低问题发生率。但每个 Agent 的经验都是孤立的——它们各自处理了几十个类似案例,却无法汇聚成团队级别的认知。
故事背后的五个系统性问题
小林的遭遇暴露了五个环环相扣的问题——注意,这些都是业务系统(订单、CRM、工单)覆盖不到的非结构化认知层面的问题:
| # | 故事节点 | 暴露的问题 | 系统性根因 | 本质 |
| 1 | “化纤过敏”可能没有被提取保存 | 隐性信息丢失 | 记什么 (Extraction) | 从对话流中提取有价值信息,过滤噪音 |
| 2 | 导购的记忆 客服看不到 | 记忆孤岛 | 怎么存 (Storage) | 持久化存储,跨会话、跨 Agent 可用 |
| 3 | 客服需要重新询问 | 记忆断联 | 怎么找 (Retrieval) | 在正确的地方找到正确的记忆 |
| 4 | 几千个客户的偏好混在同一份文件里 | 记忆污染 | 谁能看 (Access Control) | 多用户的记忆隔离、多Agent共享权限管理 |
| 5 | 色差投诉的经验无法提取 | 经验总结及后续可能的更新 | 怎么管 (Lifecycle) | 反思、更新、纠错、遗忘、共享 |
这 5 个问题恰好也是企业知识管理的经典命题:会议纪要该记哪些要点?存在本地还是飞书文档?需要时能不能搜到?哪些人能看?过时信息怎么归档?
最近我开发了一个 OpenClaw 的企业级共享记忆插件 memory-agentcore (https://github.com/aws-samples/sample-openclaw-agentcore-memory),本文以该插件为案例,逐一展开这 5 个问题的设计决策和工程实现。
二、第一章 架构定位:叠加而非替代
小林的故事里,导购 Agent 已经在用 memory-core 记笔记了。问题不是”没有记忆”,而是”记忆没法用”。所以第一个要回答的问题是:新的记忆层需要什么功能?
在深入 5 个问题之前,先理解 memory-agentcore 在 OpenClaw 生态中的位置。这个定位决策是整个系统设计的基石。
2.1 两层记忆模型
OpenClaw 的记忆体系可以理解为两个独立但协同的层:上下文层和本地记忆层。这两个层都是为单用户设计——给 Agent 自己用的,不区分”谁在跟我说话”。memory-agentcore则在此基础上实现了“多用户记忆隔离”和“多Agent记忆共享”,添加了云端共享层。

[图1 memory-agentcore 添加了云端共享层] |
三层各管不同维度的数据:上下文层管”当前对话发生了什么、短期记忆、如何组装上下文”,本地记忆层管”记住了什么、召回需要的长期记忆”,云端共享层管”共享了什么、根据策略提取记忆、如何实现用户隔离和跨Agent共享”。
2.2 内置记忆组件的多用户盲区
在深入 memory-agentcore 之前,有必要理解 OpenClaw 内置的两个记忆层组件为什么无法满足面客场景。
2.2.1 memory-core:基于文件的记忆搜索
memory-core 是默认使用的记忆组件,本质是工作区文件索引。它通过 memory_search 和 memory_get 两个工具,对 Agent 工作区下的 MEMORY.md 和 memory/*.md 文件进行混合 BM25 + 向量搜索。
当多个客户与同一个 Agent 对话时,所有客户的信息都混在同一个 MEMORY.md 中——客户 A 的偏好可能被召回给客户 B。这不仅是隐私问题,也是功能缺陷:搜索结果被其他客户的无关信息污染,降低精准度。
2.2.2 memory-lancedb:本地向量数据库
memory-lancedb 是可选的记忆组件,使用 LanceDB 存储向量嵌入,提供 memory_recall、memory_store、memory_forget 三个工具,支持 auto-recall(自动注入)和 auto-capture(自动捕获)。
memory-lancedb 和 memory-core 一样,同样缺失多用户隔离能力——所有客户的记忆存在同一个 LanceDB 实例中,检索时无法按用户过滤。
2.2.3 三个组件的面客能力对比
| 能力 | memory-core | memory-lancedb | memory-agentcore |
| 存储引擎 | 本地 Markdown 文件 | 本地 LanceDB 向量库 | AWS AgentCore 云端 |
| 自动召回 | ❌ 需手动调工具 | ✅ before_agent_start | ✅ before_prompt_build |
| 自动捕获 | ❌ 需 Agent 写文件 | ✅ 正则触发词匹配 | ✅ Amazon 4 策略提取 |
| 多用户隔离 | ❌ 共享文件 | ❌ 共享 dbPath | ✅ actorId → 命名空间 |
| 跨 Agent 共享 | ❌ | ❌ | ✅ 命名空间 + agentAccess |
| 离线可用 | ✅ | ✅ | ❌ 依赖云端 |
| 适合场景 | 单用户 workspace 笔记 | 单用户长期记忆 | 多用户面客 + 多 Agent 协作 |
这就是 memory-agentcore 存在的核心理由:内置组件解决单用户记忆,memory-agentcore 解决多用户记忆隔离与跨 Agent 共享。 三者不是竞争关系,而是服务不同维度的需求。
2.3 “general” 插件:零侵入式增强
OpenClaw 的插件系统有两个独占 Slot:Memory Slot 和 Context Engine Slot。同一时间只能有一个插件占据每个 Slot。memory-core(或memory-lancedb)已占用 Memory Slot,OpenClaw 内置的上下文管理引擎 legacy(或第三方插件lossless-claw)则会占用 Context Engine Slot。
memory-agentcore 选择注册为 kind: "general" —— 不占用任何 Slot,与两者和平共存。
这个决策的核心逻辑: – Memory Slot 是独占的 —— 如果占用就意味着替换 memory-core – kind: "general" = 安装即增强,卸载不影响
我们在 《把 OpenClaw 从个人助手变成客服:一次信任模型的翻转》这篇博客里提到过:面向客户的 Agent MEMORY.md适合放 「去客户化的通用经验」,不适合存放客户个人信息。memory-agentcore插件补齐了这个缺失,实现的是「关于某个客户的事」并完善多用户记忆隔离和多 Agent 共享机制。
三、第二章 记什么:从对话流中提炼价值
小林随口说了一句”我妈对化纤过敏”——这不是订单字段,不是商品属性,但对后续每一次推荐都至关重要。“化纤过敏”是事实,“审美偏保守”是偏好,“上次买的羊绒围巾她很喜欢”是经验。如果只是把整段对话原样存下来,检索时就是一团浆糊。这一章解决的是:怎么把对话流里的金子筛出来,同时把沙子挡在外面。
核心矛盾:记太多 = 噪音淹没信号;记太少 = 丢失重要信息。
3.1 Amazon 托管提取引擎
memory-agentcore 在”记什么”这个问题上做了一个关键决策:信任 AWS 的托管提取引擎,本地专注噪音预过滤。
插件使用Amazon Bedrock AgentCore Memory,其内置 4 种提取策略(Extraction Strategy),对每次 Agent 会话的对话内容并行运行:
| 策略 | 提取什么 | 例子 |
| SEMANTIC | 事实和知识 | “SKU-A003 蓝色款目前缺货,预计4月5日补货” |
| USER_PREFERENCE | 用户偏好和选择 | “偏好顺丰快递,愿意补差价” |
| EPISODIC | 结构化经验 + 跨会话反思 | “客户曾要求退定制商品被拒而投诉 → 下次提前强调不退换政策” |
| SUMMARY | 会话级别滚动摘要 | 每个 session 的精炼总结 |
这意味着插件不需要自建 LLM 提取管线。4 种策略并行运行,自动化程度高。实现”开箱即用 + 零运维”。
3.2 本地噪音预过滤:三层防线
提取由 Amazon 托管,但噪音预过滤是本地的。插件在将对话发送到 AgentCore Memory之前,以及在检索结果注入 prompt 之前,分别经过精心设计的过滤管道。
3.2.1 第一层:自适应检索门控(Adaptive Retrieval Gating)
并非每条用户消息都值得触发一次云端检索。以下类型的消息直接跳过:
- 纯问候:“你好”、“hi”
- 命令:以 / 开头的 slash command
- 心跳信号:“…”、“.”
- 纯表情:emoji
- 过短消息:英文 < 15 字符,CJK < 6 字符
但如果消息中包含记忆相关关键词(“remember”、“previously”、“记得”、“之前”),即使很短也会触发检索。这种语言感知的门控设计确保了不会因为”你还记得上次我们讨论的方案吗?“这类短查询而漏掉检索。
3.2.2 第二层:双语噪声过滤(Bilingual Noise Filter)
面向中国市场的 Agent 必须处理中英文混合输入。噪声过滤器覆盖了多类低价值模式:
- 问候语(“谢谢” / “thank you”)
- 心跳信号(省略号、单字符)
- LLM 自我声明(“作为 AI 助手…”)
- 拒绝回复(“抱歉我无法…”)
关键设计:运维人员可以通过配置 bypassPatterns(强制通过)和 noisePatterns(强制过滤)的正则表达式来自定义规则,无需修改代码。例如,可以配置 "^Error:" 作为 bypass pattern,确保错误报告永远不会被过滤掉。
3.2.3 第三层:分数间隙检测(Score Gap Detection / Elbow Point)
传统的 top-K 检索只关心”取前 N 条”,不关心结果质量的断崖式下降。例如:

[图2 固定 top-5 可能会有低质量结果] |
如果简单 top-5 返回,后两条低质量结果会被注入 prompt,浪费宝贵的上下文窗口甚至引入噪声。
memory-agentcore 使用肘点算法(也称拐点法,Elbow Point Detection):
- 计算相邻分数的跌幅序列:
[0.03, 0.04, 0.43, 0.05] - 计算平均跌幅:
0.1375 - 阈值 = 平均跌幅 x 乘数(默认 2.0)=
0.275 - 第一个超过阈值的跌幅在第 3→4 位之间(0.43 > 0.275)
- 截断:只返回前 3 条
这让系统在不同查询、不同数据分布下都能自适应地找到”质量断崖”,避免一刀切的 top-K 设定。
四、第三章 怎么存:从对话到云端的数据路径
导购 Agent 把”喜欢素色”写进了自己的 MEMORY.md——然后客服 Agent 推荐换货时完全看不到这些信息。问题的根源:本地文件存储天然无法跨 Agent 共享。需要解决:对话信息提取之后,存到哪里、怎么存,才能让需要的 Agent 都能找到。
4.1 Auto-Capture → Event → Memory Record路径
memory-agentcore 的存储设计,数据从对话到可检索记忆的完整路径如下:

[图3 Hook触发 auto-capture → Event → 提炼 Memory Record 完整过程] |
插件负责“投喂”对话 Event,具体从哪条对话中提取什么、存到哪个命名空间,全部由 Amazon AgentCore 引擎根据配置的策略自动决定。
4.2 两层数据模型
理解 Events 和 Memory Records 的区别很重要:
| 维度 | Events | Memory Records |
| 是什么 | 原始对话的每轮摘要 | 4 种策略提取后的精炼记忆 |
| 生命周期 | 90 天过期(eventExpiryDays 可配置) | 持久化存储(不过期) |
| 用途 | 提取管线的输入源 | auto-recall 和工具检索的目标 |
| 直接检索? | 不需要——当前 session 对话已在上下文窗口中 | 需要——这是跨 session 记忆的核心 |
Events 是“原材料 – 原始对话记录”,Memory Records 是“成品 – 使用策略提取后的记忆”。Events 存在的意义是喂给提取管线,提取完成后原始 Events 可以按 TTL 自动清理。
4.3 全托管的基础设施
存储层面的核心选择:Amazon Bedrock AgentCore Memory全托管。
- 存储和其它处理全部由 AWS 管理
- KMS 静态加密 + TLS 传输加密
- 弹性扩展,无需管理容量、分片、副本
企业用户不需要额外部署其它基础设施,开箱即可使用。
4.4 文件同步(可选能力)
memory-agentcore 提供了将本地文件同步到云端的能力,但默认不同步任何文件:
文件同步的使用场景主要是将 Project Context 之外的文件(如 docs/流行趋势product-trending.md、guides/产品搭配指南product-pairing.md)同步到云端,供 Agent 检索。
同步机制也由Hooks触发,使用 SHA-256 哈希做变更检测——只有内容实际变化的文件才会触发 API 调用,状态持久化到 .agentcore-sync.json 防止重复同步。
五、第四章 怎么找:自动召回与智能检索
小林联系客服换货时,客服需要在毫秒内知道”这个客户的妈妈对化纤过敏、喜欢素色”——不是搜索所有客户的记忆,而是精准定位到小林的记忆。这个过程必须是自动的,不能指望客服 Agent 每次都记得先调一下搜索工具。这一章解决的是:怎么在正确的时机、从正确的范围里、找到正确的记忆。
核心矛盾:精准度 vs 延迟 vs 成本。
5.1 Auto-Recall:无感知的自动召回
memory-agentcore 的检索核心是 before_prompt_build hook——在每次模型执行前自动触发,对 Agent 和用户完全透明:
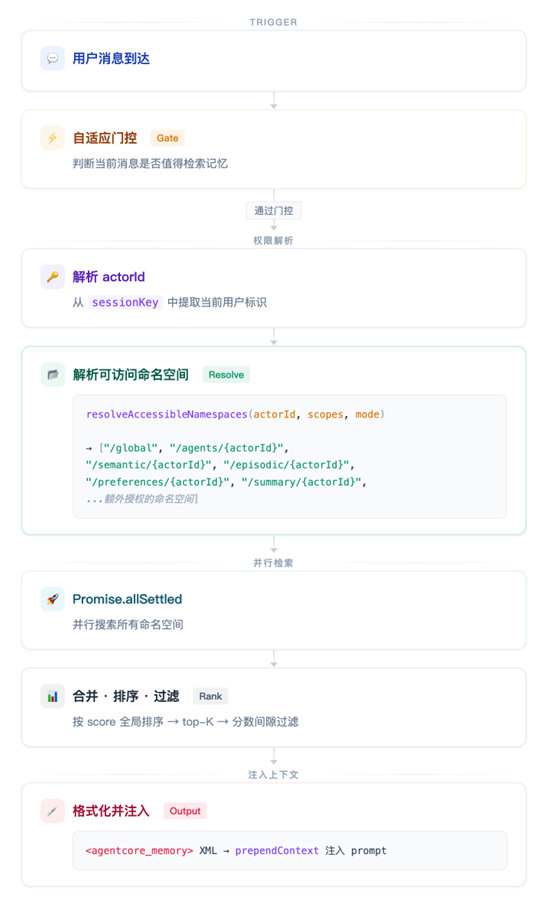
[图4 Agent 在回复前通过 Hook 触发auto-recall 召回记忆的完整过程] |
Agent 不需要知道记忆来自哪个命名空间、经过了几层过滤——它只在 prompt 开头看到一段相关的记忆上下文。
5.2 与 memory-core 的互补
memory-agentcore 与 memory-core 两个记忆系统的检索能力是互补的,而非替代的:
| 维度 | memory-core | memory-agentcore |
| 搜索类型 | 混合 BM25 + 向量语义搜索 | AWS托管搜索 |
| 延迟 | 毫秒级(本地 SQLite) | 毫秒级(云端 API) |
| 范围 | 本 Agent 工作区文件 | 所有可访问命名空间 |
| 触发方式 | 按需(Agent 主动调用 memory_search) | 自动(before_prompt_build)+ 按需(agentcore_recall) |
Agent 在一次对话中可以同时使用两者:memory_search 搜索本地预置的去客户化的通用经验,agentcore_recall 搜索云端当前对话客户的独特记忆。两者返回不同维度的信息,Agent 综合使用。
六、第五章 谁能看:命名空间与权限治理
几千个客户的偏好混在同一份 MEMORY.md 里,搜索”围巾偏好”可能返回别的客户的信息。同时,导购、客服两个 Agent 需要能共享同一个客户的记忆。Agent 既需要私有记忆,又需要跨 Agent 共享,如何实现?
这是企业落地的核心关切——在多 Agent 环境中,谁能看到什么记忆,谁能写入什么记忆?
6.1 层级命名空间
memory-agentcore 使用 Scope 字符串到 AgentCore 命名空间(Namespace)的映射来组织记忆:
| Scope 字符串 | 命名空间 | 典型用途 |
global |
/global |
全局共享知识——所有 Agent 可见 |
agent:<id> |
/agents/<id> |
Agent 私有记忆 |
project:<id> |
/projects/<id> |
项目级共享(如电商平台知识) |
user:<id> |
/users/<id> |
用户级偏好——跨 Agent 跟随用户 |
custom:<id> |
/custom/<id> |
自定义场景(团队、部门等) |
这种设计让权限管理可以按组织结构灵活映射:Agent 是个人,Project 是项目组,User 是客户。个人使用时,命名空间使用/agents/;项目组内需要共享内容时,使用/projects/,可共享给多个 Agent 访问;面向客户服务时,每个客户有单独的/users/,且多个 Agent (比如售前导购/客户服务/履约)都可以访问这个客户命名空间的内容,实现共享。
6.2 最小权限原则
每个 actorId 默认只能访问: – /global(全局共享,始终可读可写) – 自己的主命名空间 + 4 个策略命名空间
跨 actorId 访问需要显式配置 agentAccess。
安全回退:无效的 scope 字符串不会导致错误或权限升级,而是回退到 global——最小权限。
6.3 面客场景:actorId = 客户 ID
AWS AgentCore 的设计意图是 actorId = 终端用户。memory-agentcore 遵循这个设计:
当 OpenClaw 的 dmScope 配置为 per-peer 或 per-channel-peer 时,sessionKey 包含客户标识(:direct:<peerId>)。插件自动提取 peerId 作为 actorId,使记忆天然按客户维度隔离和共享:
| 条件 | actorId | 记忆维度 |
| 员工助手(dmScope: main) | agentId | 按 Agent 隔离 |
| 面客 DM(dmScope: per-peer) | peerId(客户 ID) | 按客户隔离 |
群聊(无 :direct: 段) |
agentId(降级) | 按 Agent 隔离 |
回到引言的电商场景——在面客部署下:
不同 Agent 服务同一客户时,actorId 相同,提取和检索自动共享——无需配置 agentAccess。
不同客户之间,actorId 不同,命名空间天然隔离——即使客户通过 prompt injection 尝试访问其他客户的记忆,代码层面的权限检查(isScopeReadable)会直接拒绝。
6.4 三层安全防线
面客场景下,记忆安全不依赖 LLM 行为,而是由代码层面的三层防线保障:
| 防线 | 负责方 | 防什么 |
Gateway tools.profile |
OpenClaw Gateway(服务端) | 白名单机制——"messaging" profile 只放行消息相关工具,插件工具(agentcore_store、agentcore_forget 等)全部被拦截,用户不能修改记忆 |
Gateway tools.deny |
OpenClaw Gateway(服务端) | 阻止 Agent 调用文件/命令等危险工具(group:runtime、group:fs 等) |
插件 isScopeReadable/Writable |
memory-agentcore 代码 | 阻止访问当前 actorId 以外的命名空间 |
面客场景的典型 Gateway 配置:
关键设计:Hooks 不是 tools。before_prompt_build(auto-recall)和 agent_end(auto-capture)是 Agent 生命周期事件,不经过工具权限管线。即使所有 agentcore 工具被 profile 屏蔽,自动化双循环(auto-recall + auto-capture)仍然正常运行。面客模式下,记忆的读写完全由 hooks 驱动,无需暴露任何手动工具。
客户无法伪造 peerId——它来自 Channel 身份(手机号、Telegram ID),由 OpenClaw 写入 sessionKey,插件从 sessionKey 提取。整个链路都是服务端控制。
6.5 与 AWS 的进一步集成
命名空间是客户端的权限控制。在此之上,AWS 原生提供了服务端的安全保障:
| 能力 | 机制 |
| API 级访问控制 | IAM 策略——控制哪些 AWS 身份可以调用 AgentCore API |
| 操作审计 | CloudTrail——记录每次记忆操作(谁、什么时候、做了什么) |
| 数据加密 | KMS 静态加密 + TLS 传输加密 |
对于需要满足 SOC2、HIPAA 等合规要求的企业,这些能力是必选项,为企业提供了坚实的保障。
七、第六章 怎么管:记忆的全生命周期
还记得那个色差投诉的规律吗?几百个客服 Agent 各自处理了类似的问题,却无法汇聚成”围巾类商品色差是高频投诉点”这样的团队经验。记忆不是写入就完事了——它需要能反思,能更新、能纠错、能跨 Agent 传承经验。
记忆不是”写入即忘”。和企业知识管理一样,Agent 的记忆也需要更新、纠错、删除、共享——完整的生命周期管理。
7.1 8 个 Agent 工具
memory-agentcore 提供了 8 个 LLM 可调用的工具,覆盖记忆的完整生命周期。Agent 根据对话上下文自动判断何时调用哪个工具:
| 工具 | 操作 | 典型场景 |
agentcore_store |
主动存储重要信息 | 用户说”我们决定使用 DynamoDB”,Agent 识别为关键决策并保存 |
agentcore_recall |
语义搜索记忆 | 用户问”上次我们讨论的 API 方案是什么?” |
agentcore_correct |
原地更新记忆 | “截止日期改了,应该是 4 月 15 号” |
agentcore_forget |
删除记忆(预览→确认) | “删除关于旧项目的记忆”,支持按 ID / 按搜索 / 清空 scope 三种模式 |
agentcore_search |
列表/过滤记录 | recall 因语义索引延迟返回空时的回退方案 |
agentcore_episodes |
搜索情境记忆 | 遇到类似技术问题时,搜索过去处理同类问题的经验 |
agentcore_share |
跨命名空间推送 | 销售 Agent 将客户偏好推送到客服和履约的命名空间 |
agentcore_stats |
连接状态和统计 | 排查问题时查看各命名空间的记忆分布 |
其中 agentcore_store 和 agentcore_recall 是最常用的两个。auto-capture 和 auto-recall 已经在后台自动处理大部分场景,手动工具是对自动化的补充——当 Agent 需要更精确的控制(指定 scope、策略、主动存储关键决策)时使用。
面客场景注意:上述 8 个工具面向员工助手模式(tools.profile: "full")。在面客部署中,Gateway 的 profile: "messaging" 会自动拦截所有插件工具——客户无法诱导 Agent 调用 agentcore_forget 删除记忆或 agentcore_share 污染其他命名空间。面客模式下的记忆读写完全由 auto-recall/auto-capture hooks 驱动,无需暴露手动工具。
7.2 9 个 CLI 命令
除了 Agent 工具,还有面向运维人员的 CLI 命令:
这些命令降低了调试门槛——当 Agent 行为不符预期时,运维人员可以直接检查记忆内容、手动修正或清理,而不需要通过对话间接操作。
与 Agent 工具的区别:CLI 命令通过终端执行,不是 LLM 工具,不受 Gateway tools.profile 管控。即使面客场景下 Agent 的 agentcore 工具被 profile: "messaging" 全部拦截,运维人员仍可通过 CLI 完整管理记忆——检查、修正、清理、同步。这确保了运维团队在任何部署模式下都保持对记忆系统的完整控制权。
7.3 自动化双循环
整个系统的自动化运行靠两个 hook 驱动的循环:
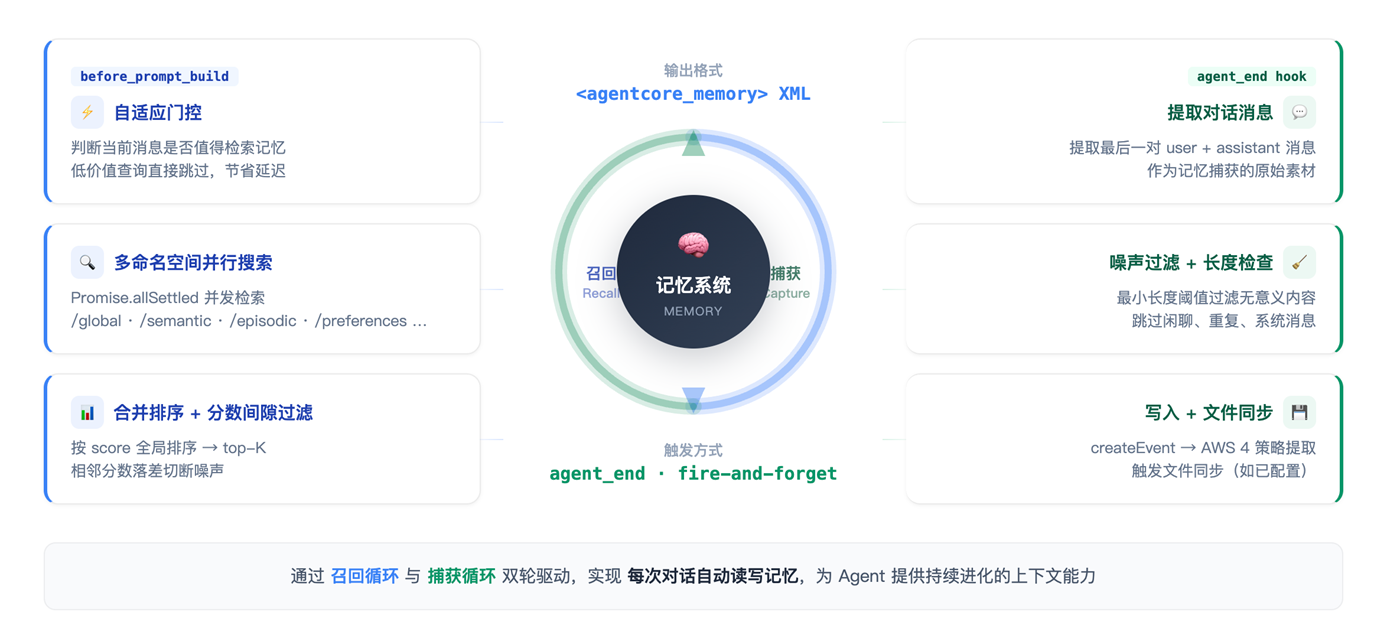
[图5 Auto-Capture 和 Auto-Recall 循环示意] |
两个循环形成闭环:捕获循环将对话沉淀为记忆,召回循环将记忆注入下一次对话。手动工具(store、correct、forget、share)是对这个自动闭环的干预和补充。
7.4 情境记忆与跨会话反思
值得特别提到的是 EPISODIC 策略和 agentcore_episodes 工具。
不同于 SEMANTIC(提取事实)和 USER_PREFERENCE(提取偏好),EPISODIC 策略提取的是结构化经验——“上次遇到这种情况,我们是怎么处理的?结果如何?”
更强大的是 AgentCore Memory支持 reflectionConfiguration——跨会话反思。系统可以自动分析多个 session 中的模式,生成类似“最近大量客户投诉色差问题,可能需要提前提醒颜色比图片更深”的反思性记忆。
这让 Agent 不只是”记住发生了什么”,而是能”从经验中学习”。
八、结语:从”工具”到”同事”
让我们回到小林的故事。在面客模式(dmScope: per-peer)+ memory-agentcore 部署后:
导购和客服共享同一份客户认知——不是因为配置了跨 Agent 共享,而是因为它们服务的是同一个 actorId。记忆的隔离和共享完全由“谁在说话”决定。
8.1 记忆是 Agent 质变的关键
| Agent 状态 | 类比 |
| 没有记忆 | 每天都是新员工 |
| 有本地记忆 | 能记笔记的个人助手 |
| 有共享记忆的 Agent 群 | 有知识管理系统的团队 |
记忆的有无,决定了 Agent 是一个”每次都从零开始的工具”,还是一个”能积累经验、能相互协作的同事”。
8.2 渐进式采用路径
如果你正在考虑为 Agent 团队引入共享记忆,推荐考虑memory-agentcore:
场景1:单 Agent + memory-core → 解决个人记忆,零额外成本
场景 2:+ memory-agentcore(员工助手模式) → 云端持久化 + 4 策略自动提取,跨设备可用
场景3:多 Agent + 命名空间隔离 + 跨 Agent 共享 → 团队记忆,企业级治理
场景 4:面客模式(dmScope: per-peer) → 记忆自动按客户维度隔离,跨 Agent 天然共享,安全两层防线
插件的安装非常简单,复制docs/AGENT-DEPLOY-PROMPT.zh-CN.md中的内容,发送给你自己的OpenClaw Agent,它会自己完成所有的安装工作。安装完成后,OpenClaw Gateway会重启生效。项目中内置了两个Skills,用于测试插件功能是否正常,以及指导更精细配置memory-agentcore插件。 1. 告诉OpenClaw Agent,“运行 agentcore-memory-validation”,此时会自动开始做功能验证,并输出测试总结 2. 需要精细配置,或不知道怎么配置时,“运行 agentcore-memory-guide”,开始提要求即可
结合OpenClaw自身的配置(参考上篇博客),加上合适的插件工具和企业级共享记忆插件,我们能够将“个人助手虾”转变成“客户服务虾”,充分利用OpenClaw Agent的能力为客户服务。
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Bedrock AgentCore — 加快代理投入生产的速度
- Amazon KMS — 托管式密钥管理
- Amazon DynamoDB — 无服务器分布式 NoSQL 数据库
- Amazon IAM — 身份管理和访问权限
相关文章:
- 把 OpenClaw 从个人助手变成客服:一次信任模型的翻转
- 快时尚电商行业智能体设计思路与应用实践(四)借助Amazon AgentCore 实现智能客服 SOP 的可执行 MCP 工具化实践
- Amazon Connect结合Strands框架及Bedrock Agent Core的智能客服机器人解决方案(实践篇)
- 以Kiro快速部署云上Agent:只需几个小时,从业务需求到部署于Amazon Bedrock Agentcore落地
- 基于AgentCore构建自学习、可进化的文旅行业近似信息抽取Agents
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者

亚马逊云科技中国峰会聚焦 AI Agent 的构建与部署实践,现场体验企业级 AI 应用的开发流程。
|
 |
