亚马逊AWS官方博客
如何在亚马逊云科技上构建企业级智能体
摘要:前面两部分我们讨论了 Agent 的开发生命周期,以及评估为什么是一个全新的问题——它既不同于传统软件的单元测试(输入到输出不再是确定性映射),也不同于大模型 benchmark。本章的主线是六个递进的问题:评估框架长什么样 → 该看哪些指标 → 评估流程怎么跑 → 数据集和人怎么进来 → 怎么把它变成工程纪律 → 有什么工具支撑。
目录
一、引言
前面两部分我们讨论了智能体的开发生命周期,以及评估为什么是一个全新的问题——它既不同于传统软件的单元测试(输入到输出不再是确定性映射),也不同于大模型 benchmark。单模型 benchmark 评的是一个 LLM 在孤立 prompt 上的表现,而智能体是一个会自主追逐目标、跨多轮交互做多步推理、调用工具、动态决策的完整系统。传统的 LLM 评估方法把这样的系统当成黑盒,只看最终输出对不对——它能告诉你”结果错了”,却无法告诉你”为什么错”,更无法定位是模型选错了、意图理解偏了、工具调错了、还是记忆检索丢了上下文。那么,当评估真正要落到一个有成百上千个生产级智能体的组织里时,它应该长什么样?这一节我们不谈空泛原则,而是看亚马逊云科技在 Amazon 内部沉淀出来的一套系统化方案。自 2025 年起,Amazon 各业务组织内部已经构建了数千个智能体,覆盖购物、客服、卖家支持等核心场景,从早期实验走向了生产级规模化部署。规模一旦上来,”靠人肉看几条 case 拍脑袋”的评估方式立刻崩溃。更麻烦的是,市面上虽然有不少专用评估工具,但开发者要在它们之间来回切换、再把结果手工汇总,成本极高;而 Strands、LangChain、LangGraph 这些框架虽各自内置了评估模块,却把人锁死在单一框架里。亚马逊云科技由此得出一个明确取向——开发者要的是一套框架无关(framework-agnostic)的评估方法:”Builders want a framework-agnostic evaluation approach rather than being locked into methods within a single framework.” (开发者想要的是一套框架无关的评估方法,而不是被锁死在某个框架自带的评估手段里。)而且,生产级智能体还有一项传统评估很少触及的能力必须被衡量——自反思与错误恢复。一个健壮的智能体必须能识别、分类并从各类失败中恢复:推理模型给出的不当规划、无效的工具调用、格式错误的参数、意料之外的工具返回格式、认证失败、记忆检索错误……评估框架要能度量智能体在遭遇这些异常后,是否还能维持多轮交互的连贯性。再加上生产环境中智能体会随时间出现能力衰退(agent decay),这就要求评估具备近实时的问题检测、告警与处置能力,并辅以 HITL 审计来兜住可靠性。本章的主线是六个递进的问题:评估框架长什么样 → 该看哪些指标 → 评估流程怎么跑 → 数据集和人怎么进来 → 怎么把它变成工程纪律 → 有什么工具支撑。
二、评估框架全景:自动化工作流 + 三层评估库
亚马逊云科技提出了一套整体性 Agentic AI 评估框架(Holistic Agentic AI Evaluation Framework),由两大组件构成:
- 自动化评估工作流(Automated Evaluation Workflow)——把”从拿到 trace 到产出结论”的链路标准化、自动化,让它能跨各种智能体实现复用;
- 智能体评估库(Agent Evaluation Library)——沉淀系统化的度量与指标(其中一个核心子集已产品化为 AgentCore Evaluations 的 14 个内置评估器(),其余面向 Amazon 内部异构场景的扩展指标需通过自定义评估器实现。)。built-in evaluators
工作流我们留到 3.3 节讲,这里先看评估库的核心设计——三层架构。它回答了一个关键问题:评估到底要评智能体的哪些部分?
| 层级 | 评估对象 | 它回答的问题 |
| 底层 Foundation Model | 对多个基础模型做 benchmark | 选哪个模型来驱动 Agent?不同模型对整体质量和延迟有什么影响? |
| 中层 Agent Components | Agent 内部组件:意图识别、多轮对话、记忆、LLM 推理与规划、工具使用 | Agent 是否正确理解了意图?CoT 推理如何驱动规划?工具选择与执行是否对齐了计划?计划有没有成功完成? |
| 上层 End-to-End | Agent 终态:最终响应、任务完成度,以及整体的责任与安全、成本、客户体验影响 | Agent 最终是否达成了用例定义的目标?是否符合责任标准?成本可接受吗? |
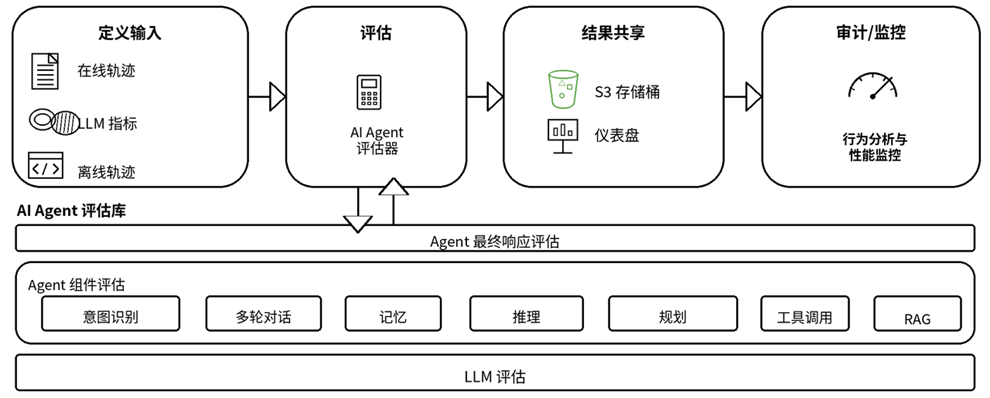
[图1] |
这张图(配图 1:智能体评估库三层架构)值得反复看,因为它点出了智能体评估区别于传统 LLM 评估的核心差异:传统 LLM 评估只看上层。 它把整个智能体当黑盒,丢进去一个问题、接住一个答案,再判断答案好不好。这种方式在智能体出错时几乎无能为力——我们知道结果错了,但定位不到根因。中层才是智能体评估真正的主战场。 一次任务要经过”理解意图 → CoT 规划 → 选工具 → 填参数 → 多轮交互 → 综合记忆”这一长串步骤,任何一环断裂都会导致最终失败。只有把评估拆到组件粒度,才能在出错时快速定位根因,也才能在改一个 prompt、换一个模型后,知道”到底是哪一环变好了或变坏了”。底层则服务于选型:同样一套智能体逻辑,换 Claude Opus 还是 Haiku,质量和延迟会怎么变?这一层把模型作为可量化的变量。
三、关键指标体系:按智能体形态选指标,而不是堆指标
有了三层框架,接下来是具体指标。亚马逊云科技基于 AgentCore Evaluations 的内置评估器,又针对 Amazon 内部异构场景的复杂度做了扩展,沉淀出一套相当完整的指标清单。这里的核心主张是:指标要按智能体的形态来选,而不是无脑全开。 一个纯问答智能体不需要多智能体协作指标,一个工具密集型智能体则必须重点盯工具使用指标。下面按智能体形态分组速查:最终响应质量(Final Response Quality)
- Correctness:响应的事实准确性
- Faithfulness:是否与对话历史保持一致
- Helpfulness:是否真正帮用户推进了目标
- Response Relevance:是否针对具体请求
- Conciseness:表达效率,恰当简洁又不丢关键信息
任务完成(Task Completion)
- Goal Success:是否在一次会话内完成了所有用户目标
- Goal Accuracy:与 ground truth 的对比
工具使用(Tool Use)——工具密集型智能体的命脉
- Tool Selection Accuracy:是否选对了工具
- Tool Parameter Accuracy:调用时是否正确使用了上下文信息填参
- Tool Call Error Rate:调用失败的频率
- Multi-turn Function Calling Accuracy:多个工具是否按正确顺序被调用
记忆(Memory)
- Context Retrieval:从记忆中检索相关上下文的准确性,需在 precision 和 recall 间平衡
多轮对话(Multi-turn)
- Topic Adherence Classification:对话是否守在预定义的领域和话题内
- Topic Adherence Refusal:对超出范围的话题,智能体是否正确拒答
推理(Reasoning)
- Grounding Accuracy:是否理解任务、选对工具,CoT 是否对齐了上下文和工具返回的数据
- Faithfulness Score:推理过程的逻辑一致性
- Context Score:每一步是否上下文有据
责任与安全(Responsibility & Safety)
- Hallucination:输出是否与已知知识、可验证数据、逻辑推断对齐
- Toxicity:是否含有害、冒犯、贬损内容
- Harmfulness:是否含侮辱、仇恨言论、暴力、不当内容、刻板印象
多智能体系统(Multi-Agent System)——前瞻方向
- Planning Score:子任务分配是否成功
- Communication Score:智能体间为完成子任务的通信效率
- Collaboration Success Rate:子任务成功完成的比例
到这里,指标基本都是”技术指标”。但仅有技术指标不够——一个工具选得 100% 准、延迟极低的智能体,如果它推动的业务决策本身是错的,对企业就毫无价值。这正是亚马逊云科技 Prescriptive Guidance 提出决策为先(Decision-First)视角的原因:传统自动化关注”流程效率”——把预设脚本跑得更快更可靠;而 Agentic AI 是”决策为先”——智能体评估上下文、权衡选项、实时调整行为。成功的衡量标准,不再只是任务是否完成,而是决策在多大程度上对齐了意图、政策和不断变化的条件。由此,指标体系顶上要补一组决策为先 KPI:
| 决策为先 KPI | 含义 |
| 决策质量 Decision Quality | Agent 的响应在多大程度上贴合了具体用户和场景?是否做出了对齐业务目标的细致决策? |
| Time-to-Action 响应时效 | Agent 评估情况并做出反应的速度,延迟是否低到让人感觉”自适应、像人”? |
| 认知卸载 Cognitive Offload | Agent 替人类承担了多少手动分析、分流、例行决策?是真减负,还是只是把工作转移了? |
技术指标回答”智能体做得对不对”,决策为先 KPI 回答”智能体做得值不值”。两者必须同时出现在评估面板上。
AgentCore Evaluations 内置一组评估器,按粒度分级,且含两种打分方式(LLM-as-a-Judge + 程序化):
- 会话级 · LLM(1 个):Goal success rate
- 会话级 · 程序化/无 LLM(3 个,ground truth 轨迹匹配):TrajectoryExactOrderMatch、TrajectoryInOrderMatch、TrajectoryAnyOrderMatch
- Trace 级 · LLM(11 个):Coherence、Conciseness、Context relevance、Correctness、Faithfulness、Harmfulness、Helpfulness、Instruction following、Refusal、Response relevance、Stereotyping
- 工具级 · LLM(2 个):Tool selection accuracy、Tool parameter accuracy 其余指标(Topic Adherence、Context Retrieval、Multi-turn Function Calling Accuracy、Planning/Communication/Collaboration Score 等)是 Amazon 内部框架的扩展,需用自定义评估器落地。
AgentCore 自定义评估器分两类
- 1/ LLM-as-a-judge(自定义 judge 模型、指令、打分 schema);
- 2/ Code-based(用你自己的亚马逊云科技 Lambda 函数做确定性检查、正则、外部 API 调用或业务规则,不依赖 LLM judge)。
四、Trace-driven 评估工作流:四步把评估自动化
指标定好了,怎么把它跑起来?亚马逊云科技的做法是把整个评估流程做成一条 trace 驱动的自动化流水线:
1. 第一步——定义输入:spans / traces。三类输入口径不同——On-demand 按 span/trace ID 指定;Batch 指向 CloudWatch Logs 中的会话位置;Online 按采样率或条件过滤从生产流量采样。Traces/spans 完整记录了模型调用、工具调用、推理步骤——它是整个评估的”原材料”。这呼应了 AgentCore Best Practices 的第一条工程原则:从第一天就埋点,AgentCore 各服务会自动发出 OpenTelemetry traces,业务团队无需手工插桩。
2. 第二步——调用评估库。 评估库针对 trace 自动生成默认指标,也支持挂载用户自定义指标。
3. 第三步——结果分发。 评估结果连同 trace 写入 Amazon S3,或在 dashboard 上做 trace 可观测性与评估结果的可视化。
4. 第四步——审计与处置。 通过性能审计与监控分析结果;开发者可自定义规则,在智能体性能下降时触发告警并采取行动;还可用 HITL 机制周期性地人工抽审 trace 子集和评估结果,持续保障智能体质量。
这条流水线背后是一套三层 Observability 策略(与 AgentCore Best Practices 一致),它服务两类不同角色:
- 开发期 / 开发者:trace-level 调试。用户报告异常时,调出那一条具体 trace,逐步还原智能体究竟做了什么——为什么幻觉、哪个 prompt 版本更好、延迟卡在哪一步。
- 生产期 / 平台团队:CloudWatch Generative AI Observability Dashboards 做全局监控,用于治理与成本归因——哪个团队花了多少、哪个智能体在拉高成本、某次事故里到底发生了什么。
- 跟踪的核心信号:token 用量、延迟分位(P50/P95)、错误率、工具调用模式。
值得强调的是,这套体系是开放的:AgentCore 以标准 OpenTelemetry(OTEL) 格式发出 telemetry,可对接任何兼容 OTEL 的可观测平台;官方明确支持 OpenInference、OpenLLMetry、OpenLit、Traceloop 等 instrumentation 库。
“You can’t improve what you can’t measure. Set up your measurement infrastructure before you need it.” (你无法改进你无法度量的东西。在真正需要之前,就把度量基础设施搭好。)
五、评估数据集与 HITL:评估质量的上限由它们决定
再好的工作流,喂进去的数据集不行,结论也不可信。亚马逊云科技的经验里,构建评估数据集有三个反复被强调的要点:
- 同一查询的多种说法——真实用户不会像 API 文档那样标准地提问,”我还剩几天假”和”年假余额”问的是同一件事;
- 应当拒答 / 应当升级的边缘情况——比如 HR智能体遇到”我的奖金为什么比同事少”应该升级到人工,而不是硬答;
- 模糊查询——一个问题有多种合理解释时,智能体该如何处理。
数据集从哪来?Amazon 的两条实战路径很有借鉴价值:
- 从历史交互日志合成(购物助手案例):以真实的历史 API 调用日志为基础构建回归测试集,关键标签经规则校验 / 人工抽检确认;LLM 用于样本扩增与边界 case 生成。真实流量分布是最贴近生产的 ground truth 来源;
- 用 LLM 模拟器生成虚拟用户(客服案例):让大模型扮演多样化的虚拟客户 persona,批量生成贴近真实分布、覆盖长尾的交互——这是低成本扩大评估覆盖面的标配手段。
而 HITL 的真正价值,常被误解。它不是”自动评估兜底的人肉补丁”,它的核心作用是校准评估器本身,尤其在高风险决策场景里不可或缺。HITL 提供:
智能体推理链的评估、多步工作流连贯性的核查、智能体行为与业务需求对齐的判断;
- 为构建黄金测试集提供 ground truth 标签;
- 校准自动评估器里的 LLM-as-a-Judge,让它对齐人类偏好——这一步直接决定了你的自动化指标到底可不可信。
换句话说,HITL 是让自动化评估”可被信任”的那把尺子。
六、工程纪律:把评估嵌入开发流程,而不是上线前跑一次
方法和工具都到位后,最后一道坎是纪律。亚马逊云科技反复强调,评估不是上线前的一次性活动,而是贯穿开发的反馈环。落到实操,有四条核心实践:
1. Holistic 多维评估:评估必须超越传统的准确率指标,覆盖质量、性能、责任、成本四个维度。
- 质量:推理连贯性、工具选择准确率、跨场景的任务完成率;
- 性能:生产负载下的延迟、吞吐、资源利用;
- 责任:安全、毒性、偏见缓解、幻觉检测、护栏,对齐组织政策与合规要求;
- 成本:既算直接成本(模型推理、工具调用、数据处理),也算间接成本(人工投入、纠错补救)。
2. Use case 特定指标:标准指标之外,必须和领域专家协作定义业务指标。比如客服应用要额外跟踪客户满意度、首次接触解决率(first-contact resolution)、情感分析得分。
3. 平衡技术指标与业务指标:延迟和成本,只有在答案正确的前提下才有意义。一个又快又便宜但答错的智能体,技术指标再漂亮也是负价值。
4. 生产环境持续评估:预上线评估永远覆盖不到所有真实场景。生产中要持续监控多样化的用户行为、使用模式和上线前没见过的边缘情况,以发现随时间出现的能力衰退——操作 dashboard 跟踪 KPI、设告警阈值、自动异常检测、建立反馈环,一旦发现问题就触发模型重训、context engineering 修订,并回扣最终业务目标。
这条纪律最具体的体现,是 AgentCore Best Practices 里那个被反复引用的真实 tradeoff 案例:财务分析智能体的基线是 92% 工具选择准确率、3.2s 的 P50 延迟;把模型从 Claude Sonnet 4.5换到 Claude Haiku 4.5后重跑评估,工具选择准确率降到 87%(下降约 5 个百分点),但 P50 延迟改善到 1.8s(提升约 44%)。这笔账值不值得换,必须靠量化评估来决策,而不是凭感觉。同一篇里还给出了财务智能体的一组指标阈值基线,可作为读者设阈值的参照:
| 指标 | 目标阈值 |
| Tool Selection Accuracy | 95% |
| Parameter Extraction Accuracy | 98% |
| Refusal Accuracy | 100% |
| Response Quality | LLM-as-Judge 评判 |
| Latency | P50 < 2s,P95 < 5s |
| Cost per Query | 平均 < 5,000 tokens |
关键论点一句话总结:每一次改动——换 prompt、加工具、换模型——都要重新跑评估。评估是开发流程里持续转动的反馈环,不是发布前打的那一次卡。 反馈环还要足够快,让你当场就能发现问题,而不是三次提交之后才察觉。
这套”改动 → 重跑评估 → 决策”的循环,AgentCore 已产品化为 Optimization(当前为 public preview),它构建在 AgentCore Evaluations 之上,含三项能力:1/ Recommendations——基于真实智能体traces 和一个目标 evaluator,自动产出优化后的 system prompt 或 tool descriptions,并解释改了什么、为什么;2/ Configuration bundles——把配置(system prompt / model ID / tool descriptions)做成版本化、不可变的快照,不改代码即可切换;3/ A/B testing——通过 AgentCore Gateway 把流量在 control/treatment 间切分,由 online evaluation 对每个 session 打分并报告统计显著性,胜出变体接管 100% 流量、其新 trace 成为下一轮起点。
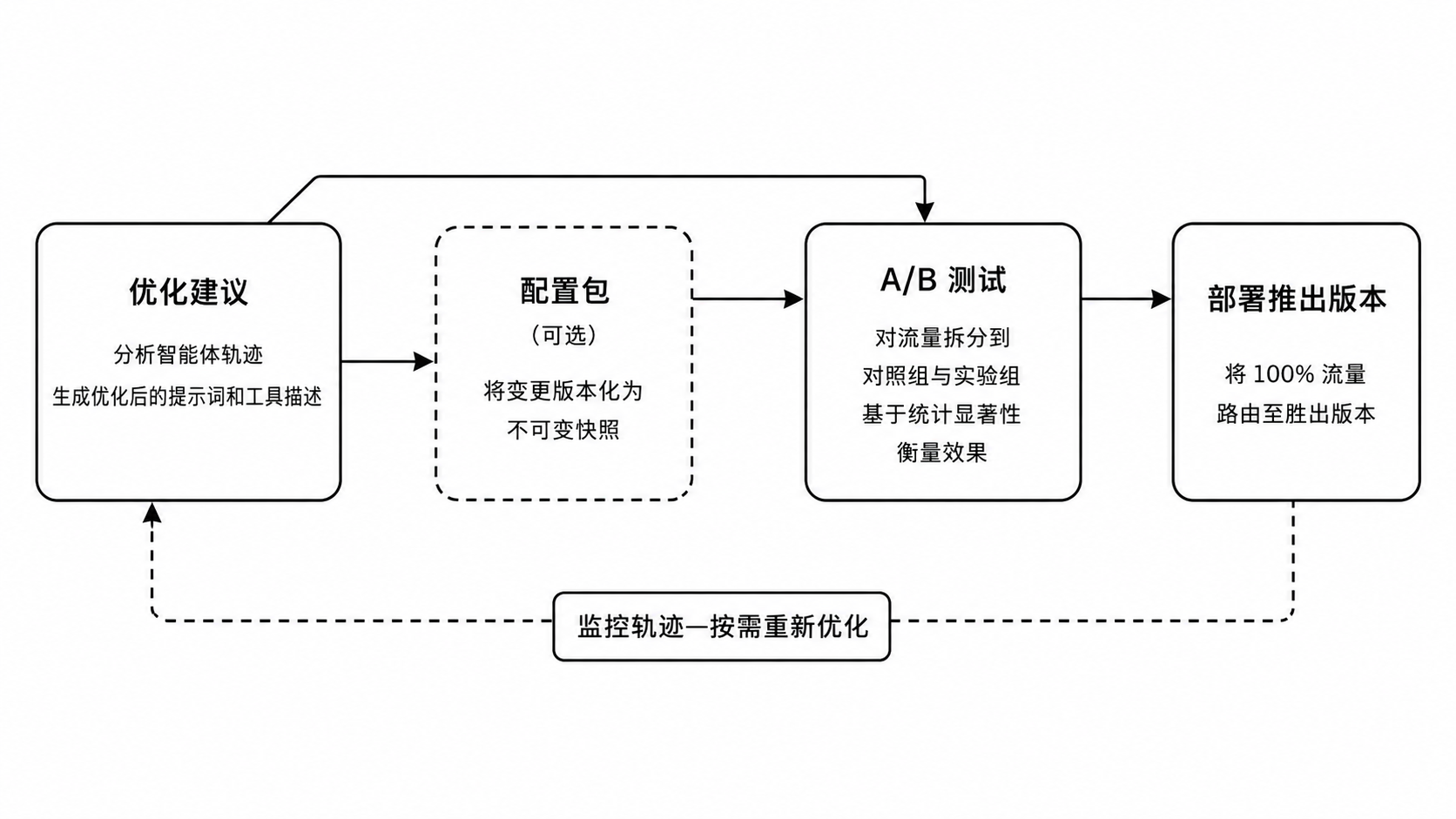
[图2] |
七、工具支持:AgentCore Evaluations
前面讲的方法论,亚马逊云科技把它产品化成了 Amazon Bedrock AgentCore Evaluations,提供三种评估类型,覆盖从开发到生产的不同阶段:
- Online evaluation:对生产流量按采样率(如 10%)或条件过滤规则持续采样打分,结果可在 dashboard 聚合查看、追踪质量趋势,实时捕捉退化。
- On-demand evaluation:按 span / trace ID 评估你指定的交互,提交后服务只处理这些 spans / traces 并返回明细结果,适合开发期调试单条会话、验证修复、定向排查;
- Batch evaluation:对一批已有会话跑异步作业,由服务端完成会话发现、span 采集与打分,你只需指定 CloudWatch Logs 位置;适合基线测量、prompt / 模型改动前后对比、回归测试,以及对某段时间窗内的生产流量做周期性质量审计;
在此之上,AgentCore 还提供两个能力:Dataset evaluation(public preview)让你定义一组场景,自动调用智能体跑出会话、等遥测落地后再评估,相当于一个可复现的测试集——和直接给已有会话打分的 Batch 不同,它会先把会话生成出来;Simulation 则用模拟交互扩大测试覆盖。需要客观比对时,可在评估中附上ground truth(expected responses、assertions、expected tool trajectories)作为标准答案。
评估通过 OpenTelemetry / OpenInference 兼容 Strands、LangGraph 等主流框架——trace 被自动采集、转成统一格式后用 LLM-as-a-Judge 等方式打分;内置评估器开箱即用,覆盖 helpfulness、correctness、faithfulness、goal success rate、harmfulness、tool selection / parameter accuracy 等维度,也支持创建自定义评估器适配领域需求。
放到更大的图景里,Evaluations 只是闭环中的一环——Observability → Evaluation → Optimization:Observability(见 3.3 节)负责”看见”,让 AgentCore 自动发出的 trace 与指标可被采集;Evaluation 负责”判断”,基于这些 trace 打分、定位问题;Optimization(public preview)负责”改进”,它构建在 Evaluations 之上,把评估发现转成可验证的优化——Recommendations 基于真实 trace 和一个目标 evaluator,自动产出优化后的 system prompt 或 tool descriptions;Configuration bundles 把配置做成不改代码即可切换的版本化快照;A/B testing 再通过 AgentCore Gateway 切分流量、由在线评估对每个 session 打分并报告统计显著性。胜出变体接管流量后,其新 trace 又回流到 Observability,开始下一轮——这正呼应 3.5 节:每一次改动都要重新跑评估。
八、实战案例:从工具使用到多智能体协作
理论讲完了,我们来看 Amazon 内部的团队,是怎么把上一节的评估方法论落到真实业务里的。这些 Agentic AI 应用都运行在企业级规模上、部署在亚马逊云科技基础设施之上,已在 Amazon 全球运营的多个实际业务场景中得到验证与落地。下面三个案例分别对应第 3 部分指标体系的不同侧重——从工具使用,到意图识别,再到多智能体协作——恰好覆盖了智能体从简单到复杂的演进路径。最后,我们把这套方法论收束到一个读者可以亲手跑通的 HR 评估 Workshop,形成一个完整的评估闭环。
8.1 案例一:Amazon 购物助手 —— 工具使用评估
业务场景:为了给消费者顺畅的购物体验,Amazon 购物助手需要无缝对接底层系统的成百上千个 API 和 Web 服务——客户画像、商品与库存发现、下单履约——并在此基础上与用户进行长程多轮对话。问题在于:把这么多企业 API 手工 onboarding 成智能体可用的工具,是个极其繁琐的过程,通常要耗费数月。更隐蔽的代价是:把遗留 API 转成智能体工具,需要为每个端点系统性地定义结构化 schema 和语义描述;schema 定义得差、描述不精确,会直接导致运行时选错工具——调用无关 API、无谓撑大上下文窗口、推高推理延迟、靠冗余的 LLM 调用拉高成本。怎么解决,又怎么评估:
- 先治理:Amazon 定义了跨组织的工具 schema 与描述规范,建立一套治理框架,对所有参与工具开发和智能体集成的团队提出强制合规要求——统一工具签名、输入校验 schema、输出契约、人类可读文档的格式,保证全企业范围内工具表示的一致性;
- 再自动化:构建一套 LLM 驱动的 API self-onboarding 系统,自动生成标准化的 tool schema 和描述,把数月的人工 onboarding 压缩成自动流程;
- 最后评估:基于历史 API 调用日志构建回归测试集,并结合规则校验 / 人工抽检确认关键标签;LLM 可用于样本扩增、格式归一和边界 case 生成,针对工具选择与使用做回归测试。
评估关键指标:Tool Selection Accuracy(选对工具)、Tool Parameter Accuracy(用准确的值填参)、Multi-turn Function Calling Accuracy(跨多轮维持连贯的工具调用序列)。读者带走的一句话:工具的 schema 治理是智能体规模化的前提,而评估是这套治理体系的验收手段——随着智能体不断演进,”快速可靠地接入新 API 并评估其工具使用表现”的能力会越来越关键。
8.2 案例二:Amazon 客服智能体—— 意图检测评估
业务场景:客服智能体的第一道关卡是搞清楚”用户到底想干什么”。系统核心是一个编排智能体(Orchestration智能体),用 reasoning model 检测客户意图,再决定把查询路由到哪个由工具或子智能体实现的专精解析器。意图检测的赌注很高:一旦识别错,就会级联出一连串问题——路由到错误的解析器、给出不相关的回答、客户挫败感累积;体验崩塌的同时,更多客户转向人工,运营成本随之上升。怎么解决,又怎么评估:
- 评估数据靠两条腿:用匿名化的历史客户交互构造”用户查询 + 期望意图”的 ground truth 对;再开发一套 LLM Simulator,用 LLM 驱动的虚拟客户 persona 模拟多样化的用户场景与交互;
- 评估时,让编排智能体对模拟数据集里的用户查询生成意图,再把生成意图与 ground truth 意图逐一比对,验证是否一致;
- 除意图正确性外,评估还覆盖任务完成度(智能体的最终响应与意图解决,这是客服任务的终极目标),并为多轮对话加入 Topic Adherence 的分类与拒答指标,保障对话连贯性与体验质量。
评估关键指标:Intent Correctness(意图识别正确率)、Task Completion(任务完成度)、Topic Adherence Classification / Refusal(话题守界与拒答)。读者带走的一句话:用 LLM 模拟器扩展评估覆盖面,是一种 cost-effective 的标配做法——它让你用很低的成本,就把评估集从”历史发生过的”扩展到”真实可能发生的”,而意图检测评估的价值会一路延伸到运营效率和 AI 投资回报率。
8.3 案例三:Amazon 卖家助手 —— 多智能体协作评估
业务场景:企业面对的业务挑战越来越复合——从跨职能工作流编排,到不确定性下的实时决策。Amazon 团队因此越来越多地采用多智能体架构,把单体 AI 方案拆解成一组专精、可协作的智能体,让它们具备分布式推理、动态任务分配与自适应问题求解的能力。卖家助手就是一个典型例子。
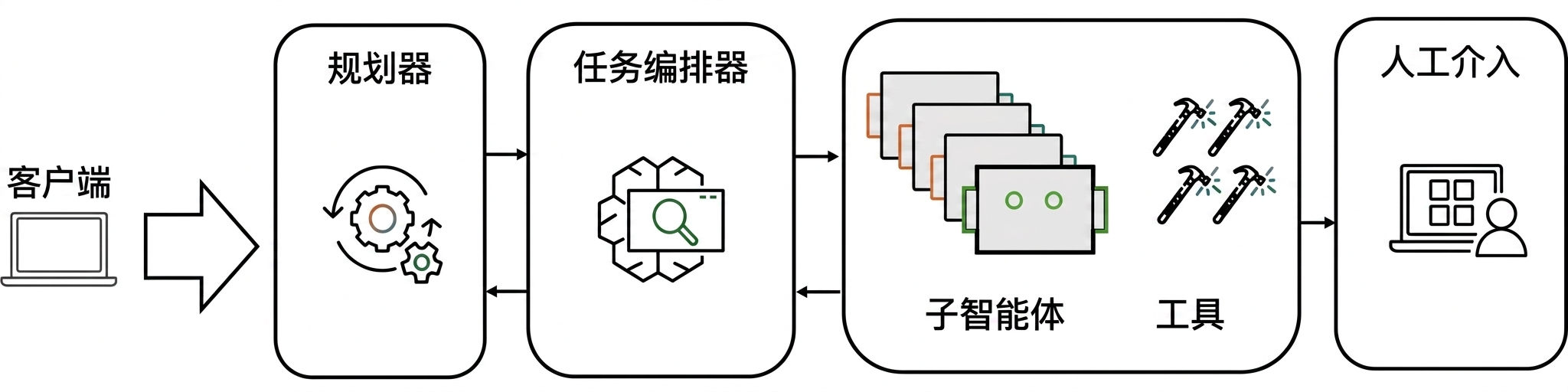
[图3] |
架构(配图 2:多智能体协作架构示意,Planner-Specialist 模式):流程始于一个 LLM Planner & Task Orchestrator,它接收用户请求,把复杂任务拆解成专精子任务,再根据各底层智能体的能力和当前负载,把每个子任务智能分配出去;底层智能体自主执行、用各自的专精工具完成目标,无需编排器持续盯防;完成后向编排器回报状态、确认、中间结果,或在超出边界时发起升级;编排器聚合这些响应、处理子任务间依赖,综合成一个连贯的最终结果。评估的特殊性:多智能体系统的评估必须同时覆盖个体智能体性能和集体系统动态。除了评估各专精智能体在任务完成、推理、工具使用、记忆检索上的质量,还要衡量智能体间的通信模式、协调效率、任务交接准确性。这就用到了第 3 部分提到的那组前瞻指标:
- Planning Score:成功的子任务分配;
- Communication Score:为完成子任务,智能体间的通信消息量;
- Collaboration Success Rate:子任务成功完成的比例。
但更关键的是——自动指标抓不住涌现行为(emergent behavior)。多个智能体交互时可能产生任何单一智能体都不会有的、设计者没预料到的行为模式,这恰恰是风险较高、难以自动检测的部分。所以在多智能体场景里,HITL 不是可选项,而是必选项,它具体承担四项人工指标难以替代的把关职责:
- 评估智能体间通信,识别特定边缘场景下的协调失败;
- 判断智能体专精划分是否合理、任务拆解是否对齐了各智能体的能力;
- 当多个智能体给出相互矛盾的建议时,验证冲突解决策略是否得当;
- 保证多个智能体共同贡献于一个决策时的逻辑一致性,以及集体行为是否服务于既定业务目标。
“In multi-agent systems evaluation, HITL becomes critical because of the increased complexity and potential for unexpected emergent behaviors that automated metrics might fail to capture.” (在多智能体系统评估中,HITL 变得至关重要——因为复杂度的上升,以及自动指标可能捕捉不到的意外涌现行为。)读者带走的一句话:多智能体不是”更多智能体”那么简单,它的评估维度要从单体扩展到协作与涌现,而这些维度恰恰是自动化指标难以量化、却对生产部署成败至关重要的地方。
九、结语:让评估成为智能体工程的默认机制
回顾本系列四篇文章,我们始终围绕一个核心命题展开:企业级智能体的工程化落地,瓶颈不只在模型能力本身,更在于是否具备一套可持续衡量、持续反馈、持续优化的工程体系。
从 Agent Development Lifecycle,到评估方法论、评估粒度和证据权重,再到基于亚马逊云科技服务构建自动化评估工作流,以及 Amazon 内部生产级案例的实践拆解,本系列希望说明的是:评估不应被视为上线前的最后一道检查,而应成为智能体开发全生命周期中的基础能力。
真实业务环境中的智能体系统往往面临更复杂的不确定性:用户意图可能模糊,工具调用可能失败,业务规则和外部知识会持续变化,模型、Prompt、工具链和编排逻辑的任何一次调整,也都可能改变系统行为。因此,企业需要的不只是一次性的测试集或演示效果,而是一套覆盖开发、预上线和生产运行阶段的 Evaluation-first 机制。它既要评估最终答案是否正确,也要观察中间推理、工具调用、责任合规、延迟、成本和用户体验等关键维度。
这也是为什么 Observability、Evaluation 和 Optimization 必须形成闭环。可观测性帮助团队看清智能体真实发生了什么;评估帮助团队判断系统表现是否符合业务目标和风险边界;优化则基于评估结果持续改进 Prompt、模型、工具、知识库和系统架构。随着智能体从单一任务助手演进到工具调用型、多智能体协作型系统,这一闭环会变得更加重要。
同时,自动化评估并不意味着完全替代人工判断。尤其在高风险业务场景、复杂决策流程和多智能体协作场景中,Human-in-the-loop 仍然是校准评估标准、沉淀专家经验、提升自动化评估可信度的重要环节。可靠的企业评估体系,不是“人评”与“自动化评估”的二选一,而是让专家经验能够被结构化、规模化,并持续反哺自动化评估流程。
对于正在规划或已经启动智能体项目的企业团队,现在正是从 Evaluation-first 入手、构建生产级智能体工程体系的合适时机。团队可以从一个高价值但边界清晰的业务场景开始,定义任务目标、评估指标、测试数据和风险边界,并基于 Amazon Bedrock AgentCore 将智能体运行、工具接入、可观测性和评估流程逐步串联起来,在原型阶段就建立可验证、可迭代、可扩展的工程闭环。
面向未来,Agentic AI 的能力边界仍在快速扩展,但企业落地的核心问题会越来越清晰:不是简单地问“这个智能体能不能完成一次任务”,而是要持续追问“它能否在真实业务环境中稳定、可控、可解释、可优化地完成任务”。当评估成为智能体工程的默认机制,企业才能更有信心地将智能体从原型验证推进到生产系统,并在持续变化的业务环境中不断迭代。
如需进一步了解 Evaluation-first 方法在实际场景中的落地方式,可参考本系列配套动手实验示例代码
参考链接:
- AgentCore Evaluations 总览
- How it works(Evaluations)
- Evaluation types(Online/On-demand/Batch)
- Evaluators(built-in + custom)
- Built-in evaluators 总览
- Built-in evaluators prompt templates(14 个清单)
- Custom evaluators(LLM-as-a-judge)
- Custom code-based evaluators(Lambda)
- Online evaluation
- On-demand evaluation
- Batch evaluation
- Dataset evaluation
- Simulation
- Prerequisites(IAM / ADOT)
- Encryption at rest(KMS)
- Optimization 总览(preview 声明)
- Optimization — How it works
- Optimization — Recommendations
- Optimization — Configuration bundles
- Optimization — A/B testing
- Observability 总览
- Observability — 配置/埋点(ADOT/Transaction Search)
- Observability — 服务自带数据(各资源 metrics 表)
- CloudWatch GenAI Observability
进一步阅读:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Bedrock AgentCore — 加快代理投入生产的速度
- Amazon CloudWatch — 可观测性工具
- Amazon Batch — 完全托管式批处理
- AWS Lambda — 无需服务器即可运行代码
系列文章:
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者

2026 亚马逊云科技中国峰会GPU 推理成本分析、Graviton5 架构解读、AI 可观测性专场,一站式解决规模化难题。
|
 |
