亚马逊AWS官方博客
S3 Select 和 Glacier Select – 检索对象子集
Amazon Simple Storage Service (S3) 为每个行业的市场领导者使用的数以百万计的应用程序存储数据。其中许多客户还使用 Amazon Glacier 作为安全、持久且成本极低的存档存储。借助 S3,我可以存储任意数量的对象,单一对象最大可达 5 TB。一直以来,对象存储中的数据都是作为整体访问的,也就是说,当您查询一个大小为 5 GB 的对象时,您会获得全部 5 GB 的数据。这是对象存储的工作方式所决定的。今天,我们将宣布 S3 和 Glacier 的两个新功能挑战这一模式 – 它们让您能够使用简单的 SQL 表达式从这些对象中只提取需要的字节。这可从根本上增强访问 S3 或 Glacier 中对象的每一个应用程序。
S3 Select
S3 Select (随预览版发布) 让应用程序能够使用简单的 SQL 表达式只检索对象的数据子集。使用 S3 Select 仅检索应用程序所需的数据可大幅提升性能 – 在许多情况下,您可获得多达 400% 的性能提升。
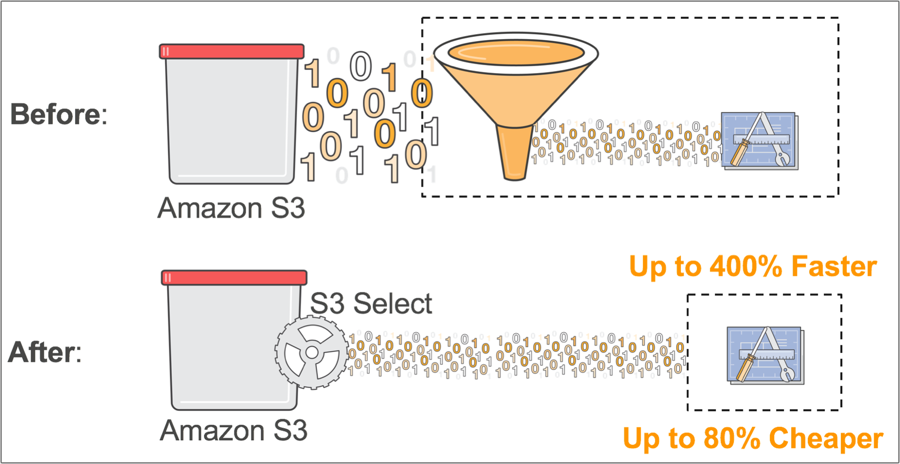
例如,假设您是一家大型零售商的开发人员,您需要分析某个店铺的每周销售数据,但所有 200 家店铺的数据每天都保存在一个新的经过 GZIP 压缩的 CSV 文件中。如果没有 S3 Select,您需要下载、解压缩并处理整个 CSV 才能获得所需的数据。而利用 S3 Select,您可以使用简单的 SQL 表达式仅返回所需的店铺数据,而不必检索整个对象。这可将需要处理的数据量减少一个数量级,从而提高底层应用程序的性能。
我们来看一个简单的 Python 示例。
import boto3
from s3select import ResponseHandler
class PrintingResponseHandler(ResponseHandler):
def handle_records(self, record_data):
print(record_data.decode('utf-8'))
handler = PrintingResponseHandler()
s3 = boto3.client('s3')
response = s3.select_object_content(
Bucket="super-secret-reinvent-stuff",
Key="stuff.csv",
SelectRequest={
'ExpressionType': 'SQL',
'Expression': 'SELECT s._1 FROM S3Object AS s'',
'InputSerialization': {
'CompressionType': 'NONE',
'CSV': {
'FileHeaderInfo': 'IGNORE',
'RecordDelimiter': '\n',
'FieldDelimiter': ',',
}
},
'OutputSerialization': {
'CSV': {
'RecordDelimiter': '\n',
'FieldDelimiter': ',',
}
}
}
)
handler.handle_response(response['Body'])很酷吧!为实现这一行为,S3 Select 使用二进制通信协议返回对象。目前,这需要借助一个小型附加库来帮助处理反序列化。
客户可以利用 S3 Select 加速各类应用程序。例如,这种部分数据检索功能对于使用 AWS Lambda 构建的无服务器应用程序特别有用。我们修改了 Serverless MapReduce 参考架构以使用 S3 Select 仅检索所需数据,结果显示:性能提高了 2 倍,成本则下降了 80%。
S3 Select 团队还创建了一个 Presto 连接器,它能够在不更改查询的情况下立即提高 Amazon EMR 的性能。我们运行了一个对从 S3 检索的接近 99% 的数据进行筛选的复杂查询,借此对连接器进行了测试。在禁用 S3 Select 的情况下,Presto 必须从 S3 扫描和筛选整个对象,而启用 S3 Select 后,Presto 借助 S3 Select 仅检索查询所需的数据。
[hadoop@ip-172-31-19-123 ~]$ time presto-cli --catalog hive --schema default --session hive.s3_optimized_select_enabled=false -f query.sql
"31.965496","127178","5976","70.89902","130147","6996","37.17715","138092","8678","135.49536","103926","11446","82.35177","116816","8484","67.308304","135811","10104"
real 0m35.910s
user 0m2.320s
sys 0m0.124s
[hadoop@ip-172-31-19-123 ~]$ time presto-cli --catalog hive --schema default --session hive.s3_optimized_select_enabled=true -f query.sql
"31.965496","127178","5976","70.89902","130147","6996","37.17715","138092","8678","135.49536","103926","11446","82.35177","116816","8484","67.308304","135811","10104"
real 0m6.566s
user 0m2.136s
sys 0m0.088s不启用 S3 Select 时,此查询耗时 35.9 秒;启用 S3 Select 时,只花费 6.5 秒。速度提高了 5 倍!
需知信息
- 在预览版中,S3 Select 支持使用和未使用 GZIP 压缩的 CSV 及 JSON 文件。预览版不支持静态加密对象。
- 预览版使用期间,S3 Select 不收费。
- Amazon Athena、Amazon Redshift 和 Amazon EMR 以及 Cloudera、DataBricks、Hortonworks 等合作伙伴都将为 S3 Select 提供支持。
Glacier Select
在受到严格监管的金融服务、医疗保健等行业中,一些公司将数据直接写入 Amazon Glacier,以满足 SEC Rule 17a-4、HIPAA 等合规性要求。许多 S3 用户制定了生命周期策略,通过将不再需要定期访问的数据移入 Glacier 来节省存储成本。大多数传统存档解决方案 (例如本地磁带库) 对数据检索吞吐量有严格限制,不适合进行快速分析或处理。需要用到存储在磁带上的数据时,您可能需要等待数周时间才能得到有用的结果。相比之下,您现在只需数分钟时间就能轻松查询存储在 Glacier 中的冷数据。
这可帮助您从存档数据中发掘大量的全新业务价值。Glacier Select 让您能够使用标准 SQL 语句直接筛选 Glacier 对象。
Glacier Select 的工作方式与任何其他检索作业一样,但它有一组您可在启动作业请求中传入的额外参数。 SelectParameters
下面是一个简单示例:
import boto3
glacier = boto3.client("glacier")
jobParameters = {
"Type": "select", "ArchiveId": "ID",
"Tier": "Expedited",
"SelectParameters": {
"InputSerialization": {"csv": {}},
"ExpressionType": "SQL",
"Expression": "SELECT * FROM archive WHERE _5='498960'",
"OutputSerialization": {
"csv": {}
}
},
"OutputLocation": {
"S3": {"BucketName": "glacier-select-output", "Prefix": "1"}
}
}
glacier.initiate_job(vaultName="reInventSecrets", jobParameters=jobParameters)
需知信息
Glacier Select 已在提供 Glacier 的所有商业区域正式发布。
Glacier 定价包含三个要素:
- 扫描数据量 (GB)
- 返回数据量 (GB)
- Select 请求
每个要素的定价取决于您希望返回结果的速度:加急 (1-5 分钟)、标准 (3-5 小时) 和批量 (5-12 小时)。
2018 年,Athena 将很快通过 Glacier Select 与 Glacier 集成。
希望本文对您利用这些功能增强或构建全新应用程序有所助益。
– Randall