亚马逊AWS官方博客
使用 Amazon Athena 和 Amazon Managed Grafana 直观地呈现 Amazon S3 数据
Grafana 是一个热门的开源分析平台,您可以使用该平台,通过灵活的控制面板创建、浏览和分享数据。其使用案例包括应用程序和物联网设备监控,以及运营和业务数据的可视化等。您可以使用自己的数据集或与行业相关的公开数据集创建控制面板。
2021 年 11 月,AWS 团队与 Grafana Labs 一起宣布推出适用于 Grafana 的 Amazon Athena 数据源插件。该功能使您可以在无服务器交互式查询服务 Amazon Athena 的帮助下,使用存储在 Amazon Simple Storage Service(Amazon S3)存储桶中的数据,在 Grafana 控制面板上直观地呈现信息。此外,您还可以使用 Amazon Managed Grafana(这是一项面向开源 Grafana 和 Enterprise Grafana 的完全托管式服务)预置 Grafana 控制面板。
在这篇文章中,我们将介绍如何在 Amazon Managed Grafana 中创建和配置控制面板,以便使用 Athena 查询存储在 Amazon S3 中的数据。
解决方案概览
下图显示了该解决方案的架构。

该解决方案包括在 Amazon Managed Grafana 中创建的 Grafana 控制面板,其中填入了使用 Athena 查询的数据。Athena 使用标准 SQL 对 Amazon S3 中存储的数据运行查询。Athena 与 AWS Glue Data Catalog 集成,后者是 Amazon S3 中的数据的元数据存储,其中包含表架构等信息。
要实施该解决方案,我们需要完成以下几大步骤:
- 创建和配置 Athena 工作组。
- 在 Athena 中配置数据集。
- 创建和配置 Grafana 工作区。
- 创建 Grafana 控制面板。
创建和配置 Athena 工作组
默认情况下,Amazon Managed Grafana 使用的 AWS Identity and Access Management(IAM)角色附加了 AmazonGrafanaAthenaAccess IAM 策略。此策略授予 Grafana 工作区查询所有 Athena 数据库和表的访问权限。更重要的是,它使服务能够读取已写入 S3 存储桶(前缀为 grafana-athena-query-results-)的数据。为了让 Grafana 能够读取 Athena 查询结果,您有两种选择:
- 创建名为
grafana-athena-query-results-<name>的存储桶,创建一个新的 Athena 工作组,然后将其配置为将查询结果写入存储桶。 - 创建 Grafana 工作区后,创建单独的 IAM 策略,授予 Grafana 工作区 IAM 角色对 Athena 用于输出结果的存储桶的访问权限。本博客中未介绍此选项。有关更多信息,请参阅使用可视化编辑器创建策略和 Amazon Managed Grafana 基于身份的策略示例。
在这篇文章中,我们选择第一个选项。为此,执行以下步骤:
- 创建一个名为
grafana-athena-query-results-<name>的 S3 存储桶。将<name>替换为您选择的唯一名称。 - 在 Athena 控制台上,选择导航窗格中的 Workgroups(工作组)。
- 选择 Create workgroup(创建工作组)。
- 在 Workgroup name(工作组名称)下,输入您选择的唯一名称。
- 对于 Query result configuration(查询结果配置),选择 Browse S3(浏览 S3)。
- 选择您创建的存储桶,然后选择 Choose(选择)。
- 对于 Tags(标签),选择 Add new tag(添加新标签)。
- 添加一个键为
GrafanaDataSource且值为true的标签。 - 选择 Create workgroup(创建工作组)。
请务必添加步骤 7-8 中描述的标签。如果标签不存在,Amazon Managed Grafana 将无法访问工作组。
有关 Athena 查询结果位置的详细信息,请参阅使用查询结果、最近的查询和输出文件。
在 Athena 中配置数据集
在这篇文章中,我们使用了美国国家海洋和大气管理局(NOAA)机构提供的 NOAA 全球历史气候学网络日报(GHCN-D)数据集。Registry of Open Data on AWS(为帮助人们发现和共享数据集而存在的注册表)中提供了数据集。
GHCN-D 数据集包含气象元素,例如日最高和最低气温。它是许多地方的气候记录的组合,有些地方包含超过 175 年的记录。
GHCN-D 数据采用 CSV 格式,存储在公共 S3 存储桶中(s3://noaa-ghcn-pds/)。您可以通过 Athena 访问数据。要开始使用 Athena,您需要创建一个数据库:
- 在 Athena 控制台上,选择导航窗格中的 Query editor(查询编辑器)。
- 从右上角的菜单中选择在上一步中创建的工作组。
- 要创建名为
mydatabase的数据库,请输入以下语句:
- 选择 Run(运行)。
- 从左侧的 Database(数据库)列表中,选择
mydatabase使其成为当前数据库。
现在已经有了数据库,您可以在 AWS Glue Data Catalog 中创建一个表,开始查询 GHCN-D 数据集。
- 在 Athena 查询编辑器中,运行以下查询:
之后,在数据库的表格列表下面应该会显示表 noaa_ghcn_pds。在前面的语句中,我们根据 GHCN-D 数据结构定义列。有关变量和数据结构的完整说明,请参阅数据集的自述文件。
配置数据库和表后,您可以开始对整个数据集运行 SQL 查询。就本文而言,创建包含数据子集的第二个表:位于西班牙马德里市最大的公园之一丽池公园(或简称 El Retiro)的一个气象站的最高温度。该站的标识是 SP000003195,相关元素是 TMAX。
- 在 Athena 控制台上运行以下语句以创建第二个表:
之后,在数据库的表格列表下面应该会显示表 madrid_tmax。请注意,在前面的语句中,温度值除以 10。那是因为温度最初是以十分之一摄氏度记录的。我们还调整了日期格式。这两项调整都使数据的使用更加容易。
与 noaa_ghcn_pds 表不同,madrid_tmax 表没有与原始数据集链接。这意味着其数据不会反映对 GHCN-D 数据集所作的更新。相反,它保留其创建时刻的快照。在某些情况下,这可能并不理想,但在这里是可以接受的。
创建和配置 Grafana 工作区
下一步是预置和配置 Grafana 工作区,并将用户分配到该工作区。
创建您的工作区
在这篇文章中,我们使用 AWS Single Sign-On(AWS SSO)选项来设置用户。如果您已有 Grafana 工作区,则可以跳过此步骤。
- 在 Amazon Managed Grafana 控制台中,选择 Create Workspace(创建工作区)。
- 为您的工作区取名,也可以选择提供描述。
- 单击 Next(下一步)。
- 选择 AWS IAM Identity Center (successor to AWS SSO) [AWS IAM Identity Center(AWS SSO 的后继产品)]。
- 对于 Permission type(权限类型),选择 Service Managed(管理的服务),然后选择 Next(下一步)。
- 对于 Account access(账户访问权限),请选择 Current account(当前账户)。
- 对于 Data sources(数据源),请选择 Amazon Athena,然后选择 Next(下一步)。
- 查看详细信息并选择 Create workspace(创建工作区)。
这将开始创建 Grafana 工作区。
创建用户并将其分配到工作区
配置的最后一步是创建一个用户来访问 Grafana 控制面板。请完成以下步骤:
- 如果还没有用户,请为 AWS SSO 身份存储创建一个用户。
- 在 Amazon Managed Grafana 控制台中,选择导航窗格中的 All workspaces(所有工作区)。
- 选择您的 Grafana 工作区以打开工作区详细信息。
- 在 Authentication(身份验证)选项卡上,选择 Assign new user or group(分配新用户或组)。
- 选择您创建的用户,然后选择 Assign users and groups(分配用户和组)。
- 选择用户并在 Action(操作)菜单上选择 Make admin(设为管理员),即可更改用户类型。
创建 Grafana 控制面板
现在,您已经配置了 Athena 和 Amazon Managed Grafana,使用 Athena 利用从 Amazon S3 提取的数据创建一个 Grafana 控制面板。请完成以下步骤:
- 在 Amazon Managed Grafana 控制台中,选择导航窗格中的 All workspaces(所有工作区)。
- 选择 Grafana 工作区 URL 链接。
- 使用在上一步中分配的用户登录。
- 在导航窗格中,选择下部 AWS 图标(有两个图标),然后在 AWS services(AWS 服务)选项卡上选择 Athena。
- 选择之前使用的区域、数据库和工作组,然后选择 Add 1 data source(添加 1 个数据源)。
- 在 Provisioned data sources(预置的数据源)下,选择新创建的数据源上的 Go to settings(转至设置)。
- 选择 Default(默认值),然后选择 Save & test(保存并测试)。
- 在导航窗格中,将鼠标悬停在加号上,然后选择 Dashboard(控制面板)以创建新的控制面板。
- 选择 Add a new panel(添加新面板)。
- 在查询窗格中,输入以下查询:
- 选择 Apply(应用)。
- 在右上角更改时间范围。
例如,如果您更改为 Last 2 years(最近 2 年),则应该会看到类似于以下屏幕截图的内容。
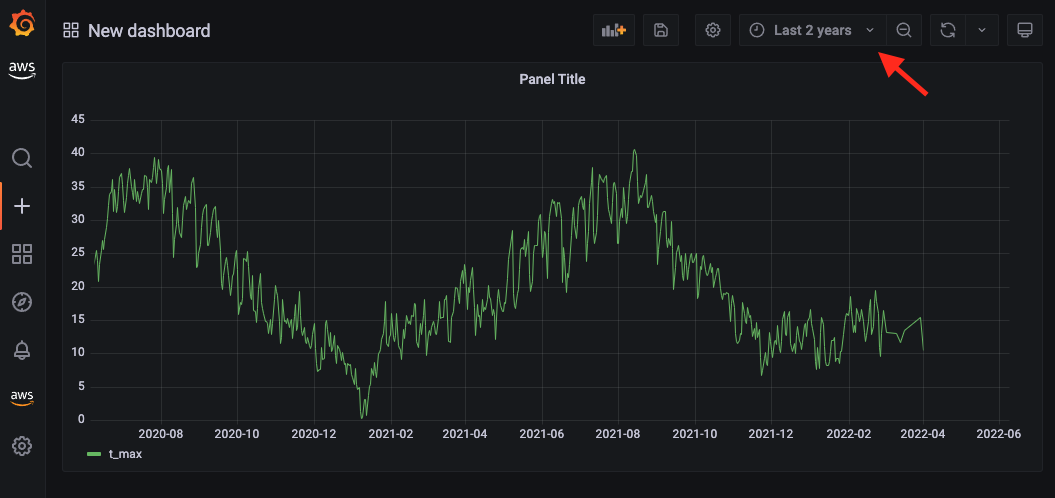
您已经可以通过使用 Athena 从 Amazon S3 提取的数据填充您的 Grafana 控制面板,现在您可以试验不同的可视化和配置。Grafana 提供了许多选项,您可以根据自己的喜好调整控制面板,如以下每日最高温度的示例屏幕截图所示。
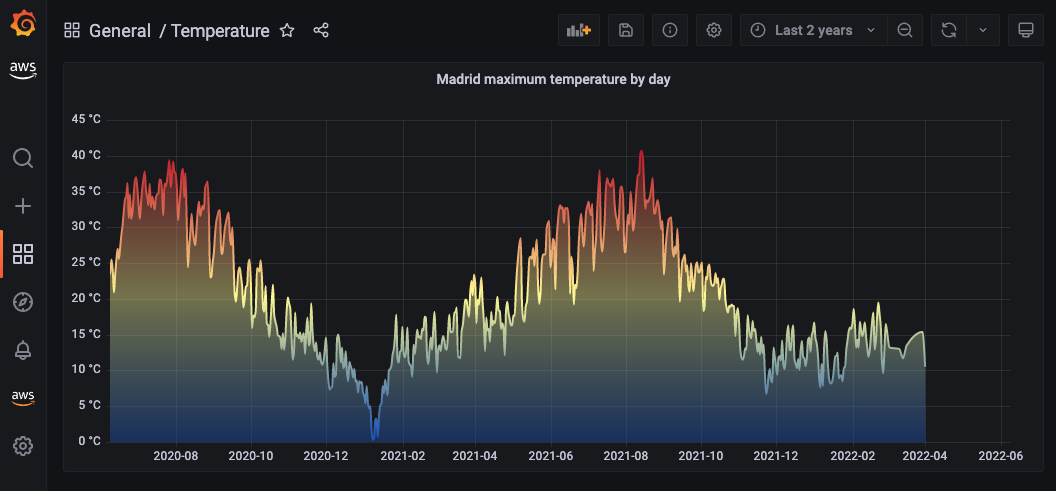
正如您在这个可视化视图中看到的那样,马德里的夏天非常热!
有关如何自定义 Grafana 可视化的详细信息,请参阅可视化面板。
清理
如果您在自己的 AWS 账户中按照这篇文章中的说明进行操作,请不要忘记清理创建的资源,以避免产生其他费用。
结论
在这篇文章中,您学习了如何将 Amazon Managed Grafana 与 Athena 结合使用来查询 S3 存储桶中存储的数据。例如,我们使用了 GHCN-D 数据集在 Registry of Open Data on AWS 中提供的一个子集。
查看 Amazon Managed Grafana,开始使用您自己的数据或存储在 Amazon S3 中的其他公开数据集创建其他控制面板。
关于作者
 Pedro Pimentel 是一名原型设计架构师,在巴西的 AWS 云工程和原型设计团队工作。他与 AWS 客户合作,利用新技术和服务进行创新。在业余时间,Pedro 喜欢旅行和骑自行车。
Pedro Pimentel 是一名原型设计架构师,在巴西的 AWS 云工程和原型设计团队工作。他与 AWS 客户合作,利用新技术和服务进行创新。在业余时间,Pedro 喜欢旅行和骑自行车。
 Rafael Werneck 是一名高级原型设计架构师,在巴西的 AWS 云工程和原型设计团队工作。此前,他曾在 Amazon.com.br 和 Amazon RDS 性能详情部门担任软件开发工程师。
Rafael Werneck 是一名高级原型设计架构师,在巴西的 AWS 云工程和原型设计团队工作。此前,他曾在 Amazon.com.br 和 Amazon RDS 性能详情部门担任软件开发工程师。