Blog de Amazon Web Services (AWS)
Aumentar la interacción con contenido deportivo online personalizado
Este es un post de invitado de Mark Wood en Pulselive. En sus propias palabras, Pulselive, con sede en el Reino Unido, es el orgulloso socio digital de algunos de los nombres más importantes del deporte
En Pulselive, creamos experiencias sin las que los aficionados al deporte no pueden vivir, ya sea el sitio web oficial de la Copa Mundial de Cricket o las aplicaciones iOS y Android de la Premier League inglesa.
Una de las cosas clave en las que nuestros clientes nos miden es la participación de los fans con contenido digital, como los vídeos. Pero hasta hace poco, los vídeos que cada fan veía se basaban en una lista publicada más recientemente, que no estaba personalizada.
Las organizaciones deportivas están tratando de entender quiénes son sus fans y qué quieren. La gran cantidad de datos de comportamiento digital que se pueden recopilar para cada fan cuenta la historia de lo únicos que son y cómo interactúan con nuestro contenido. Basándose en el aumento de los datos disponibles y la creciente presencia del aprendizaje automático (ML), los clientes pidieron a Pulselive que proporcionara recomendaciones de contenido personalizadas.
En este artículo, compartimos nuestra experiencia de añadir Amazon Personalize a nuestra plataforma como nuevo motor de recomendaciones y cómo aumentamos el consumo de vídeo en un 20%.
Implementación de Amazon Personalize
Antes de que pudiéramos empezar, Pulselive tenía dos retos principales: no contábamos con ningún científico de datos en plantilla y necesitábamos encontrar una solución que nuestros ingenieros con una experiencia mínima en aprendizaje automático entendieran y que siguieran produciendo resultados medibles. Consideramos utilizar empresas externas para que nos ayudaran (costosas), utilizando herramientas como Amazon SageMaker (que sigue siendo bastante difícil de aprender a usar) o Amazon Personalize.
En última instancia, decidimos utilizar Amazon Personalize por varias razones:
- La barrera para comenzar era baja, tanto técnica como financieramente.
- Podríamos realizar rápidamente una prueba A/B para demostrar el valor de un motor de recomendaciones.
- Podríamos crear una prueba de concepto simple (PoC) con una interrupción mínima del sitio existente.
- Nos preocupaba más el impacto y la mejora de los resultados que tener una comprensión clara del funcionamiento interno de Amazon Personalize.
Al igual que cualquier otra empresa, no podíamos permitirnos tener un impacto adverso en nuestras operaciones diarias, pero seguíamos necesitando la confianza de que la solución funcionaría para nuestro entorno. Por lo tanto, empezamos con pruebas A/B en un PoC que podíamos poner en marcha y ejecutar en cuestión de días.
Al trabajar con el equipo de creación de prototipos de Amazon, hemos reducido una serie de opciones para nuestra primera integración a una que requeriría cambios mínimos en el sitio web y que se sometiera a pruebas A/B fácilmente. Después de examinar todas las ubicaciones en las que se presenta una lista de vídeos a un usuario, decidimos que cambiar la clasificación de la lista de vídeos a ver a continuación sería lo más rápido para implementar contenido personalizado. Para este prototipo, utilizamos una función de AWS Lambda y Amazon API Gateway para proporcionar una nueva API que interceptaría la solicitud de más vídeos y los reclasificaría mediante la API GetPersonalizedRanking de Amazon Personalize.
Para que se considerara exitoso, el experimento necesitaba demostrar que se habían realizado mejoras estadísticamente significativas en las visualizaciones totales de los vídeos o en el porcentaje de finalización. Para que esto fuera posible, necesitábamos realizar pruebas durante un período de tiempo lo suficientemente largo como para asegurarnos de que cubríamos días con múltiples eventos deportivos y días más tranquilos sin partidos. Esperábamos eliminar cualquier comportamiento que dependiera de la hora del día o de si una partida se había jugado recientemente mediante pruebas con diferentes patrones de uso. Establecemos un plazo de 2 semanas para recopilar los datos iniciales. Todos los usuarios formaron parte del experimento y se asignaron aleatoriamente al grupo de control o al grupo de prueba. Para que el experimento fuera lo más sencillo posible, todos los vídeos formaban parte del experimento. El siguiente diagrama ilustra la arquitectura de nuestra solución.
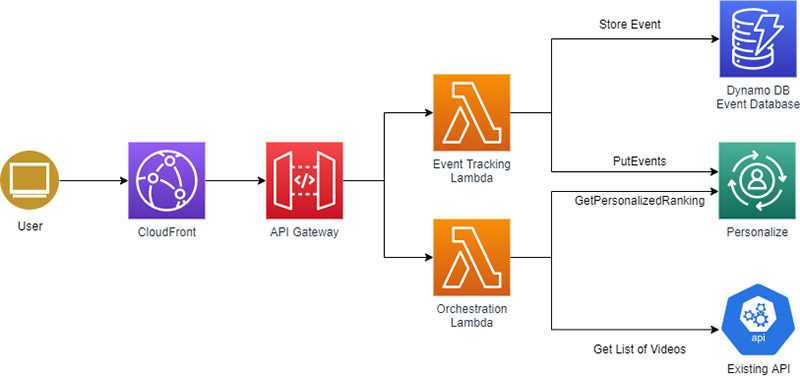
Para empezar, necesitábamos crear una solución de Amazon Personalize que nos proporcionara el punto de partida del experimento. Amazon Personalize requiere un conjunto de datos de interacciones entre elementos de usuario para poder definir una solución y crear una campaña para recomendar vídeos a un usuario. Satisfacemos estos requisitos creando un archivo CSV que contiene una marca de tiempo, un ID de usuario y un ID de vídeo para cada visualización de vídeo durante varias semanas de uso. Cargar el historial de interacciones en Amazon Personalize fue un proceso sencillo y podíamos probar inmediatamente las recomendaciones en la consola de administración de AWS. Para entrenar el modelo, utilizamos un conjunto de datos de 30.000 interacciones recientes.
Para comparar las métricas del total de vídeos visualizados y el porcentaje de finalización de vídeos, creamos una segunda API para registrar todas las interacciones de vídeo en Amazon DynamoDB. Esta segunda API solucionó el problema de informar a Amazon Personalize sobre nuevas interacciones a través de la API PutEvents, lo que ayudó a mantener actualizado el modelo de aprendizaje automático.
Realizamos un seguimiento de todas las visualizaciones de vídeo y lo que provocó visualizaciones de vídeo para todos los usuarios del experimento. Las indicaciones de vídeo incluían enlaces directos (por ejemplo, desde redes sociales), enlaces desde otra parte del sitio web y enlaces de una lista de vídeos. Cada vez que un usuario veía una página de vídeo, se le presentaba la lista actual de vídeos o la nueva lista reclasificada, en función de si estaba en el grupo de control o de prueba. Comenzamos nuestro experimento con el 5% del total de usuarios del grupo de prueba. Cuando nuestro enfoque no mostró problemas (no hubo una caída evidente en el consumo de vídeo ni un aumento de los errores de API), aumentamos esto al 50%, con el resto de los usuarios actuando como grupo de control, y comenzamos a recopilar datos.
Aprender de nuestro experimento
Tras dos semanas de pruebas A/B, extrajimos los KPI que recopilamos de DynamoDB y comparamos las dos variantes que probamos en varios KPI. Hemos optado por utilizar unos cuantos KPI sencillos para este experimento inicial, pero los KPI de otras organizaciones pueden variar.
Nuestro primer KPI fue el número de visualizaciones de vídeo por usuario y sesión. Nuestra hipótesis inicial era que no veríamos cambios significativos dado que íbamos a cambiar la clasificación de una lista de vídeos; sin embargo, medimos un aumento de las visualizaciones por usuario en un 20%. En el siguiente gráfico se resumen las visualizaciones de nuestros vídeos para cada grupo.
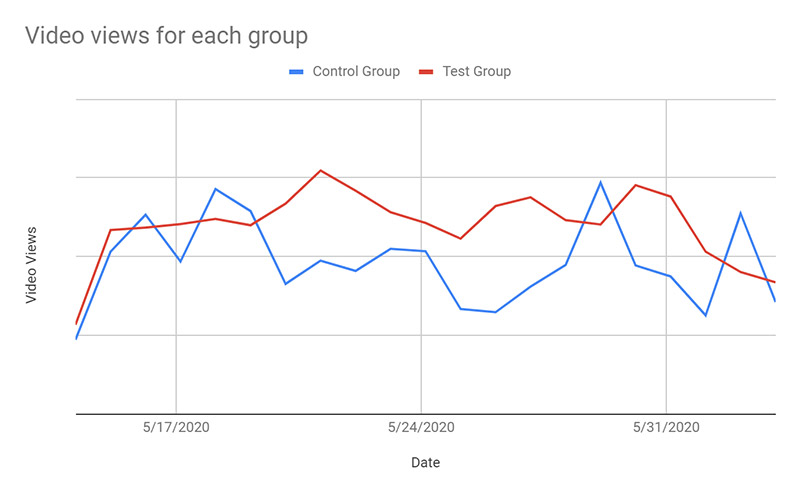
Además de medir el recuento total de visualizaciones, queríamos asegurarnos de que los usuarios veían vídeos completos. Hemos realizado un seguimiento de esto enviando un evento por cada 25% del vídeo que ha visto un usuario. Para cada vídeo, descubrimos que el porcentaje medio de finalización no cambiaba mucho en función de si Amazon Personalize recomendaba el vídeo o la vista de lista original. En combinación con el número de vídeos vistos, llegamos a la conclusión de que el tiempo de visualización general había aumentado para cada usuario cuando se les presentaba una lista personalizada de vídeos recomendados.
También realizamos un seguimiento de la posición de cada vídeo en la barra de «vídeos recomendados» de los usuarios y qué elemento seleccionaron. Esto nos permitió comparar la clasificación de una lista personalizada con una lista ordenada de publicación. Descubrimos que esto no marcaba mucha diferencia entre las dos variantes, lo que sugería que nuestros usuarios probablemente seleccionarían un vídeo que estuviera visible en su pantalla en lugar de desplazarse para ver la lista completa.
Después de analizar los resultados del experimento, se los presentamos al cliente con la recomendación de habilitar Amazon Personalize como método predeterminado para clasificar los vídeos en el futuro.
Lecciones aprendidas
Hemos aprendido las siguientes lecciones en nuestro viaje, que pueden ayudarle a implementar su propia solución:
- Reúne tus datos históricos de las interacciones entre usuarios y elementos; utilizamos unas 30.000 interacciones.
- Céntrate en los datos históricos recientes. Aunque tu posición inmediata es obtener la mayor cantidad de datos históricos que pueda, las interacciones recientes son más valiosas que las interacciones anteriores. Si tienes un conjunto de datos muy grande de interacciones históricas, puedes filtrar las interacciones anteriores para reducir el tamaño del conjunto de datos y el tiempo de formación.
- Asegúrate de que puedes proporcionar a todos los usuarios un identificador único y coherente, ya sea mediante la solución de SSO o generando identificadores de sesión.
- Busca un lugar en tu sitio web o aplicación donde puedas realizar una prueba A/B, ya sea cambiando la clasificación de una lista existente o mostrando una lista de elementos recomendados.
- Actualiza tu API para llamar a Amazon Personalize y obtener la nueva lista de artículos.
- Implementa la prueba A/B y aumenta gradualmente el porcentaje de usuarios en el experimento.
- Instrumenta y mide para que puedas entender el resultado de tu experimento.
Conclusión y pasos futuros
Nos entusiasmó nuestra primera incursión en el mundo del aprendizaje automático con Amazon Personalize. Descubrimos que todo el proceso de integración de un modelo entrenado en nuestro flujo de trabajo era increíblemente sencillo; y dedicamos mucho más tiempo a asegurarnos de tener los KPI y la captura de datos adecuados para demostrar la utilidad del experimento que a la implementación de Amazon Personalize.
En el futuro, desarrollaremos las siguientes mejoras:
- Integración de Amazon Personalize en todo nuestro flujo de trabajo con mucha más frecuencia al proporcionar a nuestros equipos de desarrollo la oportunidad de utilizar Amazon Personalize siempre que se proporcione una lista de contenido.
- Ampliar los casos de uso más allá de la reclasificación para incluir los artículos recomendados. Esto debería permitirnos resaltar artículos antiguos que probablemente sean más populares entre cada usuario.
- Experimentar con la frecuencia con la que se debe volver a entrenar el modelo: insertar nuevas interacciones en el modelo en tiempo real es una excelente manera de mantener las cosas actualizadas, pero los modelos aún necesitan un reentrenamiento diario para ser más efectivos.
- Explorar opciones sobre cómo podemos utilizar Amazon Personalize con todos nuestros clientes para ayudar a mejorar la participación de los fans recomendando el contenido más relevante en todas sus formas.
- Usar filtros de recomendación para ampliar el rango de parámetros disponibles para cada solicitud. Pronto nos centraremos en opciones adicionales, como el filtrado, para incluir vídeos de tus jugadores favoritos.
Este artículo fue traducido automáticamente del Blog de AWS en Inglés.
Sobre el autor
Mark Wood es el director de soluciones de productos de Pulselive. Mark ha trabajado en Pulselive durante más de 6 años y ha ocupado puestos de director técnico e ingeniero de software durante su mandato en la empresa. Antes de trabajar en Pulselive, Mark fue ingeniero sénior en Roke y desarrollador en Querix. Mark se graduó de la Universidad de Southampton con un título en Matemáticas con Ciencias de la Computación.