Blog de Amazon Web Services (AWS)
Explicación de los datos del partido de la Bundesliga xGoals con Amazon SageMaker Clarify
Por Nick McCarthy, científico de datos en AWS,
Luuk Figdor, científico de datos en AWS y
Gabriel Anzer, científico de datos en AWS
Uno de los anuncios más interesantes de AWS re:Invent 2020 fue una nueva función de Amazon SageMaker, diseñada específicamente para ayudar a detectar sesgos en los modelos de aprendizaje automático (ML) y explicar las predicciones de modelos: Amazon SageMaker Clarify. En el mundo actual, en el que los algoritmos de aprendizaje automático a escala hacen predicciones, es cada vez más importante que las grandes empresas de tecnología puedan explicar a sus clientes por qué tomaron una decisión determinada basándose en la predicción de un modelo de aprendizaje automático. De manera crucial, esto puede verse como un alejamiento directo de los modelos subyacentes que son cajas cerradas para las que podemos observar las entradas y salidas, pero no el funcionamiento interno. Esto no solo abre vías de análisis adicionales, a fin de iterar y mejorar aún más las configuraciones de los modelos, sino que también proporciona a los clientes niveles nunca vistos de análisis de predicción de modelos.
Un caso de uso particularmente interesante para Clarify es el de la Deutsche Fußball Liga (DFL) sobre datos de partidos de la Bundesliga con tecnología de AWS, con el objetivo de descubrir información interesante sobre las predicciones del modelo xGoals. La aplicación Datos de partidos de la Bundesliga con tecnología de AWS proporciona una experiencia más atractiva para los aficionados de la Bundesliga durante los partidos de fútbol de todo el mundo. Ofrece a los espectadores información sobre la dificultad de un tiro, el rendimiento de sus jugadores favoritos y puede ilustrar las tendencias ofensivas y defensivas de su equipo.
Con Clarify, la DFL ahora puede explicar de forma interactiva cuáles son algunas de las principales características subyacentes a la hora de determinar qué llevó al modelo de ML a predecir un determinado valor de XGoals. Un xGoal (abreviatura de goles esperados) es la probabilidad calculada de que un jugador marque un gol cuando dispara desde cualquier posición del terreno de juego. Conocer las atribuciones de las características respectivas y explicar los resultados ayuda en la depuración del modelo, lo que a su vez da como resultado predicciones de mayor calidad. Quizás lo más importante es que este nivel adicional de transparencia ayuda a generar confianza y confianza en sus modelos de aprendizaje automático, lo que abre innumerables oportunidades de cooperación e innovación en el futuro. Una mejor interpretabilidad conduce a una mejor adopción. Sin más preámbulos, ¡vamos a ver de qué va todo esto!
Datos del partido de la Bundesliga
Datos de partidos de la Bundesliga con tecnología de AWS proporciona estadísticas avanzadas en tiempo real e información detallada, generada en directo a partir de datos oficiales de partidos, para los partidos de la Bundesliga. Las estadísticas se entregan a los espectadores a través de emisoras nacionales e internacionales, así como de las plataformas, canales y aplicaciones de DFL. Gracias a esto, más de 500 millones de aficionados de la Bundesliga en todo el mundo obtienen información más avanzada sobre jugadores, equipos y la liga y se les brinda una experiencia más personalizada y estadísticas de última generación.
Con xGoals de la Bundesliga Match Fact, la DFL puede evaluar la probabilidad de que un jugador marque un gol cuando dispara desde cualquier posición del campo. La probabilidad de gol se calcula en tiempo real para cada disparo para dar a los espectadores una idea de la dificultad de un tiro y la probabilidad de gol. Cuanto mayor sea el valor de xGoals (con todos los valores entre 0 y 1), mayor será la probabilidad de un objetivo. En esta publicación, analizamos más de cerca esta métrica de xGoals, profundizando en el funcionamiento interno del modelo de ML subyacente para determinar por qué hace ciertas predicciones, tanto para los tiros individuales como para los datos de toda la temporada de fútbol.
Preparación y examen de los datos de formación
El modelo XGoals ML de la Bundesliga va más allá de los modelos XGoals anteriores, ya que combina datos de eventos de tiro a portería con datos de alta precisión obtenidos de la tecnología de seguimiento avanzada con una frecuencia de fotogramas de 25 Hz. Con posiciones de balón y jugador en tiempo real, un modelo personalizado puede determinar una serie de características adicionales, como el ángulo de la portería, la distancia de un jugador a la portería, la velocidad del jugador, el número de defensores en la línea de tiro y la cobertura del portero, por nombrar solo algunas. Utilizamos el área bajo la curva ROC (AUC) como métrica objetiva para nuestro trabajo de entrenamiento y entrenamos el modelo xGoals en más de 40.000 tiros históricos a goles en la Bundesliga desde 2017, utilizando el algoritmo XGBoost de Amazon SageMaker. Para obtener más información sobre el proceso de formación de xGoals con el SDK para Python de Amazon SageMaker y la optimización de hiperparámetros XGBoost, consulte La tecnología detrás de la Bundesliga Match Facts xGoals: Cómo el aprendizaje automático está impulsando la información basada en datos en fútbol.
Cuando observamos algunas de las filas del conjunto de datos de entrenamiento original, nos hacemos una idea de los tipos de características con las que nos enfrentamos; una combinación de valores binarios, categóricos y continuos en un gran conjunto de datos de intentos de tiro a puerta. La siguiente captura de pantalla muestra 8 de las 17 funciones utilizadas tanto para la formación de modelos como para el procesamiento de explicaciones.
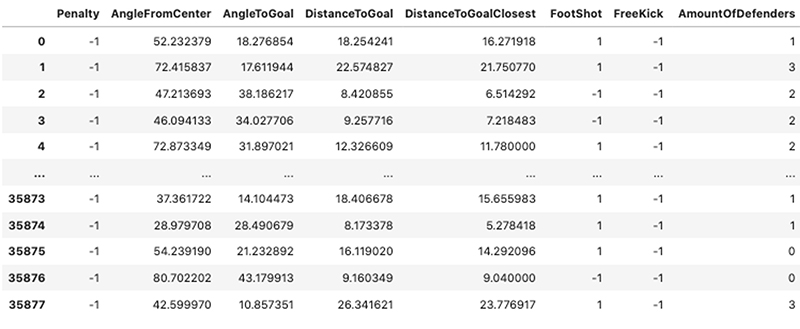
SageMaker Clarify
SageMaker ha sido fundamental para permitir a los científicos de datos novatos y a los académicos experimentados de aprendizaje automático preparar conjuntos de datos, crear y entrenar modelos personalizados y, posteriormente, implementarlos en producción en una amplia gama de sectores verticales, incluidos el sector sanitario, los medios de comunicación y el entretenimiento y las finanzas.
Al igual que la mayoría de las herramientas de aprendizaje automático, faltaba una forma de profundizar y explicar los resultados de dichos modelos o de investigar conjuntos de datos de entrenamiento para detectar posibles sesgos. Todo esto ha cambiado con el anuncio de Clarify, que le ofrece la capacidad de detectar sesgos e implementar la explicabilidad del modelo de forma repetible y escalable.
La falta de explicabilidad a menudo puede crear una barrera para que las organizaciones adopten el aprendizaje automático. Los enfoques teóricos para superar esta falta de explicabilidad del modelo han madurado innegablemente en los últimos años y un marco sobresaliente se ha convertido en una herramienta crucial en el mundo de la IA explicable: SHAP (Shapley Additive Explications). Aunque una explicación completa de este método está fuera del alcance de esta publicación, en esencia SHAP construye explicaciones de modelos planteando la siguiente pregunta: «¿Cómo cambia una predicción cuando se elimina una determinada característica de nuestro modelo?» Los valores SHAP son la respuesta a esta pregunta: calculan directamente la contribución del efecto de una entidad en una predicción tanto en términos de magnitud como de dirección. Con sus raíces en la teoría de juegos de coalición, los valores de SHAP tienen como objetivo caracterizar los valores de las características de una instancia de datos como jugadores de una coalición y, posteriormente, nos indican cómo distribuir equitativamente el desembolso (la predicción) entre las distintas características. Una característica elegante del marco SHAP es que no depende del modelo y es altamente escalable y funciona tanto en modelos lineales simples como en redes neuronales complejas y profundas con cientos de capas.
Explicación del comportamiento del modelo xGoals de la Bundesliga con Clarify
Ahora que hemos introducido nuestro conjunto de datos y la explicabilidad del aprendizaje automático, podemos empezar a inicializar nuestro procesador Clarify, que calcula nuestros valores SHAP deseados. Todos los argumentos de este procesador son genéricos y están relacionados únicamente con su entorno de producción actual y los recursos de AWS a su disposición.
En primer lugar, definamos el trabajo de procesamiento de Clarify, junto con la sesión de SageMaker, el rol de ejecución de AWS Identity and Access Management (IAM) y el bucket de Amazon Simple Storage Service (Amazon S3) con el siguiente código:
Podemos guardar el archivo de formación CSV en Amazon S3 y, a continuación, especificar los datos de formación y la ruta de resultados del trabajo de Clarify de la siguiente manera:
Ahora que hemos creado una instancia del procesador Clarify y definido nuestro conjunto de datos de formación de explicabilidad, podemos empezar a especificar nuestra configuración experimental específica del problema:
Los siguientes son parámetros de entrada importantes a tener en cuenta, como se ve en el fragmento de código pertinente anterior:
- BASELINE: estos puntos de referencia son cruciales para calcular las explicaciones de nuestro modelo. Hay un valor de referencia para cada entidad. Para nuestros experimentos, utilizamos el promedio para las características numéricas continuas y el modo para las características categóricas. Para obtener más información, consultePuntos de referencia de SHAP para la explicación.
- NBR_SAMPLES: número de muestras que se utilizarán en el algoritmo SHAP.
- AGG_METHOD: método de agregación utilizado para calcular los valores SHAP globales, que en nuestro caso es la media de los valores SHAP absolutos para todas las instancias.
- TARGET_NAME: el nombre de la función de destino que el modelo XGBoost subyacente intenta predecir.
- MODEL_NAME: nombre del endpoint del modelo SageMaker XGBoost entrenado (anteriormente).
Pasamos directamente los parámetros importantes a nuestras instancias Clarify.ModelConfig, Clarify.shapConfig y Clarify.DataConfig. Al ejecutar el siguiente código, se pone en marcha el trabajo de procesamiento:
Explicaciones globales
Después de ejecutar nuestro análisis de explicabilidad de Clarify a lo largo de toda nuestra formación de xGoals, podemos ver rápida y fácilmente los valores globales de SHAP y su distribución para cada entidad, lo que nos permite mapear cómo los cambios positivos o negativos en el valor de una característica determinada afectan al final predicción. Utilizamos la biblioteca SHAP de código abierto para trazar los valores SHAP que se calculan dentro de nuestro trabajo de procesamiento.
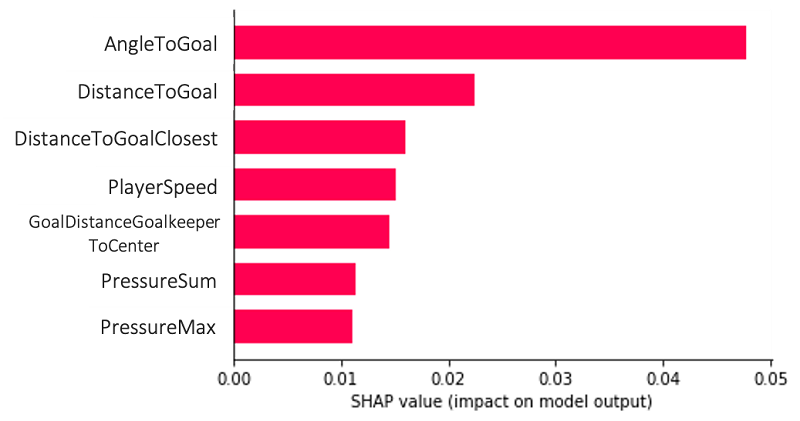
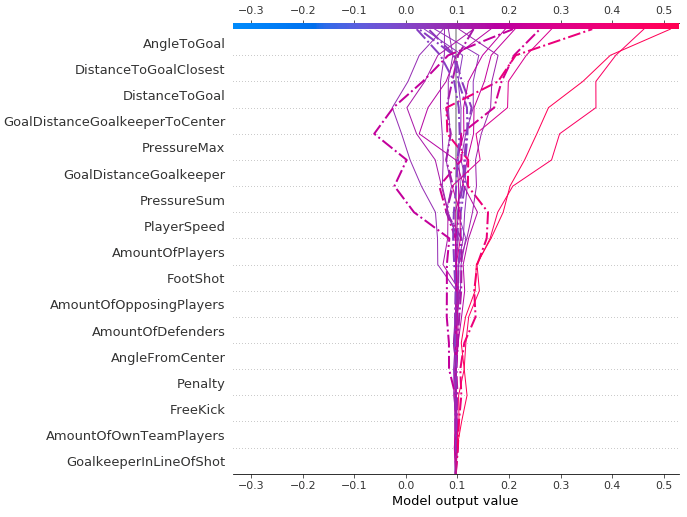
La siguiente gráfica es un ejemplo de explicación global, que nos permite comprender el modelo y sus combinaciones de características en conjunto en varios puntos de datos. Las características AngleToGoal, DistanceToGoal y DistanceToGoalClosest desempeñan los papeles más importantes en la predicción de nuestra variable objetivo, es decir, si se marca un gol o no.
Este tipo de trazado puede ir más allá, ya que nos proporciona más contexto que el gráfico de barras, un mayor nivel de conocimiento de la distribución de valores SHAP para cada entidad (lo que permite mapear cómo los cambios en el valor de una entidad determinada afectan a la predicción final) y las relaciones positivas y negativas del predictores con la variable target. Cada punto de datos de las siguientes gráficas representa un único intento de alcanzar un objetivo.
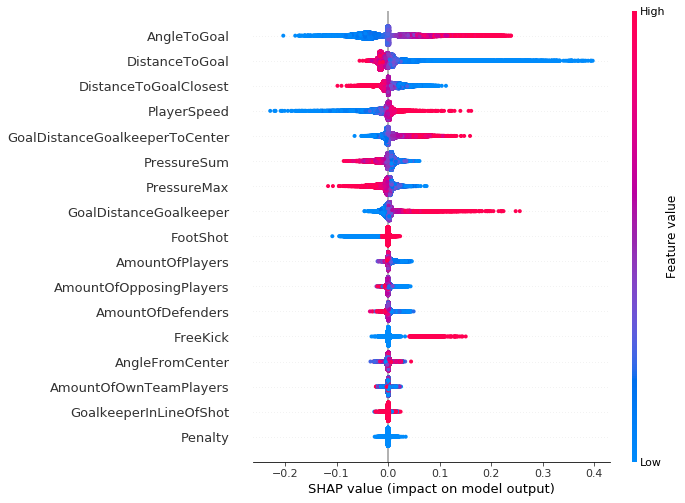
Como sugiere el eje vertical del lado derecho de la gráfica, un punto de datos rojo indica un valor más alto de la entidad y un punto de datos azul indica un valor inferior. El impacto positivo y negativo en el valor de predicción del objetivo se muestra en el eje x, derivado de nuestros valores SHAP. De esto se puede inferir lógicamente, por ejemplo, que un aumento en el ángulo con respecto a la meta genera mayores probabilidades logaríticas para la predicción (lo que se asocia con las predicciones verdaderas para un gol marcado o no).
Vale la pena señalar que para las regiones que tienen una mayor dispersión vertical de los resultados, simplemente tenemos una mayor concentración de puntos de datos que se superponen, lo que nos da una idea de la distribución de los valores de Shapley por entidad.
Las características se ordenan según su importancia, de arriba a abajo. Cuando comparamos esta gráfica a lo largo de las tres temporadas (2017–2018, 2018–2019 y 2019–2020), vemos poco o ningún cambio tanto en la importancia de las características como en su distribución de valores SHAP asociada. Lo mismo ocurre en todos los clubes individuales de la competición de la Bundesliga, con solo un puñado de clubes desviándose de la norma.
Aunque ninguno de nuestros eventos de partido fueron penalizaciones (todos tienen un valor de función = 1), debe incluirse en el trabajo de procesamiento de Clarify porque también se incluyó en la formación del modelo XGBoost original. Necesitamos coherencia entre los dos conjuntos de funciones para la formación de modelos y para el procesamiento de Clarify.
Dependencia de las características de xGoals
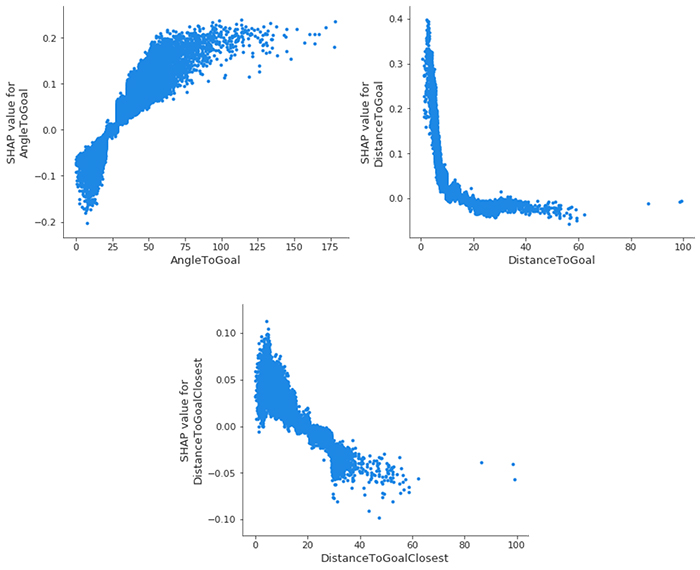
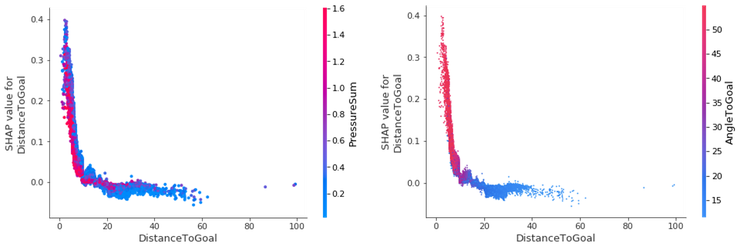
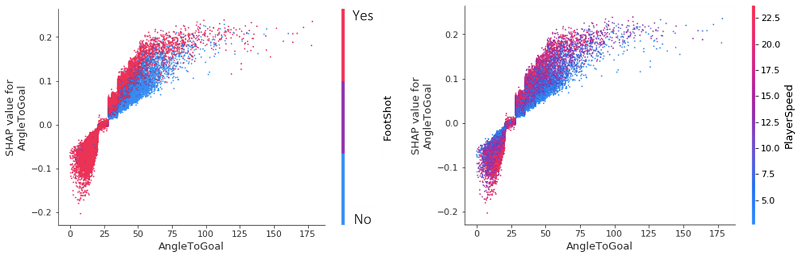
Podemos profundizar aún más y ver las gráficas de dependencia de las características de SHAP, posiblemente la interpretación global más sencilla. Simplemente seleccionamos una entidad y, a continuación, trazamos el valor de la entidad en el eje x y el valor SHAP correspondiente en el eje y. La siguiente gráfica muestra esa relación para nuestras características más importantes:
- AngleToGoal — Los ángulos pequeños (< 25) disminuyen la probabilidad de que haya una meta, mientras que los ángulos más grandes la aumentan.
- DistanceToGoal: hay una caída pronunciada (que imita una función que disminuye logarítmicamente) en la probabilidad de que se produzca un gol a medida que te alejas del centro de la meta. Más allá de cierta distancia, no tiene ningún impacto en el valor de SHAP; en igualdad de condiciones, un disparo desde 20 metros es tan probable que entre 40 metros. Esta observación podría explicarse por el hecho de que los jugadores dentro de este rango solo van a disparar por alguna razón especial que aumentaría sus posibilidades de gol; ya sea que el portero esté fuera de su línea o no haya defensores cerca para cerrar al jugador y bloquear el tiro.
- DistanceToGoalClosest — Como era de esperar, existe una gran correlación aquí con
DistanceToGoal, pero con una relación mucho más lineal: el valor SHAP disminuye monótonamente a medida que aumenta la distancia al punto más cercano de la meta.
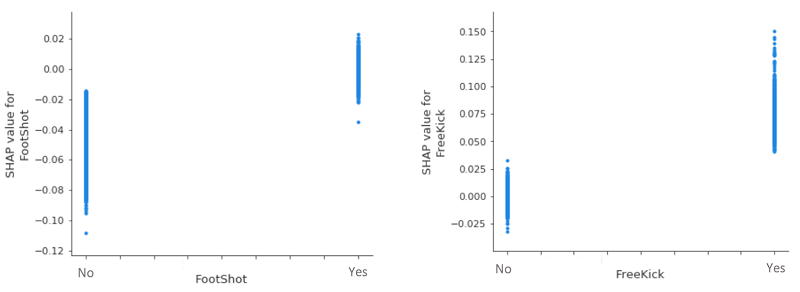
Cuando echamos un vistazo más de cerca a dos de nuestras variables categóricas (menos influyentes), vemos que, en igualdad de condiciones, un cabezazo disminuye invariablemente la probabilidad de un gol, mientras que un tiro libre la aumenta. Dada la dispersión vertical alrededor del valor 0 SHAP para footshot=Yes y FreeKick=No, no hay nada que concluir sobre sus efectos en las predicciones de goles.
Interacción de funciones xGoals
Podemos mejorar las gráficas de dependencia resaltando la interacción entre las diferentes características, el efecto adicional, después de tener en cuenta los efectos de las características individuales. Utilizamos el índice de interacción de Shapley de la teoría de juegos para calcular los valores de interacción SHAP de todas las características para adquirir una matriz por instancia con dimensiones F X F, donde F es el número de características. Con este índice de interacción, podemos colorear la gráfica de dependencia de característica SHAP con la interacción más fuerte.
Por ejemplo, supongamos que queremos saber cómo interactúan las variables DistanceToGoal y PressureSum y el efecto que tienen en el valor SHAP de DistanceToGoal. PressureSum se calcula simplemente sumando todas las presiones individuales de los jugadores rivales en el tirador. Podemos ver una relación negativa entre DistanceToGoal y la variable target, con la probabilidad de que un objetivo aumente a medida que nos acercamos a la meta. Como era de esperar, existe una fuerte relación inversa entre DistanceToGoal y PressureSum para aquellos eventos de partido con una predicción de goles altos; a medida que el primero disminuye, el segundo aumenta.
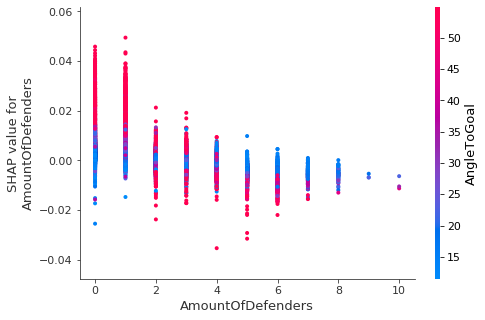
todos los goles que se marcan cerca de la portería se golpean con un ángulo superior a 45 grados. A medida que te alejas de la meta, el ángulo se reduce. Esto tiene sentido; ¿con qué frecuencia ves a alguien marcar un gol desde la banda cuando está a 40 metros de distancia?
Teniendo en cuenta que, basándonos en los resultados anteriores, un ángulo alto a gol aumenta la probabilidad de marcar un gol, podemos observar el valor SHAP del número de defensores y determinar que este solo es el caso cuando solo uno o dos defensores están cerca del atacante.
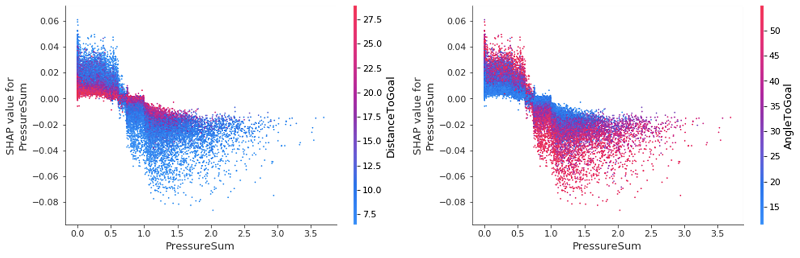
Si observamos detenidamente nuestra gráfica de resumen global inicial, podemos ver cierta incertidumbre (representada por la densa agrupación alrededor de la marca de valor cero de SHAP) para las características PressureSum y PressureMax. Podemos usar gráficas de interacción para profundizar en estos valores e intentar desempaquetar e identificar qué está causando esto.
Tras la inspección vemos que, incluso para las dos características más importantes, tienen un efecto mínimo en el cambio del valor SHAP de PressureSum. La conclusión clave aquí es que cuando un jugador ejerce poca o ninguna presión, una distancia a gol baja aumenta la probabilidad de un gol, mientras que lo contrario es cierto cuando hay mucha presión cerca de la portería: es menos probable que el jugador marque. Estos efectos se invierten de nuevo para AngleToGoal: a medida que aumenta la presión, vemos un aumento de AngleToGoal que disminuye el valor SHAP de pressureSum. Es tranquilizador que nuestras gráficas de interacción con funciones confirmen nuestras ideas preconcebidas del juego, así como cuantifiquen los diversos poderes en juego.
Como era de esperar, se anotaron pocos cabezazos con un ángulo inferior a 25. Sin embargo, lo más interesante es que al comparar los efectos que tiene un cabezazo o un FootShot sobre la probabilidad de que se marque un gol, vemos que para cualquier ángulo en el rango de 25 a 75, un cabezazo lo reduce. Esto se puede simplificar de la siguiente manera: si tu jugador favorito tiene el balón a los pies en un ángulo amplio con respecto a la portería, es más probable que lo marque que si el balón está volando por el aire.
Por el contrario, para ángulos superiores a 25, un jugador que se mueve lentamente hacia la meta reduce la probabilidad de un gol en comparación con un jugador que se mueve a mayor velocidad. Como podemos ver en ambas gráficas, existe una diferencia notable entre el impacto que AngleToGoal < 25 y AngleToGoal > 25 tienen en la predicción de goles. Podemos empezar a ver el valor de usar los valores SHAP para analizar el valor de los datos de las temporadas, porque hemos identificado rápidamente una tendencia universal en los datos.
Explicaciones locales
Hasta el momento, nuestro análisis se ha centrado únicamente en los resultados de explicabilidad de todo el conjunto de datos (explicaciones globales), por lo que ahora exploramos algunos partidos particularmente interesantes y sus eventos de gol, analizando lo que se conoce como explicación local.
Cuando echamos un vistazo a uno de los partidos más interesantes de la temporada 2019-2020, en el que el Bayer 04 Leverkusen venció al Borussia Dortmund en un apasionante 4-3 el 8 de febrero de 2020, podemos ver los efectos variables que cada característica tiene en los valores de los xGoals (el valor de salida del modelo que vemos en el eje horizontal). Vemos cómo, empezando desde abajo y subiendo, las características comienzan a tener un impacto cada vez mayor en la predicción final, con algunos casos extremos que muestran cómo AngleToGoal, DistanceToGoalClosest y DistanceToGoal realmente tienen la última palabra en la predicción de probabilidad de nuestro modelo XGBoost. Las líneas discontinuas son los eventos del partido en los que se ha producido un gol.
Cuando observamos el sexto gol del partido, marcado por Leon Bailey, que el modelo predijo con relativa facilidad, podemos ver que muchos de los valores de las características (clave) superan su promedio y contribuyen a aumentar la probabilidad de un gol, como se refleja en el valor de xGoals relativamente alto de 0,36 en el siguiente diagrama de fuerza.
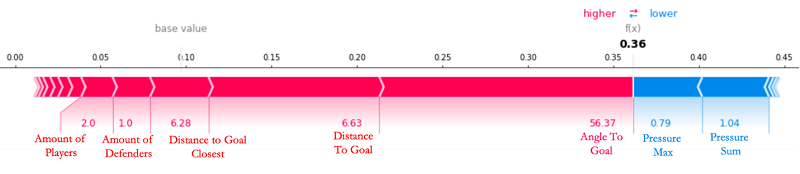
El valor base que vemos es que el valor medio de xGoals en cada intento de tiro en la Bundesliga en las últimas tres temporadas se sitúa en 0.0871. El modelo XGBoost comienza su predicción en esta línea de base, con fuerzas positivas y negativas que aumentan o disminuyen la predicción. En el gráfico, el valor SHAP de una entidad sirve como una flecha que empuja para aumentar (valor positivo) o disminuir (valor negativo) el valor de predicción. En el caso anterior, ninguna de las características es capaz de contrarrestar el alto AngleToGoal (56,37), el bajo amountOfDefenders (1,0) y el DistanceToGoal bajo (6,63) para este tiro a portería. Todas las descripciones cualitativas (como pequeña, baja y grande) guardan relación con los valores medios del conjunto de datos de cada entidad respectiva.
En el otro extremo, hay ciertos objetivos que nuestro modelo XGBoost no puede predecir y los valores de SHAP no pueden explicar. Votado como el mejor gol de la temporada 2019-2020 por el 22 % de los espectadores de la Bundesliga, el asombroso golpe de Emre Can tuvo una probabilidad cercana a cero (3 %) de entrar y, teniendo en cuenta su gran distancia a la portería (aproximadamente 30 metros) y con un ángulo tan plano (11,55 grados), podemos ver por qué. Las únicas características que trabajaron para aumentar sus posibilidades de anotar fueron el hecho de que tenía muy poca presión sobre él en ese momento, con solo dos jugadores en la vecindad local capaces de cerrarlo. Pero esto claramente no fue suficiente para detener a Can. Como siempre ha sido el caso en el fútbol, todos los aspectos de un tiro pueden ser demasiado perfectos para que ningún humano, y mucho menos un modelo avanzado de ML, pueda predecir su resultado.

Echemos un vistazo al objetivo de Can en acción, que cobra vida en animación 2D simplemente utilizando los datos de seguimiento posicional de los jugadores en el momento de la meta.
Conclusión: Implicaciones para la Bundesliga Match Facts
Las principales implicaciones para la Bundesliga Match Facts impulsada por AWS en el futuro son dobles. Los resultados experimentales de este post demuestran que tenemos:
- Comenzó a automatizar el proceso de exploración y análisis de datos de predicción de objetivos a escala, de formas novedosas
- Se ofreció una plataforma de sesgo y explicabilidad del modelo que se puede mejorar para capturar más patrones de toma interesantes y significativos
En escenarios del mundo real tan complejos como un partido de fútbol, los sistemas convencionales o basados en reglas específicas de la lógica comienzan a descomponerse tras la aplicación, y no ofrecen ningún tipo de predicción de eventos de partido y mucho menos una explicación detallada de cómo se hizo. Cuando aplicamos Clarify, podemos mejorar los modelos de predicción de goles y contextualizar los eventos de partidos de fútbol por juego.
A medida que la tecnología de captura de datos futbolísticos ha avanzado drásticamente en los últimos años, también lo han hecho los modelos que podemos usar para modelar esta creciente montaña de datos. A medida que la complejidad, profundidad y riqueza del conjunto de datos de la Bundesliga Match Facts continúa creciendo, el equipo explora continuamente ideas nuevas y emocionantes para obtener datos adicionales sobre los partidos y cómo ajustar nuestros mejores modelos en producción a la luz de resultados explicativos perspicaces. Esto, junto con las inevitables y continuas actualizaciones y mejoras de Clarify, abre una gran cantidad de vías emocionantes para los xGoals y la Bundesliga Match Facts.
Amazon SageMaker Clarify pone el poder de los algoritmos de IA explicables de última generación al alcance de nuestros desarrolladores en cuestión de minutos y se integra perfectamente con el resto de la plataforma digital Match Facts de la Bundesliga, una parte clave de nuestra estrategia a largo plazo de estandarizar nuestros flujos de trabajo de aprendizaje automático en Amazon SageMaker», informa Gabriel Anzer, científico de datos de Sportec Solutions (STS), una organización asociada clave de la Bundesliga Match Facts con tecnología de AWS.
Si esta solución permite a los jugadores de fútbol de fantasía tener ventaja en su liga local, proporciona a los directivos una evaluación objetiva del rendimiento futuro actual (y previsto) de un jugador o sirve como iniciador de conversación para expertos en fútbol notables en la identificación de tendencias ofensivas y defensivas para jugadores y equipos concretos, ya puedes apreciar el valor tangible creado en todas las áreas del ecosistema futbolístico aplicando Clarify a los datos del partido de la Bundesliga.
Este artículo fue traducido automáticamente del Blog de AWS en Inglés.
Sobre los autores
 Nick McCarthy es científico de datos del equipo de servicios profesionales de AWS. Ha trabajado con clientes de AWS de diversos sectores, como la sanidad, las finanzas y el deporte y los medios de comunicación, para acelerar sus resultados empresariales mediante el uso de inteligencia artificial y aprendizaje automático. Aparte de trabajar le encanta viajar, probar nuevas cocinas y leer sobre ciencia y tecnología. La formación de Nick es en Astrofísica y Aprendizaje Automático y, a pesar de seguir ocasionalmente la Bundesliga, ¡ha sido fanático del Manchester United desde muy temprana edad!
Nick McCarthy es científico de datos del equipo de servicios profesionales de AWS. Ha trabajado con clientes de AWS de diversos sectores, como la sanidad, las finanzas y el deporte y los medios de comunicación, para acelerar sus resultados empresariales mediante el uso de inteligencia artificial y aprendizaje automático. Aparte de trabajar le encanta viajar, probar nuevas cocinas y leer sobre ciencia y tecnología. La formación de Nick es en Astrofísica y Aprendizaje Automático y, a pesar de seguir ocasionalmente la Bundesliga, ¡ha sido fanático del Manchester United desde muy temprana edad!
 Luuk Figdor es científico de datos del equipo de servicios profesionales de AWS. Trabaja con clientes de todos los sectores para ayudarles a contar historias con datos mediante el aprendizaje automático. En su tiempo libre le gusta aprender todo sobre la mente y la intersección entre psicología, economía e IA.
Luuk Figdor es científico de datos del equipo de servicios profesionales de AWS. Trabaja con clientes de todos los sectores para ayudarles a contar historias con datos mediante el aprendizaje automático. En su tiempo libre le gusta aprender todo sobre la mente y la intersección entre psicología, economía e IA.
Gabriel Anzer es el científico de datos líder de Sportec Solutions AG, filial de DFL. Trabaja en extraer información interesante de los datos futbolísticos utilizando AI/ML tanto para aficionados como para clubes. Gabriel tiene experiencia en Matemáticas y Aprendizaje Automático, pero además está cursando su doctorado en Analítica Deportiva en la Universidad de Tubinga y está trabajando en su licencia de entrenador de fútbol.