AWS Database Blog
Manage collation changes in PostgreSQL on Amazon Aurora and Amazon RDS
In this post, we explore how text collations work in PostgreSQL, the effect on PostgreSQL when the collation changes, and how to detect these changes. We also review how Amazon Relational Database Service (Amazon RDS) and Amazon Aurora can help you manage collations using an independent default collation library, and future work in PostgreSQL on collation handling.
A fundamental feature in a database is the ability to sort data. For example, an application may need to sort schedule data from the earliest date to the latest or order by a list of names. Ordering numbers have rules determined by mathematical properties, but how does a database decide how to order text? For example, how does a database decide which of these text characters comes first: A, a, or ä? This is where databases rely on collations.
A collation is a set of rules that defines how text is ordered. Collations work alongside character encodings, such as UTF-8, to define how each character should be ordered. Collation rules can vary depending on the locale. For example, in German, the o character is equivalent to ö for ordering, but in Turkish, o and ö are ordered differently. Collations are a fundamental part of computer systems and are included as part of the operating system. In Linux, support for collations most commonly comes from glibc, also known as the standard C library.
In relational databases, collations are used when comparing two strings, such as in a JOIN clause, when there is a text column in an ORDER BY clause, and when building and maintaining indexes over text data. The following example uses PostgreSQL with a German collation (“de_DE“) and a Turkish collation (“tr_TR“) to demonstrate how these two collations treat the o and ö characters differently. Notice how the Turkish collation orders the öb string last in its list:
returns:
and:
returns:
Collations can change over time due to the addition of new characters to languages or modifications to ordering rules. These changes can have consequences that impact the storage of data, particularly around indexes where values may no longer be stored in the expected order.
How collations work in PostgreSQL
PostgreSQL doesn’t provide its own default collation; it uses collation providers. As of this writing, the only two collation providers used with PostgreSQL are glibc and the Internal Components of Unicode (ICU) collations. Historically, PostgreSQL users used the collations provided by glibc because those are the defaults on many UNIX systems. Although initial support for ICU collations was added in PostgreSQL 10, using an ICU collation as the default for a cluster or database wasn’t available until PostgreSQL 15.
When a new PostgreSQL cluster is initialized, it checks the operating system to see what collation providers are available: glibc, ICU, or both. Based on what PostgreSQL finds, it populates a catalog table called pg_collation with the available collations on the operating system. From there, PostgreSQL checks to see if the user specified a default collation to use for the PostgreSQL cluster. This can come from the environmental variables LC_COLLATE and LC_CTYPE, or from passing the arguments --lc-collate and --lc-ctype to initdb (alternatively, these values can be derived from the --locale option). Unless specified differently, any database created within this cluster will use this collation.
Both Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS for PostgreSQL provide glibc and ICU as collation providers. In the PostgreSQL 14.5 release on Amazon Aurora and Amazon RDS, there are over 1,750 collations to choose from! By default, both Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS for PostgreSQL use the glibc en_US.UTF-8 collation, but you can choose to use another available collation. You can see the full list of available collations using the following query:
To get the default collation for the database you are currently connected to, run the following query:
It’s possible to set collations at different levels in PostgreSQL. For example, a PostgreSQL user can configure a database to use a specific collation, or choose to use a specific collation on a column or index. In fact, it’s possible to specify a collation to use on a per-query basis, though this could affect performance based on the size of the dataset and if the collated data exists in an index.
Let’s explore how PostgreSQL uses a collation when building and maintaining an index on a text column. For this exercise, we use a table with the following definition:
Notice that we didn’t specify a collation on the animal_name column, so this will use the default collation for the database. You can verify that animal_name is using the default collation for this database using the following query:
For this example, the collation_name field should be set to default:
Now let’s populate this table with a few animal names. You can do this with the following query:
Create an index on the animal_name column. The following query creates an index named animals_animal_name_idx:
When you run the preceding command, PostgreSQL creates a B-tree index for the values in the animal_name column. Part of building a B-tree index is putting the values in order. To do this for a text column, PostgreSQL uses the collation to determine how to compare and order each character for each text field and uses this to place the values appropriately in the index.
The following query shows you what collation is used for building and maintaining the animals_animal_name_idx index:
In this example, the collation_name field should be set to default:
Again, we didn’t specify a collation to use for this index, so PostgreSQL used the default collation for this database.
Now that we have seen how collations work in PostgreSQL, let’s explore how indexes work with collations.
How B-tree indexes work with collations
This section provides a brief introduction on how B-tree indexes work. This is simplified compared to the PostgreSQL B-tree index implementation. For more details, refer to the PostgreSQL B-tree implementation documentation.
A B-tree index is made up of nodes that are designed to efficiently search for data. Leaf nodes contain the indexed data and are stored in order. Leaf nodes point to adjacent leaf nodes, which helps with performance when retrieving duplicate values, a range of values, or ordering queries that use the index. A B-tree index uses internal nodes to find the values stored in leaf nodes. Internal nodes keep track of the range of values found in its leaf nodes, whether the internal node points to them directly or has them as descendants.
A key property for ordering is immutability. Immutability for determining ordering means a function that determines the order of two values must return the same result when given the same inputs. Immutability in ordering helps both with index maintainability and performance, because it limits the number of updates we need to make to an index when inserting more values and lets us efficiently search over the leaf nodes.
When a B-tree index is built for text data, it relies on a collation to determine how characters are ordered. Let’s see this in action by searching for a text value in a B-tree index. The following figure shows a B-tree index created on a set of animal names. Let’s use this index to find the value of dog.

First, we need to compare dog to elephant. Looking at the collation, we see that d comes before e, as illustrated in the following figure.
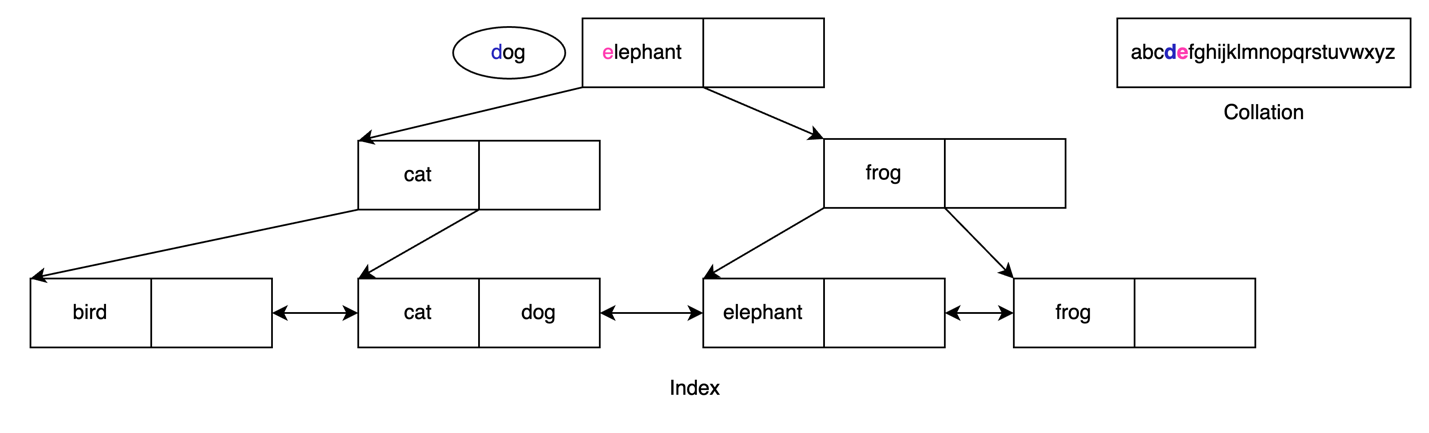
This tells us that we can continue our search for dog on the left side of this B-tree index. The next comparison is between dog and cat. Again, we look at the collation and see that d comes after c, as illustrated in the following figure.

Using this result, we know we can start searching from the leaf node containing cat. We know from the collation that d comes after c, but we do see that there is a value for dog available in this leaf node.

We now continue traversing the leaf nodes until we find no more matching values. In this example, we can see that dog and elephant don’t match, and we can end the search.
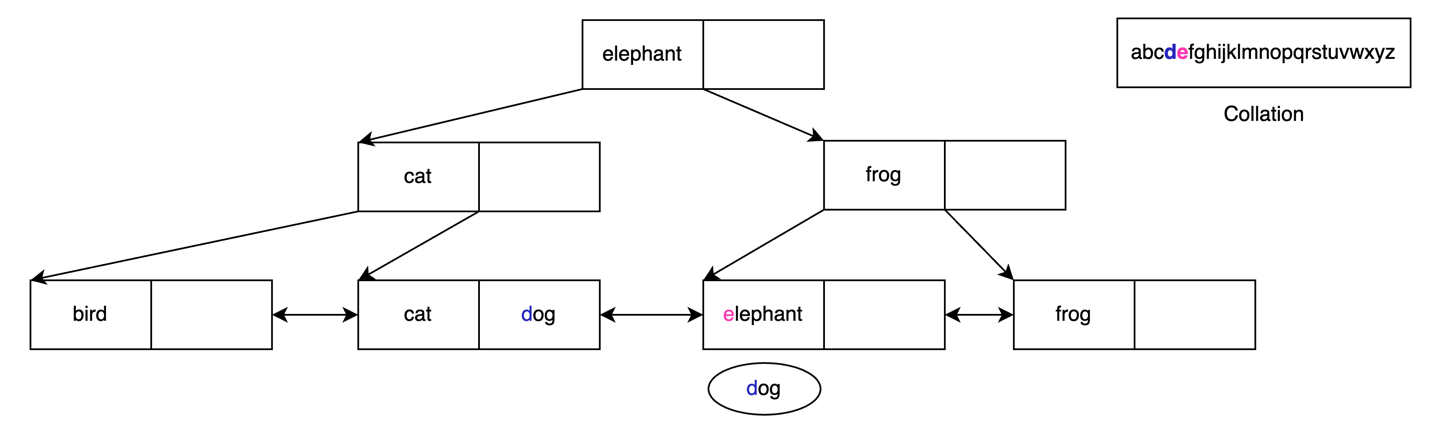
This was a simplified example that demonstrates how to use a collation to search over a B-tree index with text values. Now let’s see what happens if a collation changes while using a built index.
What happens when a collation changes
Recall that B-tree indexes need to use an immutable function to determine how values are ordered. For text data, this means using a collation. But what happens if the ordering changes in a collation?
Using the example from the previous section, the collation library has an update that makes e come before d. What happens if we try to search for dog over the index? As we did in the previous search, we compare dog to elephant.

However, because our collation library says that d comes after e, we must continue the search over the right-hand side of the B-tree. We now must compare dog and frog.

Using the collation library, d still comes before f, so we can continue to the leaf node containing elephant.

However, because of the update to the collation library, e comes before d, so we must continue searching in the next leaf node.
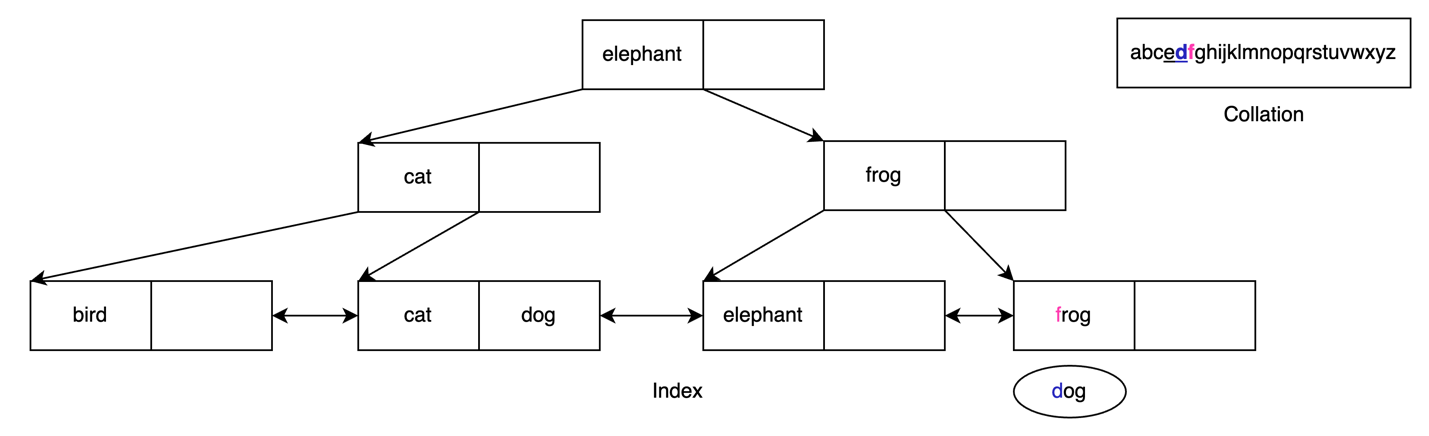
As we saw earlier, d comes before f in this collation, so the search stops and we don’t return any results from this index. This is incorrect: we should have found the value of dog that is stored in this index!
The order in a collation is the immutability function for comparing and sorting strings in an index. This example shows that changes to an in-use collation can cause incorrect results until the index is rebuilt.
Collation changes can occur in PostgreSQL when updating glibc or ICU on the underlying operating system. As of PostgreSQL 15 and earlier versions, PostgreSQL only allows using a single version of a collation provider at a given time. If a new version of a collation provider changes the ordering of characters used in a previously built index, the persisted order in the index may no longer match the order specified by the collation library. You will have to rebuild that index in order to avoid incorrect query results.
Major version updates to glibc often contain updates to existing collations. A known example of collation changes in glibc impacting PostgreSQL is with glibc 2.28. The PostgreSQL community provided documentation that the glibc 2.28 updates contained significant changes to collations and would likely require users to rebuild text indexes.
Now that we have seen how collation changes can impact text data that is indexed in PostgreSQL, let’s learn how to detect collation changes and resolve issues related to them.
Detect and manage collation changes in PostgreSQL
The following example shows how to detect collation version changes from the glibc provider. We chose to use this because it’s the most common collation provider used in PostgreSQL databases on Amazon Aurora and Amazon RDS. You can follow similar steps to detect collation version changes when using ICU.
First, you should determine what version of glibc you’re using on your PostgreSQL instance. Starting with PostgreSQL 13, you can determine this with the following query:
On an Amazon RDS for PostgreSQL instance running PostgreSQL version 14.5, the preceding query returns the following result:
If you believe there were changes to the glibc collation version you’re using, you need to identify the text indexes that use this collation. The following query provides a list of B-tree text indexes that could be impacted by a collation version change:
The following is an example of the output of this query. The output is truncated to show that the animals_animal_name_idx index that was created in the earlier example is included in this list:
At this point, you have a list of indexes that you may need to rebuild. PostgreSQL provides an extension called amcheck and a command line tool called pg_amcheck that can detect if B-tree indexes are impacted by collation version changes. We use the amcheck extension for this example because it’s available in Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS for PostgreSQL. You can add the amcheck extension to your database using the following command:
The following query checks to see if the animals_animal_name_idx index created in the earlier example is impacted by collation version changes:
If the index does have an issue, bt_index_check will throw an error. The following is an example of the type of error you may see if an index is impacted by a collation change:
The previous query may also return empty result, as shown below:
This could mean that the index isn’t impacted by a collation change, but in some cases, the index may have an issue that amcheck is unable to detect. As a precaution, you may still want to consider the index as impacted by the collation change and proceed with the steps below.
Impacted indexes must be rebuilt. You can do this with the REINDEX command. By default, PostgreSQL places locks on a table where the index rebuild is occurring, which can impact performance in a production system. If you’re running PostgreSQL 12 or later, you can use the CONCURRENTLY option when calling REINDEX, which mitigates the availability impact due to locking. However, if the impact of a glibc collation version change to a specific index makes it unusable, for example your queries continuously error or crash, you will have to rebuild the index without the CONCURRENTLY option.
The following query shows how to rebuild the animals_animal_name_idx index created in the earlier example:
This example provides a basic toolkit for detecting changes to a PostgreSQL collation provider, determining which indexes are impacted, and resolving issues related to collation changes. Now let’s learn what Amazon Aurora and Amazon RDS are doing to make it simpler to manage collations.
How Amazon Aurora and Amazon RDS are making it simpler to manage collations
With the Amazon Aurora PostgreSQL-Compatible Edition 14.6, 13.9, 12.13, and 11.18 releases and Amazon RDS for PostgreSQL 14.6, 13.9, 12.13, 11.18, and 10.23 releases, Amazon Aurora and Amazon RDS are introducing an independent default collation library that freezes the glibc collation version at 2.26-59. This is not a freeze of glibc itself — Amazon Aurora and Amazon RDS will continue to update glibc. Collations will remain immutable while glibc will continue to receive security and bug fixes.
If you’re updating to newer versions of Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS for PostgreSQL, in some rare cases you may be impacted by a glibc version change. You can use the preceding guide to determine if you have impacted indexes and rebuild them. Once you’re on the latest versions of Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS for PostgreSQL, your glibc collation version will be frozen at 2.26-59, and you should no longer be impacted by the problem described in this post.
Clean up
If you installed the amcheck extension and no longer need it, you can remove it with the following command:
If you used the example in this post, you can delete the data with the following command:
Conclusion
In this post, we learned how collations are a fundamental component for sorting text data in computers. We also learned how databases use collations and the importance of immutability of collations when using database indexes. We explored how PostgreSQL uses collations, how you can detect changes to a collation, what PostgreSQL indexes may be impacted by collation changes, and how to resolve any issues. Finally, we learned what Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS for PostgreSQL are doing to simplify collation management.
There is ongoing work in the PostgreSQL development community to improve collation management and usage. This includes the ability to use multiple versions of ICU within the same PostgreSQL cluster and support for extensions to manage collation provider versions.
For more information on how to manage your PostgreSQL collations in Amazon Aurora and Amazon RDS, refer to Collations supported in Aurora PostgreSQL.
We invite you to leave feedback in the comments section in this post.
About the Author
 Jonathan Katz is a Principal Product Manager – Technical on the Amazon RDS team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor.
Jonathan Katz is a Principal Product Manager – Technical on the Amazon RDS team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor.